

2026-02-25

On Data Engineering for Scaling LLM Terminal Capabilities
(Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, Wei Ping)

Despite rapid recent progress in the terminal capabilities of large language models, the training data strategies behind state-of-the-art terminal agents remain largely undisclosed. We address this gap through a systematic study of data engineering practices for terminal agents, making two key contributions: (1) Terminal-Task-Gen, a lightweight synthetic task generation pipeline that supports seed-based and skill-based task construction, and (2) a comprehensive analysis of data and training strategies, including filtering, curriculum learning, long context training, and scaling behavior. Our pipeline yields Terminal-Corpus, a large-scale open-source dataset for terminal tasks. Using this dataset, we train Nemotron-Terminal, a family of models initialized from Qwen3(8B, 14B, 32B) that achieve substantial gains on Terminal-Bench 2.0: Nemotron-Terminal-8B improves from 2.5% to 13.0% Nemotron-Terminal-14B improves from 4.0% to 20.2%, and Nemotron-Terminal-32B improves from 3.4% to 27.4%, matching the performance of significantly larger models. To accelerate research in this domain, we open-source our model checkpoints and most of our synthetic datasets at https://huggingface.co/collections/nvidia/nemotron-terminal.
Synthetic data for terminal use.
#synthetic-data #agent
Untied Ulysses: Memory-Efficient Context Parallelism via Headwise Chunking
