

2026-02-12

Convex Dominance in Deep Learning I: A Scaling Law of Loss and Learning Rate
(Zhiqi Bu, Shiyun Xu, Jialin Mao)

Deep learning has non-convex loss landscape and its optimization dynamics is hard to analyze or control. Nevertheless, the dynamics can be empirically convex-like across various tasks, models, optimizers, hyperparameters, etc. In this work, we examine the applicability of convexity and Lipschitz continuity in deep learning, in order to precisely control the loss dynamics via the learning rate schedules. We illustrate that deep learning quickly becomes weakly convex after a short period of training, and the loss is predicable by an upper bound on the last iterate, which further informs the scaling of optimal learning rate. Through the lens of convexity, we build scaling laws of learning rates and losses that extrapolate as much as 80X across training horizons and 70X across model sizes.
Convex 가정 하에서 평균 Weight의 학습 중간 시점의 Loss 혹은 최종 시점의 Loss의 특성을 예측, 그리고 모델 크기와 학습 길이에 따른 LR Scaling Law를 구축.
haracterizing averaged any-time or last-iterate loss, and developing a learning rate scaling law given model size and training horizon, based on a convexity assumption.
#scaling-law #optimization
Towards Robust Scaling Laws for Optimizers
(Alexandra Volkova, Mher Safaryan, Christoph H. Lampert, Dan Alistarh)

The quality of Large Language Model (LLM) pretraining depends on multiple factors, including the compute budget and the choice of optimization algorithm. Empirical scaling laws are widely used to predict loss as model size and training data grow, however, almost all existing studies fix the optimizer (typically AdamW). At the same time, a new generation of optimizers (e.g., Muon, Shampoo, SOAP) promises faster and more stable convergence, but their relationship with model and data scaling is not yet well understood. In this work, we study scaling laws across different optimizers. Empirically, we show that 1) separate Chinchilla-style scaling laws for each optimizer are ill-conditioned and have