



GPT-4.5, Mistral, Striped Hyena

GPT-4.5
https://x.com/apples_jimmy/status/1732553640215495109
https://x.com/futuristflower/status/1732863849538208101
12월 중에 GPT-4.5가 나온다는 루머가 있습니다. 루머니 맞을 수도 틀릴 수도 있죠. 중요한 건 GPT-5가 준비되는 과정 중에 있다는 사실 자체가 아닐까 싶습니다.
딥마인드도 제미니를 학습시키면서 많은 경험을 얻었을 것이고 개선할 부분도 많이 찾아냈겠죠. 그리고 막대한 TPU v5p와 함께 학습할 다음 모델을 기대할 수밖에 없네요.

Anthropic은 물론이고 Inflection도 GPT-4를 뛰어 넘는 수준의 모델을 지향하고 있을 겁니다. (https://x.com/mustafasuleyman/status/1727348598965501984) 사실 갖고 있는 H100의 숫자를 보면 기대할만한 회사들을 미리 예상할 수 있다고 보이네요. (https://www.theverge.com/2023/12/4/23987953/the-gpu-haves-and-have-nots)
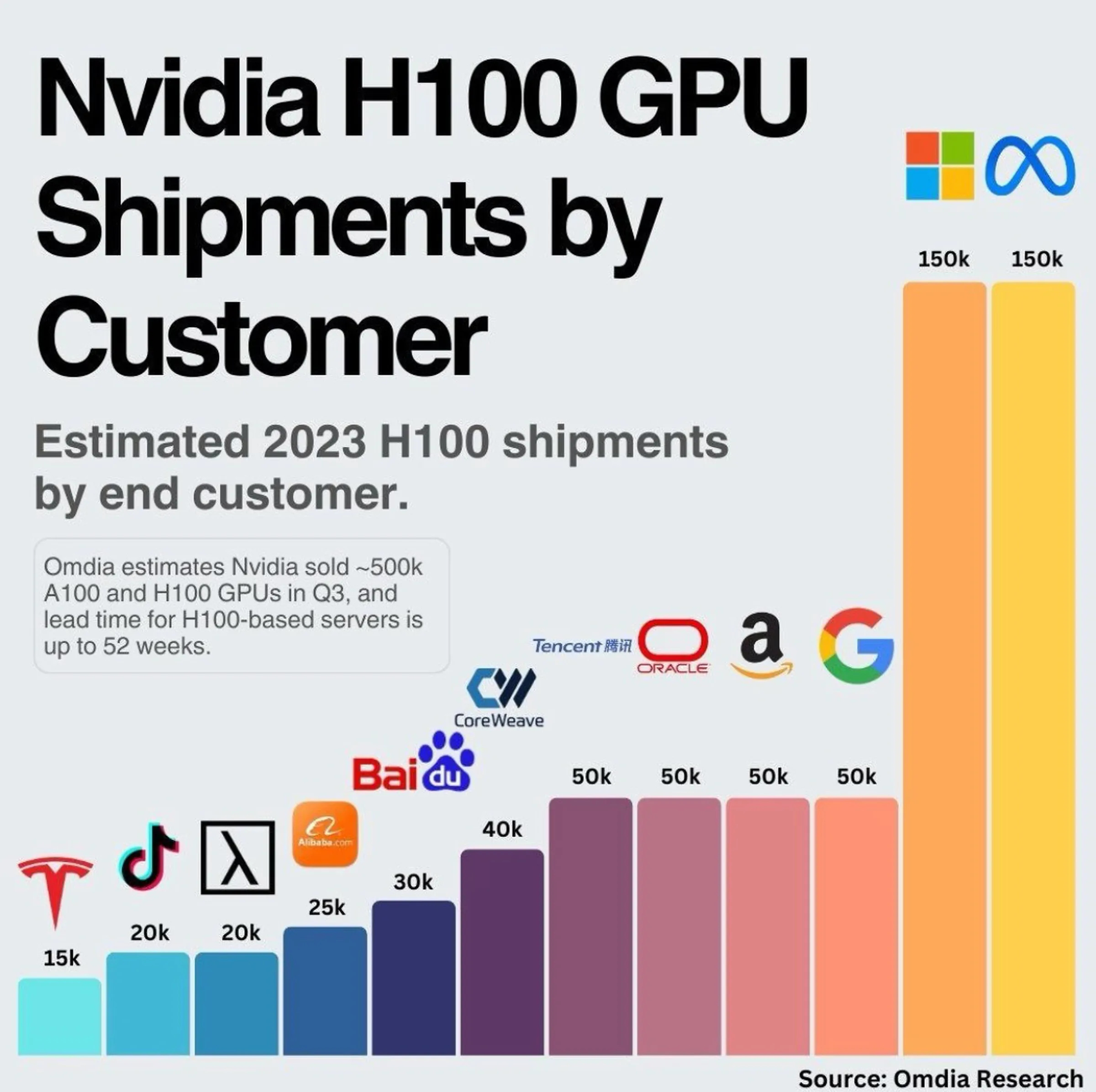
구글, OpenAI, Anthropic, Inflection, 메타 같은 대표 주자들 그리고 (H800의 형태겠지만) 중국의 Tencent, Baidu, Alibaba, Bytedance. 공교롭게도 미국 대 중국의 구도군요. 다만 시간을 고려했을 때 프런티어의 영역에는 지금 GPT-4 수준에 도달한 기업들이 한동안 독점적으로 머물러 있을 가능성이 높지 않을까 싶네요.
지금 같이 더 강력한 모델의 등장과 그 강력한 모델이 세상에 이전과 다른 임팩트를 가질 것이라고 예상하며 기대할 수 있었던 시점이 또 있었을까요? ML을 좋아하는 사람이라면 열광할 수 있는 시대를 마주하고 있는 것 같습니다.
Mistral, Striped Hyena
아침부터 오픈소스 LLM이 두 개 나왔군요. 그것도 아주 중요해 보입니다.
https://x.com/MistralAI/status/1733150512395038967
Mistral은 또 쿨하게 토런트 마그넷을 뿌렸습니다.
https://x.com/karpathy/status/1733181701361451130
뜯어보면 7B 기반으로 8 Top-2 MoE를 한 것 같군요. 토큰 drop 문제를 Block sparse matmul로 해결한 MegaBlocks 기반으로 보입니다. (https://arxiv.org/abs/2211.15841, https://github.com/mistralai/megablocks-public) 구체적인 수치는 나오지 않았지만 애초에 Mistral 7B 자체가 성능이 높았으니 MoE 버전은 말할 것도 없을 듯 싶네요. 컨텍스트도 32K라고 합니다.
물론 MoE는 연산 소모량이 감소하는 대신 메모리는 많이 먹으니 다루기 성가시긴 하겠네요. 그렇지만 그것도 다들 어떻게든 하지 않을까 싶습니다. 사실 모델 사용 자체보다도 제겐 오픈소스 LLM 업계에 MoE의 한 사례가 등장했다는 것 자체가 중요하다고 보입니다.