(Ravi Ghadia, Maksim Abraham, Sergei Vorobyov, Max Ryabinin)
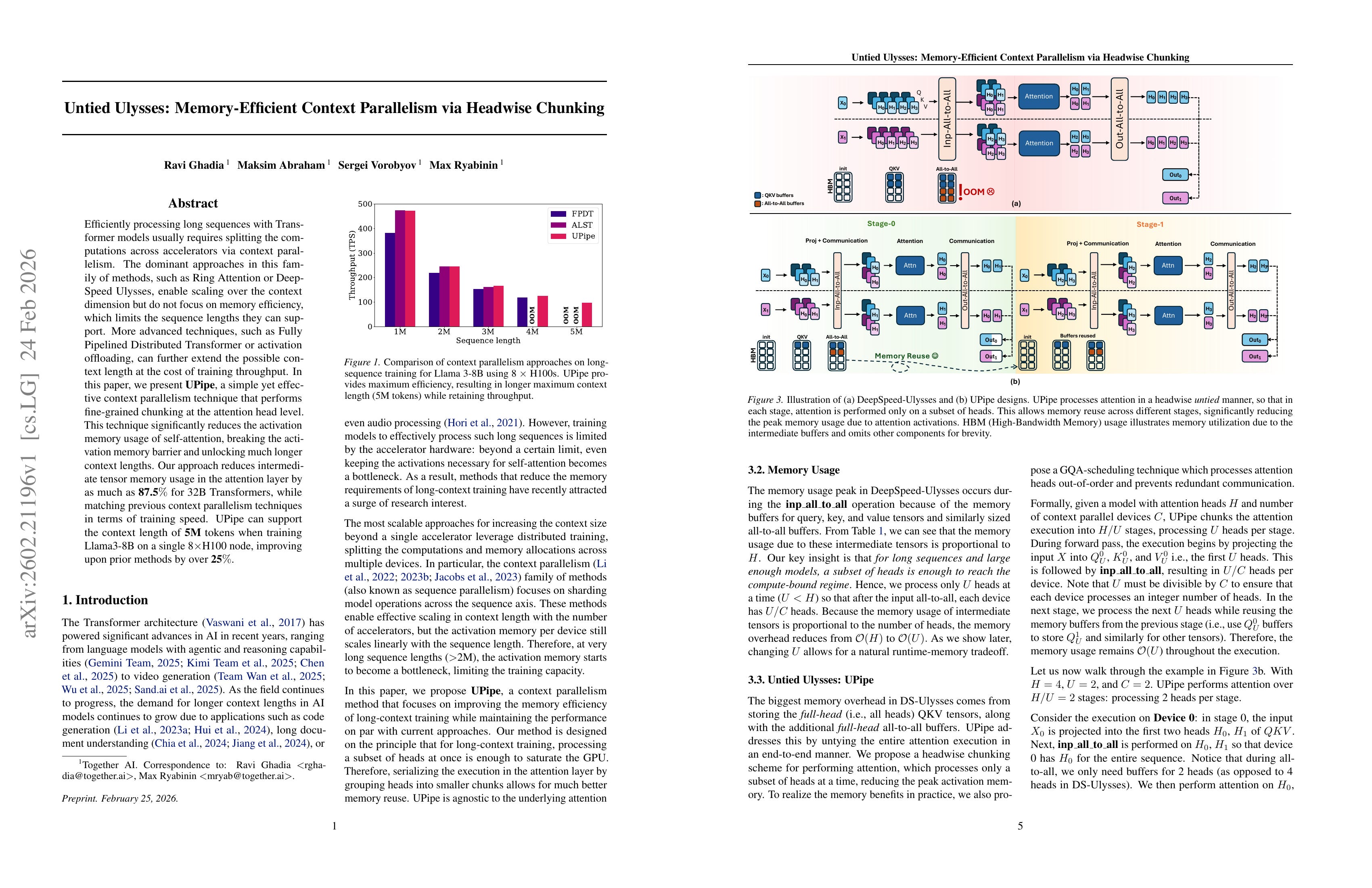
Efficiently processing long sequences with Transformer models usually requires splitting the computations across accelerators via context parallelism. The dominant approaches in this family of methods, such as Ring Attention or DeepSpeed Ulysses, enable scaling over the context dimension but do not focus on memory efficiency, which limits the sequence lengths they can support. More advanced techniques, such as Fully Pipelined Distributed Transformer or activation offloading, can further extend the possible context length at the cost of training throughput. In this paper, we present UPipe, a simple yet effective context parallelism technique that performs fine-grained chunking at the attention head level. This technique significantly reduces the activation memory usage of self-attention, breaking the activation memory barrier and unlocking much longer context lengths. Our approach reduces intermediate tensor memory usage in the attention layer by as much as 87.5% for 32B Transformers, while matching previous context parallelism techniques in terms of training speed. UPipe can support the context length of 5M tokens when training Llama3-8B on a single 8×H100 node, improving upon prior methods by over 25%.
Memory-efficient Ulysses. Compute attention over a subset of heads at a time.
#efficiency #long-context
The Diffusion Duality, Chapter II: Ψ-Samplers and Efficient Curriculum