highly correlated parameters. Instead, 2) we propose a more robust law with shared power-law exponents and optimizer-specific rescaling factors, which enable direct comparison between optimizers. Finally, 3) we provide a theoretical analysis of gradient-based methods for the proxy task of a convex quadratic objective, demonstrating that Chinchilla-style scaling laws emerge naturally as a result of loss decomposition into irreducible, approximation, and optimization errors.
Optimizer에 대한 Scaling Law. Optimizer가 데이터 효율성에 어떻게 영향을 미치는지 깔끔하게 드러냄.
Scaling law for optimizers. This cleanly shows how the optimizer choice affects data efficiency.
#optimization #scaling-law
Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning
(Dawid J. Kopiczko, Sagar Vaze, Tijmen Blankevoort, Yuki M. Asano)
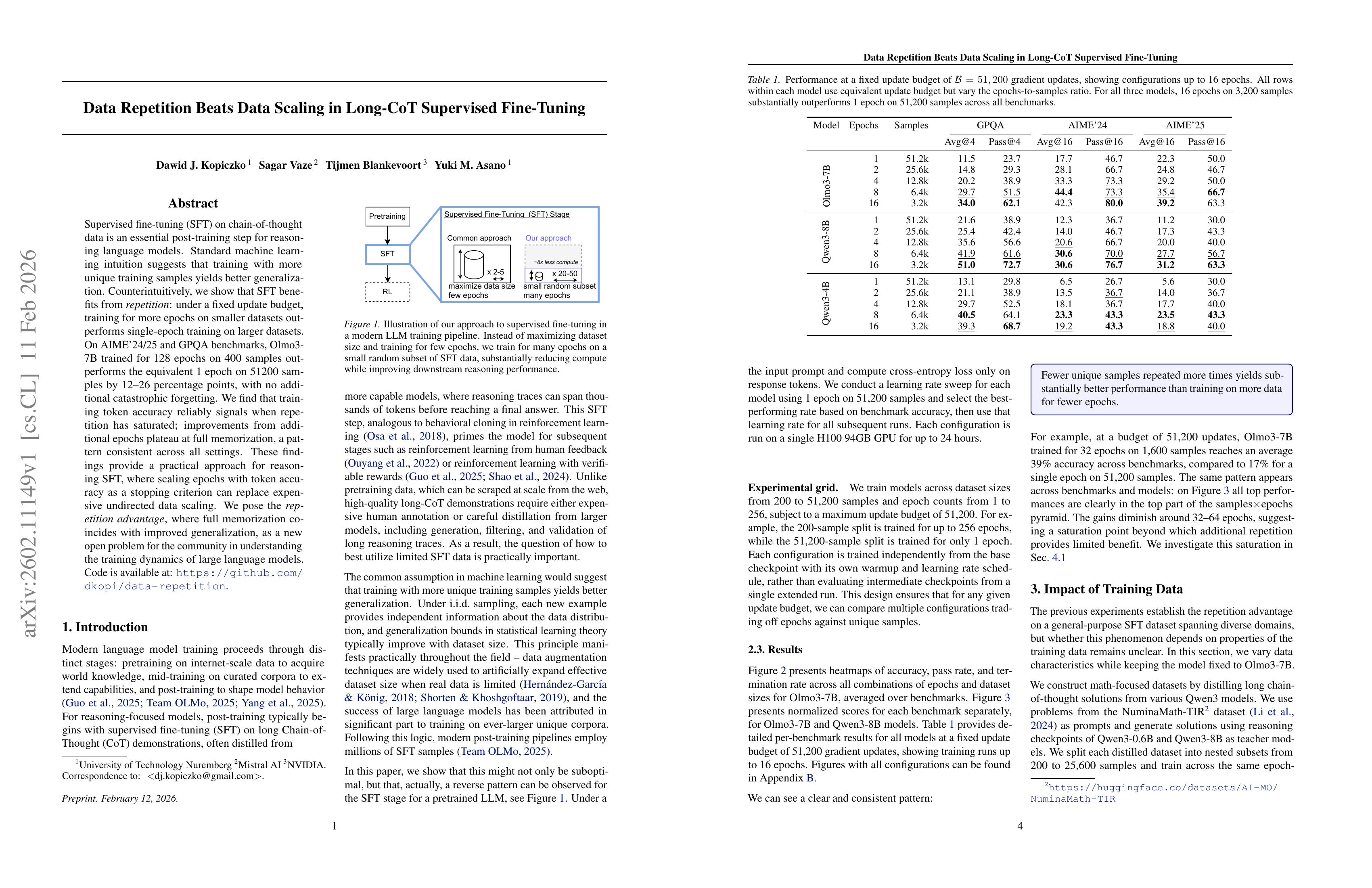
Supervised fine-tuning (SFT) on chain-of-thought data is an essential post-training step for reasoning language models. Standard machine learning intuition suggests that training with more unique training samples yields better generalization. Counterintuitively, we show that SFT benefits from repetition: under a fixed update budget, training for more epochs on smaller datasets outperforms single-epoch training on larger datasets. On AIME’24/25 and GPQA benchmarks, Olmo3-7B trained for 128 epochs on 400 samples outperforms the equivalent 1 epoch on 51200 samples by 12-26 percentage points, with no additional catastrophic forgetting. We find that training token accuracy reliably signals when repetition has saturated; improvements from additional epochs plateau at full memorization, a pattern consistent across all settings. These findings provide a practical approach for reasoning SFT, where scaling epochs with token accuracy as a stopping criterion can replace expensive undirected data scaling. We pose the repetition advantage, where full memorization coincides with improved generalization, as a new open problem for the community in understanding the training dynamics of large language models.