그리고 또 하나.
https://www.together.ai/blog/stripedhyena-7b
Together AI에서 Hyena Conv 기반 LLM이 등장했습니다. SSM 붐은 왔다! SSM에 기대하는 학습 시 컨텍스트 길이 이상에 대한 일반화가 가능한 것으로 보입니다.
흥미로운 것은 그냥 SSM으로 통일하거나 혹은 트랜스포머를 쓰는 대신 이 둘을 섞었다는 것입니다. 이 둘을 섞었을 때 단일 모듈만 사용하는 것보다 더 나은 Scalability가 나타났다고 보고하고 있습니다. SSM만으로 충분하지 않다면 Attention을 좀 섞으면 되는 문제라는 생각은 했었는데 실제로 그게 통할 수 있다는 것을 보여준 것 같네요. (https://arxiv.org/abs/1911.11423, https://arxiv.org/abs/2105.08050)
여기서 Compute Multiplier에 대해 잠깐 언급해보려 합니다.
https://nonint.com/2023/11/05/compute-multipliers/
Anthropic의 Dario Amodei가 Compute Multiplier라는 단어를 언급하고 있나 보네요. 일단 연산 효율성을 고정된 loss를 목표로 삼아서, 이 loss에 도달하는데 필요한 FLOPs로 정의한다고 해보죠. 그러면 Compute Multiplier는 모든 모델 규모에 대해 연산 효율성을 향상시키는 어떤 방법이라고 할 수 있습니다. 이건 굉장히 중요한 발견입니다. 연산 효율성을 20% 향상시킨다면 GPU가 20%, 분산 처리로 인한 부하를 생각하면 실질적으로는 그 이상 증가한 것과 마찬가지죠.
그리고 Dario는 이 Compute Multiplier가 가장 중요한 산업 기밀이라고 말하고 있네요. 문제는 트랜스포머 이후로 지금까지 딥 러닝 판에서 이런 Compute Multiplier는 거의 발견된 적이 없다는 것이죠. SOTA를 찍을 수 있지만, (모델과 데이터의 규모가 증가했을 때에도) 다른 모델보다 동일 연산에서 더 나은 성능을 보여주거나 혹은 동일한 성능을 더 적은 연산에서 보여주는 경우는 드물죠. (https://arxiv.org/abs/2102.11972, https://arxiv.org/abs/2110.12894)
MoE, 아직 더 검증되어야 할 것 같지만 SSM을 섞는 접근 모두 Compute Multiplier가 될 수 있을 것입니다. 즉 성능 목표에 도달하기 위해 필요한 연산량을 감소시켜 주고 이는 곧 실질적인 GPU의 개수를 증가시키는 효과가 있죠. 반대로 이런 Compute Multiplier를 갖고 있지 않다는 것은 더 많은 비용을 투입해 더 저성능의 모델을 만들게 된다는 것이고 더 나아가 추론 시점에도 더 비싼 비용을 지불해야 한다는 의미가 됩니다.
따라서 Compute Multiplier를 갖고 있다는 것은 현 시점에서 가장 중요한 경쟁력이 될 수 있습니다. 그러나 Compute Multiplier를 발견하려면 또한 그럴 수 있는 수준의 연산 자원이 있어야 하고, 산업 기밀로 여겨지는 상황에서 그에 대한 정보를 얻기도 쉽지 않습니다. 그런 산업 기밀이 오픈소스 업계에서 발견되고 공유된다는 건 그래서 굉장한 일이라고 할 수 있을 겁니다.