

2026-01-01

Joint Selection for Large-Scale Pre-Training Data via Policy Gradient-based Mask Learning
(Ziqing Fan, Yuqiao Xian, Yan Sun, Li Shen)

A fine-grained data recipe is crucial for pre-training large language models, as it can significantly enhance training efficiency and model performance. One important ingredient in the recipe is to select samples based on scores produced by defined rules, LLM judgment, or statistical information in embeddings, which can be roughly categorized into quality and diversity metrics. Due to the high computational cost when applied to trillion-scale token pre-training datasets such as FineWeb and DCLM, these two or more types of metrics are rarely considered jointly in a single selection process. However, in our empirical study, selecting samples based on quality metrics exhibit severe diminishing returns during long-term pre-training, while selecting on diversity metrics removes too many valuable high-quality samples, both of which limit pre-trained LLMs’ capabilities. Therefore, we introduce DATAMASK, a novel and efficient joint learning framework designed for large-scale pre-training data selection that can simultaneously optimize multiple types of metrics in a unified process, with this study focusing specifically on quality and diversity metrics. DATAMASK approaches the selection process as a mask learning problem, involving iterative sampling of data masks, computation of policy gradients based on predefined objectives with sampled masks, and updating of mask sampling logits. Through policy gradient-based optimization and various acceleration enhancements, it significantly reduces selection time by 98.9% compared to greedy algorithm, enabling our study to explore joint learning within trillion-scale tokens. With DATAMASK, we select a subset of about 10% from the 15 trillion-token FineWeb dataset, termed FineWeb-Mask. Evaluated across 12 diverse tasks, we achieves significant improvements of 3.2% on a 1.5B dense model and 1.9% on a 7B MoE model.
품질과 다양성 척도를 동시에 고려하는 데이터 선택 알고리즘.
Data selection algorithm that considers both quality and diversity metrics.
#pretraining #dataset
Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
(Jiachen T. Wang, Tong Wu, Kaifeng Lyu, James Zou, Dawn Song, Ruoxi Jia, Prateek Mittal)