적은 수의 샘플에 대해서 Multi Epoch 파인튜닝을 하는 쪽이 많은 샘플에 대해 Single Epoch 파인튜닝을 하는 것보다 나을지도. Hyperfitting을 생각나게 하는 결과. https://arxiv.org/abs/2412.04318
Finetuning multi-epoch on a small number of samples could be better than single-epoch on larger samples. It reminds me of hyperfitting. https://arxiv.org/abs/2412.04318
#finetuning
Weight Decay Improves Language Model Plasticity
(Tessa Han, Sebastian Bordt, Hanlin Zhang, Sham Kakade)
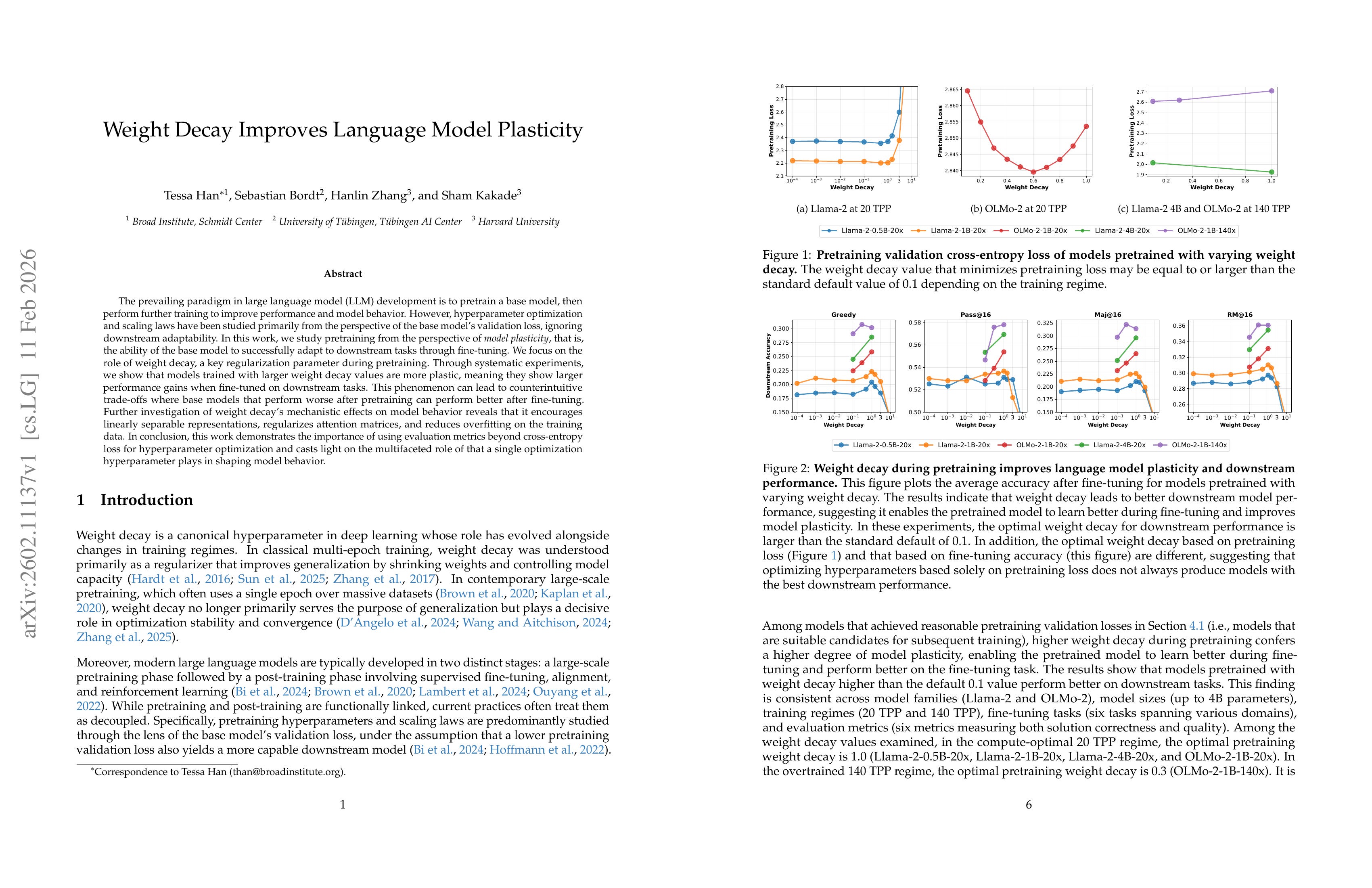
The prevailing paradigm in large language model (LLM) development is to pretrain a base model, then perform further training to improve performance and model behavior. However, hyperparameter optimization and scaling laws have been studied primarily from the perspective of the base model’s validation loss, ignoring downstream adaptability. In this work, we study pretraining from the perspective of model plasticity, that is, the ability of the base model to successfully adapt to downstream tasks through fine-tuning. We focus on the role of weight decay, a key regularization parameter during pretraining. Through systematic experiments, we show that models trained with larger weight decay values are more plastic, meaning they show larger performance gains when fine-tuned on downstream tasks. This phenomenon can lead to counterintuitive trade-offs where base models that perform worse after pretraining can perform better after fine-tuning. Further investigation of weight decay’s mechanistic effects on model behavior reveals that it encourages linearly separable representations, regularizes attention matrices, and reduces overfitting on the training data. In conclusion, this work demonstrates the importance of using evaluation metrics beyond cross-entropy loss for hyperparameter optimization and casts light on the multifaceted role of that a single optimization hyperparameter plays in shaping model behavior.