(Justin Deschenaux, Caglar Gulcehre, Subham Sekhar Sahoo)
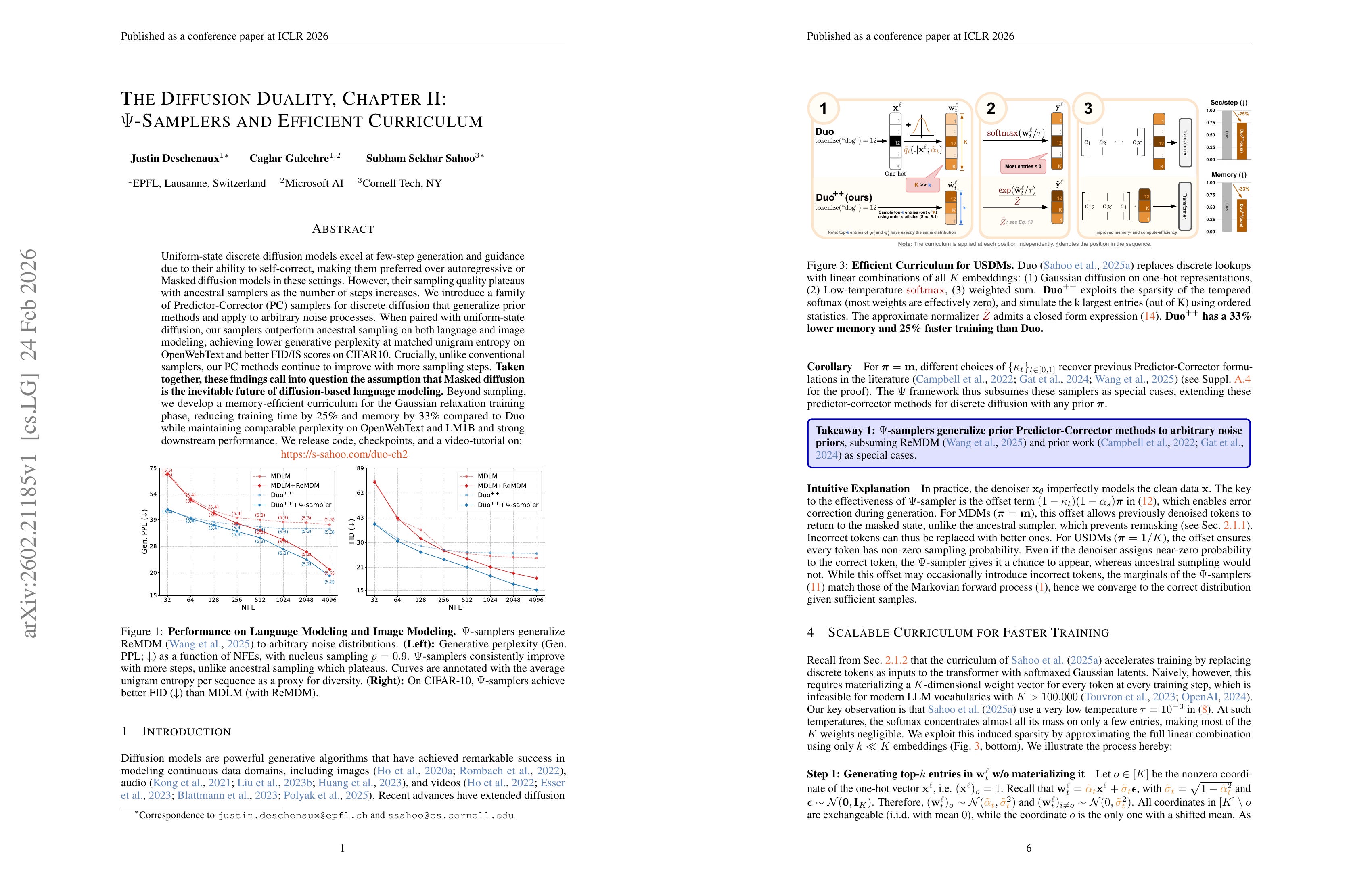
Uniform-state discrete diffusion models excel at few-step generation and guidance due to their ability to self-correct, making them preferred over autoregressive or Masked diffusion models in these settings. However, their sampling quality plateaus with ancestral samplers as the number of steps increases. We introduce a family of Predictor-Corrector (PC) samplers for discrete diffusion that generalize prior methods and apply to arbitrary noise processes. When paired with uniform-state diffusion, our samplers outperform ancestral sampling on both language and image modeling, achieving lower generative perplexity at matched unigram entropy on OpenWebText and better FID/IS scores on CIFAR10. Crucially, unlike conventional samplers, our PC methods continue to improve with more sampling steps. Taken together, these findings call into question the assumption that Masked diffusion is the inevitable future of diffusion-based language modeling. Beyond sampling, we develop a memory-efficient curriculum for the Gaussian relaxation training phase, reducing training time by 25% and memory by 33% compared to Duo while maintaining comparable perplexity on OpenWebText and LM1B and strong downstream performance. We release code, checkpoints, and a video-tutorial on: https://s-sahoo.com/duo-ch2
Generalizing predictor-corrector methods like remasking to make them applicable for uniform-state discrete diffusion.
