

2026-02-02

A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
(Zihan Qiu, Zeyu Huang, Kaiyue Wen, Peng Jin, Bo Zheng, Yuxin Zhou, Haofeng Huang, Zekun Wang, Xiao Li, Huaqing Zhang, Yang Xu, Haoran Lian, Siqi Zhang, Rui Men, Jianwei Zhang, Ivan Titov, Dayiheng Liu, Jingren Zhou, Junyang Lin)

We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (e.g., softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon outlier-driven rescaling and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).
LLM에 왜 아웃라이어가 발생하는가? Normalization과 결합했을 때 다른 차원의 규모를 조절할 수 있게 되기 때문. 이 조절을 가능하게 하는 다른 메커니즘을 추가하면 아웃라이어가 억제됨. StyleGAN에서 발생했던 것과 같은 선상의 문제.
Why do outliers exist in LLMs? Because when they are combined with normalization it allows scaling of the other dimensions. If we introduce a mechanism that allows the scaling then outliers are suppressed. Same line of problem as in StyleGAN.
#transformer
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
(Ximing Lu, David Acuna, Jaehun Jung, Jian Hu, Di Zhang, Shizhe Diao, Yunheng Zou, Shaokun Zhang, Brandon Cui, Mingjie Liu, Hyunwoo Kim, Prithviraj Ammanabrolu, Jan Kautz, Yi Dong, Yejin Choi)

Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
텍스트 데이터로 빈칸 채우기 MCQ 문제를 구축.
Building MCQ infilling tasks from corpora.
#synthetic-data #reasoning
SpanNorm: Reconciling Training Stability and Performance in Deep Transformers
(Chao Wang, Bei Li, Jiaqi Zhang, Xinyu Liu, Yuchun Fan, Linkun Lyu, Xin Chen, Jingang Wang, Tong Xiao, Peng Pei, Xunliang Cai)

The success of Large Language Models (LLMs) hinges on the stable training of deep Transformer architectures. A critical design choice is the placement of normalization layers, leading to a fundamental trade-off: the “PreNorm” architecture ensures training stability at the cost of potential performance degradation in deep models, while the “PostNorm” architecture offers strong performance but suffers from severe training instability. In this work, we propose SpanNorm, a novel technique designed to resolve this dilemma by integrating the strengths of both paradigms. Structurally, SpanNorm establishes a clean residual connection that spans the entire transformer block to stabilize signal propagation, while employing a PostNorm-style computation that normalizes the aggregated output to enhance model performance. We provide a theoretical analysis demonstrating that SpanNorm, combined with a principled scaling strategy, maintains bounded signal variance throughout the network, preventing the gradient issues that plague PostNorm models, and also alleviating the representation collapse of PreNorm. Empirically, SpanNorm consistently outperforms standard normalization schemes in both dense and Mixture-of-Experts (MoE) scenarios, paving the way for more powerful and stable Transformer architectures.
Post Norm을 다시 시도하려는 연구실들이 많은 듯. 이 연구에서는 장거리 Skip Connection과 출력 Linear 레이어에 대한 초기값 규모 조정으로 해결.
Maybe many labs want to reintroduce post norm again. In this case mitigation is simple, which is to use long skip connections and output linear init scaling.
#transformer
MoVE: Mixture of Value Embeddings -- A New Axis for Scaling Parametric Memory in Autoregressive Models
(Yangyan Li)