큰 Weight Decay로 프리트레이닝된 모델이 파인튜닝하기에는 더 나을지도. RL에서도 마찬가지일지?
A model pretrained with larger weight decay could have better finetunability. Would this be similar in RL?
#finetuning #pretraining #optimization
Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training
(Yiwei Qin, Zhen Huang, Tiantian Mi, Weiye Si, Chenyang Zhou, Qipeng Guo, Siyuan Feng, Pengfei Liu)

Data quality determines foundation model performance, yet systematic processing frameworks are lacking. We introduce Data Darwinism, a ten-level taxonomy (L0-L9) that conceptualizes data-model co-evolution: advanced models produce superior data for next-generation systems. We validate this on scientific literature by constructing Darwin-Science, a 900B-token corpus (L0-L5). We identify a learnability gap in raw scientific text, which we bridge via L4 (Generative Refinement) and L5 (Cognitive Completion) using frontier LLMs to explicate reasoning and terminology. To ensure rigorous attribution, we pre-trained daVinci-origin-3B/7B models from scratch, excluding scientific content to create contamination-free baselines. After 600B tokens of continued pre-training, Darwin-Science outperforms baselines by +2.12 (3B) and +2.95 (7B) points across 20+ benchmarks, rising to +5.60 and +8.40 points on domain-aligned tasks. Systematic progression to L5 yields a +1.36 total gain, confirming that higher-level processing unlocks latent data value. We release the Darwin-Science corpus and daVinci-origin models to enable principled, co-evolutionary development.
과학에 대한 프리트레이닝 데이터 구축. 10개의 레벨이 있으나 구현한 것은 6개 레벨.