#diffusion #sampling
The Art of Efficient Reasoning: Data, Reward, and Optimization
(Taiqiang Wu, Zenan Zu, Bo Zhou, Ngai Wong)
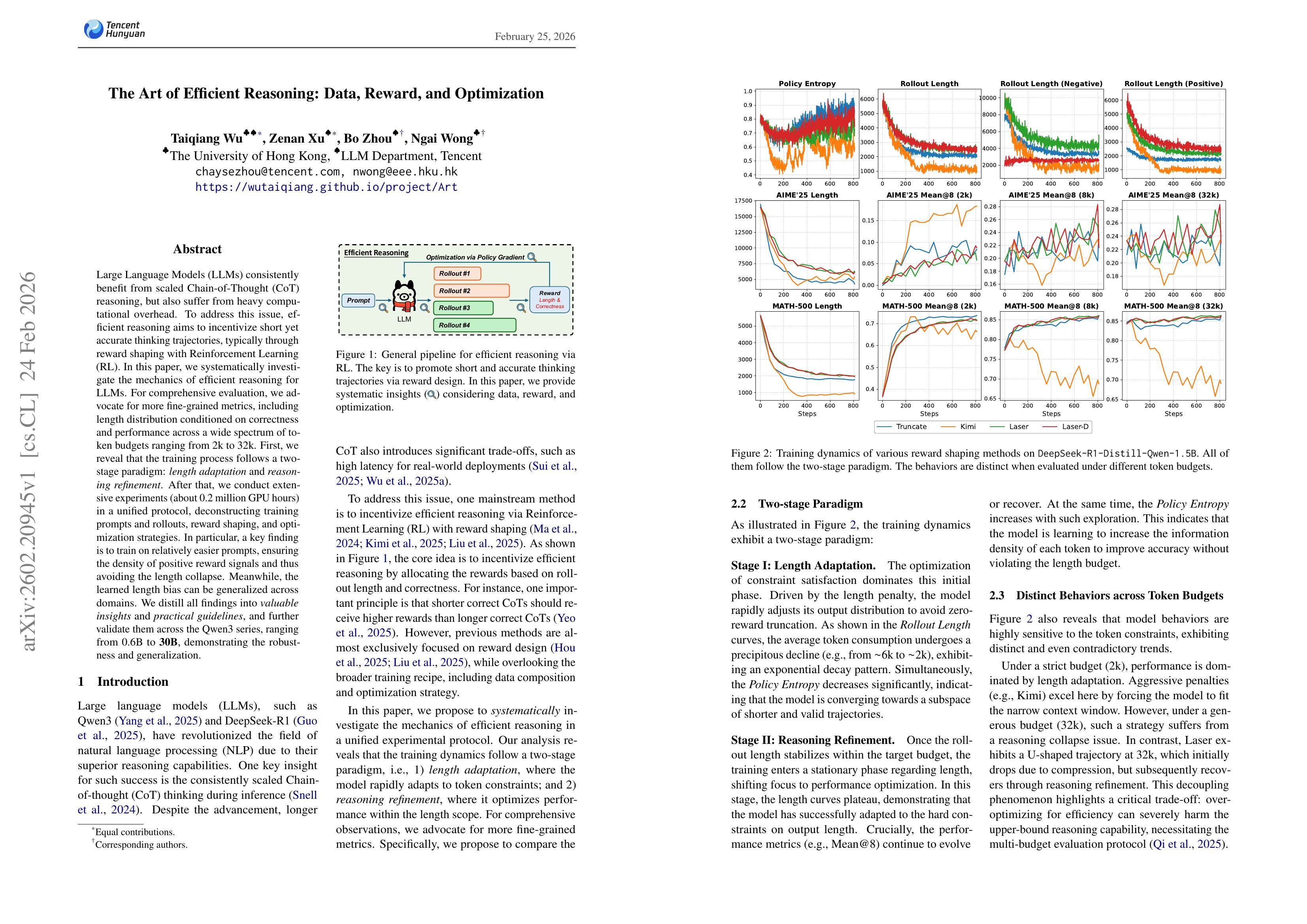
Large Language Models (LLMs) consistently benefit from scaled Chain-of-Thought (CoT) reasoning, but also suffer from heavy computational overhead. To address this issue, efficient reasoning aims to incentivize short yet accurate thinking trajectories, typically through reward shaping with Reinforcement Learning (RL). In this paper, we systematically investigate the mechanics of efficient reasoning for LLMs. For comprehensive evaluation, we advocate for more fine-grained metrics, including length distribution conditioned on correctness and performance across a wide spectrum of token budgets ranging from 2k to 32k. First, we reveal that the training process follows a two-stage paradigm: length adaptation and reasoning refinement. After that, we conduct extensive experiments (about 0.2 million GPU hours) in a unified protocol, deconstructing training prompts and rollouts, reward shaping, and optimization strategies. In particular, a key finding is to train on relatively easier prompts, ensuring the density of positive reward signals and thus avoiding the length collapse. Meanwhile, the learned length bias can be generalized across domains. We distill all findings into valuable insights and practical guidelines, and further validate them across the Qwen3 series, ranging from 0.6B to 30B, demonstrating the robustness and generalization.
Analysis of length-penalized training for efficient reasoning.
#rl #reasoning