Autoregressive sequence modeling stands as the cornerstone of modern Generative AI, powering results across diverse modalities ranging from text generation to image generation. However, a fundamental limitation of this paradigm is the rigid structural coupling of model capacity to computational cost: expanding a model’s parametric memory -- its repository of factual knowledge or visual patterns -- traditionally requires deepening or widening the network, which incurs a proportional rise in active FLOPs. In this work, we introduce MoVE (Mixture of Value Embeddings, a mechanism that breaks this coupling and establishes a new axis for scaling capacity. MoVE decouples memory from compute by introducing a global bank of learnable value embeddings shared across all attention layers. For every step in the sequence, the model employs a differentiable soft gating mechanism to dynamically mix retrieved concepts from this bank into the standard value projection. This architecture allows parametric memory to be scaled independently of network depth by simply increasing the number of embedding slots. We validate MoVE through strictly controlled experiments on two representative applications of autoregressive modeling: Text Generation and Image Generation. In both domains, MoVE yields consistent performance improvements over standard and layer-wise memory baselines, enabling the construction of “memory-dense” models that achieve lower perplexity and higher fidelity than their dense counterparts at comparable compute budgets.
임베딩 레이어에 대한 연구. 여기서는 Value Head에 결합.
More work on embedding layers. In this case embedding is combined with value heads.
#transformer
TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
(Ruijie Zhang, Yequan Zhao, Ziyue Liu, Zhengyang Wang, Dongyang Li, Yupeng Su, Sijia Liu, Zheng Zhang)
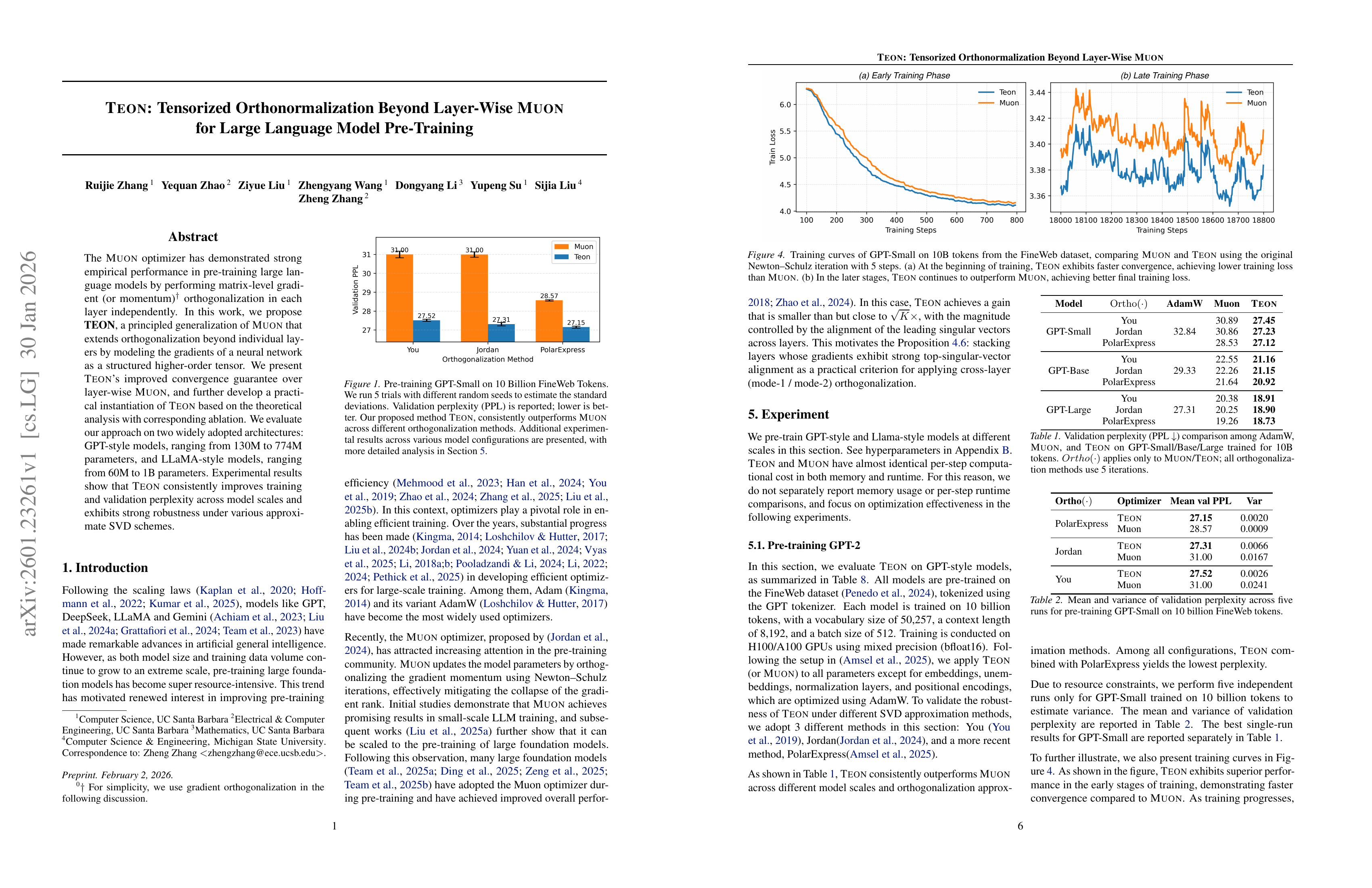
The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON’s improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
여러 행렬에 대해 Muon 적용.
Muon over multiple matrices.
#optimization
Mano: Restriking Manifold Optimization for LLM Training
(Yufei Gu, Zeke Xie)

While large language models (LLMs) have emerged as a significant advancement in artificial intelligence, the hardware and computational costs for training LLMs are also significantly burdensome. Among the state-of-the-art optimizers, AdamW relies on diagonal curvature estimates and ignores structural properties, while Muon applies global spectral normalization at the expense of losing curvature information. In this study, we restriked manifold optimization methods for training LLMs, which may address both optimizers’ limitations, while conventional manifold optimization methods have been largely overlooked due to the poor performance in large-scale model optimization. By innovatively projecting the momentum onto the tangent space of model parameters and constraining it on a rotational Oblique manifold, we propose a novel, powerful, and efficient optimizer Mano that is the first to bridge the performance gap between manifold optimization and modern optimizers. Extensive experiments on the LLaMA and Qwen3 models demonstrate that Mano consistently and significantly outperforms AdamW and Muon even with less memory consumption and computational complexity, respectively, suggesting an expanded Pareto frontier in terms of space and time efficiency.
행렬 축에 대한 정규화와 사영만으로도 최적화에는 충분할지?
Would axis-wise normalization and projection be enough for optimization?
#optimization
Great curation of papers here. The outlier rescaling framing makes a lot of sense when you consider how normalization layers are basically learning to route signal dynamically. We ran into similr behavior when experimenting with quantization last year, and it was alaways unclear whether to treat it as a bug or feature until seeing work like this.