Building pretraining data for science. There are 10 levels but what is actually implemented here is 6 levels.
#dataset #synthetic-data #pretraining
Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics
(Leheng Sheng, Wenchang Ma, Ruixin Hong, Xiang Wang, An Zhang, Tat-Seng Chua)
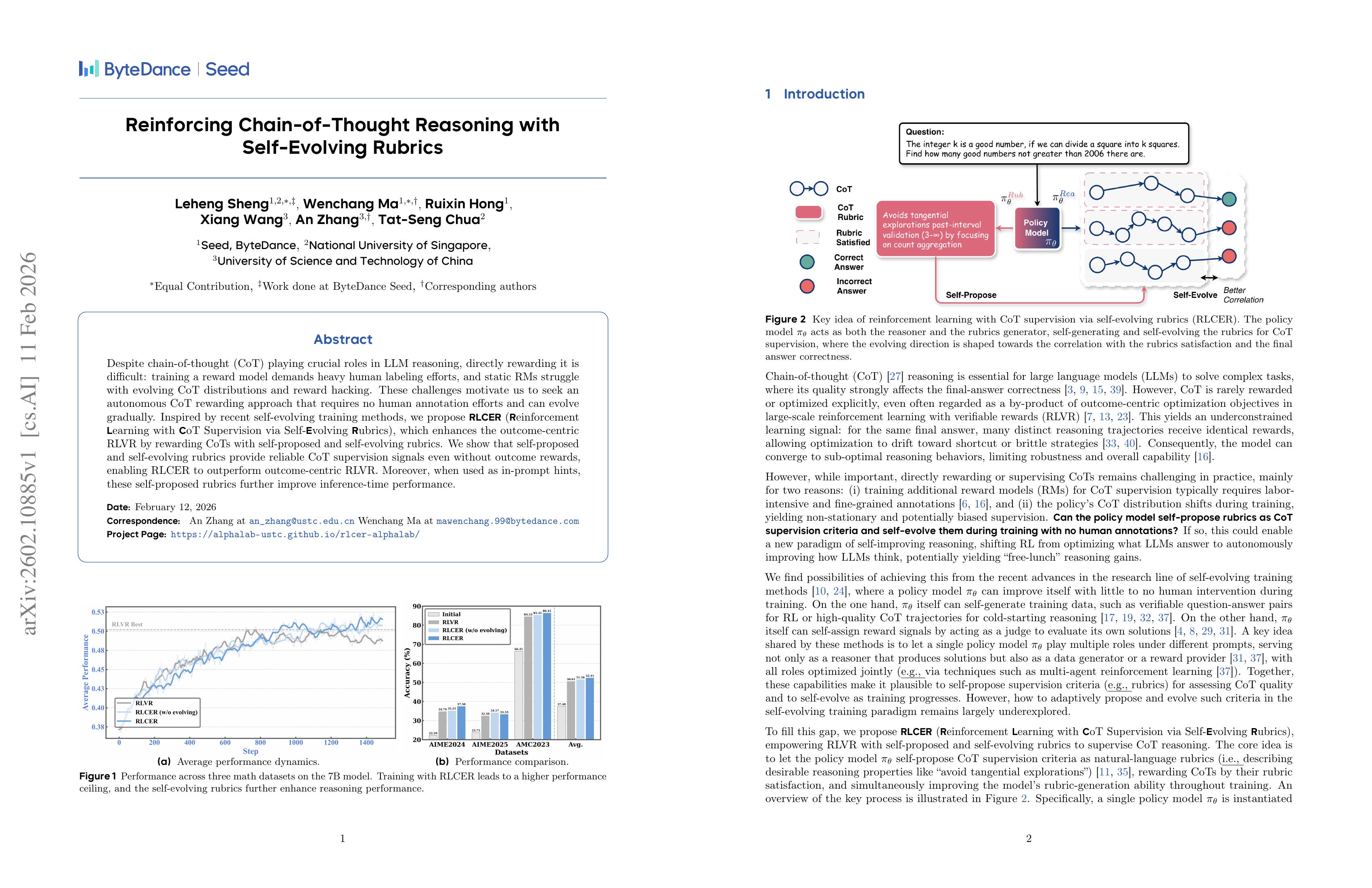
Despite chain-of-thought (CoT) playing crucial roles in LLM reasoning, directly rewarding it is difficult: training a reward model demands heavy human labeling efforts, and static RMs struggle with evolving CoT distributions and reward hacking. These challenges motivate us to seek an autonomous CoT rewarding approach that requires no human annotation efforts and can evolve gradually. Inspired by recent self-evolving training methods, we propose RLCER (Reinforcement Learning with CoT Supervision via Self-Evolving Rubrics), which enhances the outcome-centric RLVR by rewarding CoTs with self-proposed and self-evolving rubrics. We show that self-proposed and self-evolving rubrics provide reliable CoT supervision signals even without outcome rewards, enabling RLCER to outperform outcome-centric RLVR. Moreover, when used as in-prompt hints, these self-proposed rubrics further improve inference-time performance.
최종 결과와 CoT 모두에 보상을 부여하기 위한 방법. 하나의 Policy가 추론 생성과 CoT에 대한 루브릭 생성을 할 수 있도록 학습됨. 루브릭은 응답의 정확성과 정적 상관이 있을 경우, 그리고 CoT를 잘 구분하는 경우 보상이 부여됨.
Rewarding both final outcome and CoT. Single policy trained to generate reasoning and rubric for CoT. Rubrics are rewarded if they are positively correlated with answer correctness and discriminate CoTs well.
#rl #reward-model