Data teams at frontier AI companies routinely train small proxy models to make critical decisions about pretraining data recipes for full-scale training runs. However, the community has a limited understanding of whether and when conclusions drawn from small-scale experiments reliably transfer to full-scale model training. In this work, we uncover a subtle yet critical issue in the standard experimental protocol for data recipe assessment: the use of identical small-scale model training configurations across all data recipes in the name of “fair” comparison. We show that the experiment conclusions about data quality can flip with even minor adjustments to training hyperparameters, as the optimal training configuration is inherently data-dependent. Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step. Consequently, we posit that the objective of data recipe assessment should be to identify the recipe that yields the best performance under data-specific tuning. To mitigate the high cost of hyperparameter tuning, we introduce a simple patch to the evaluation protocol: using reduced learning rates for proxy model training. We show that this approach yields relative performance that strongly correlates with that of fully tuned large-scale LLM pretraining runs. Theoretically, we prove that for random-feature models, this approach preserves the ordering of datasets according to their optimal achievable loss. Empirically, we validate this approach across 23 data recipes covering four critical dimensions of data curation, demonstrating dramatic improvements in the reliability of small-scale experiments.
데이터 비율 Ablation을 위해 작은 프록시 모델을 사용하는 경우 하이퍼파라미터에 대한 민감도가 결론을 바꿀 수 있다. 작은 LR을 쓰는 것이 도움이 될 수 있음. Chinchilla 비율 휴리스틱을 사용했는데 이것이 영향을 미쳤을지도?
Hyperparameter sensitivity of small proxy models for dataset ablations can flip the conclusions. A small LR can be helpful for this. Maybe this is affected by the chinchilla ratio they used?
#dataset #hyperparameter
mHC: Manifold-Constrained Hyper-Connections
(Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Liang Zhao, Shangyan Zhou, Zhean Xu, Zhengyan Zhang, Wangding Zeng, Shengding Hu, Yuqing Wang, Jingyang Yuan, Lean Wang, Wenfeng Liang)
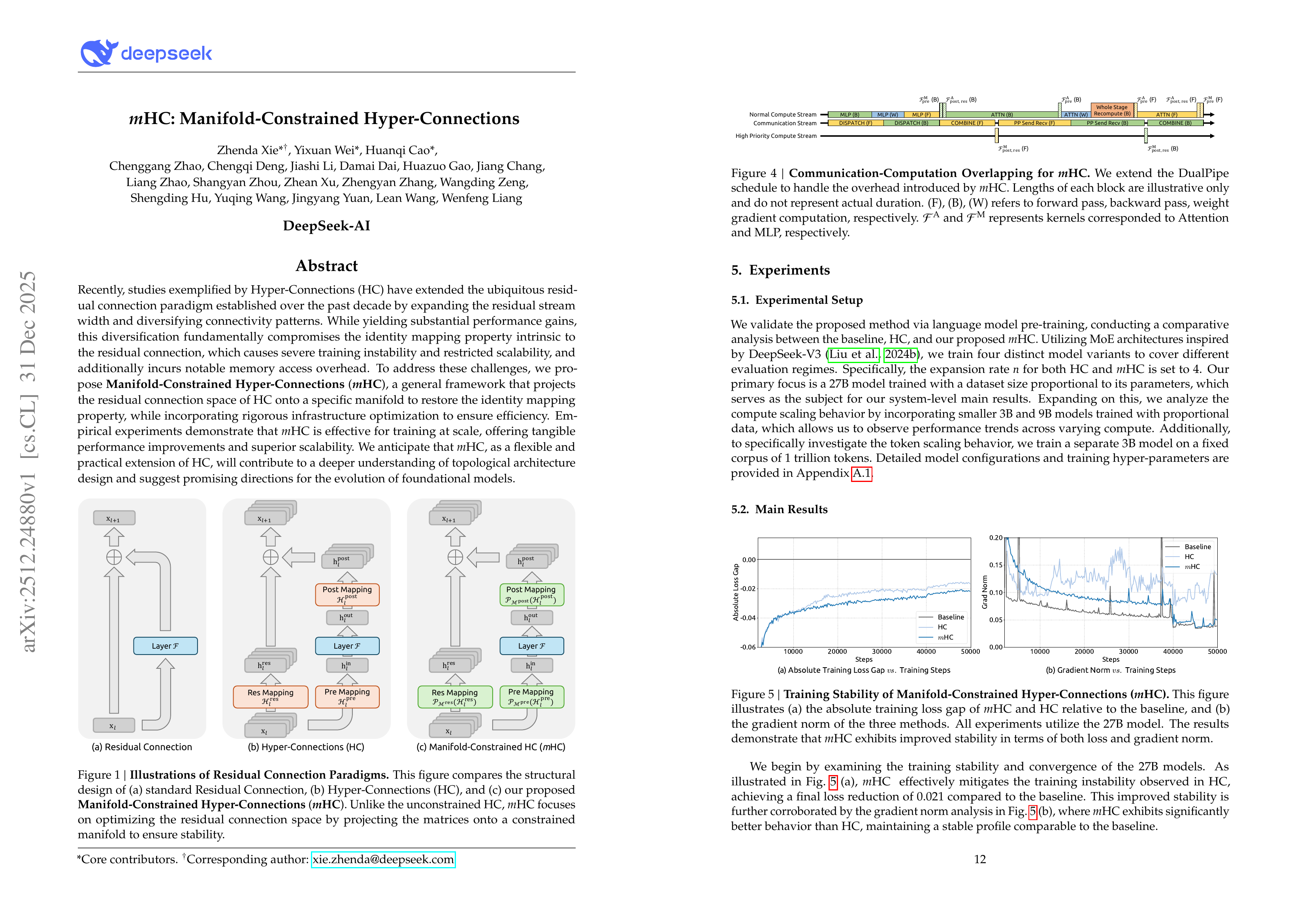
Recently, studies exemplified by Hyper-Connections (HC) have extended the ubiquitous residual connection paradigm established over the past decade by expanding the residual stream width and diversifying connectivity patterns. While yielding substantial performance gains, this diversification fundamentally compromises the identity mapping property intrinsic to the residual connection, which causes severe training instability and restricted scalability, and additionally incurs notable memory access overhead. To address these challenges, we propose Manifold-Constrained Hyper-Connections (mHC), a general framework that projects the residual connection space of HC onto a specific manifold to restore the identity mapping property, while incorporating rigorous infrastructure optimization to ensure efficiency. Empirical experiments demonstrate that mHC is effective for training at scale, offering tangible performance improvements and superior scalability. We anticipate that mHC, as a flexible and practical extension of HC, will contribute to a deeper understanding of topological architecture design and suggest promising directions for the evolution of foundational models.
DeepSeek이 Hyper Connections의 (https://arxiv.org/abs/2409.19606) Signal Propagation과 인프라 지원을 개선. Skip Connection은 (이전에 있었던 많은 개선 시도를 고려하면) 가장 질문이 제기되지 않는 아키텍처 선택이라고 생각. 어쩌면 DeepSeek의 다음 모델에서는 새로운 아키텍처를 기대해도 될 지도?
DeepSeek improved the signal propagation of Hyper Connections (https://arxiv.org/abs/2409.19606) and infrastructure support. I think skip connections are the most unquestioned architectural choice considering previous attempts to improve it. Maybe we can expect a novel architecture from the next release of DeepSeek?
#transformer
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
(Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, Yang Li, Zhongwen Li, Shirong Lin, Jiashun Liu, Zenan Liu, Tao Luo, Dilxat Muhtar, Yuanbin Qu, Jiaqiang Shi, Qinghui Sun, Yingshui Tan, Hao Tang, Runze Wang, Yi Wang, Zhaoguo Wang, Yanan Wu, Shaopan Xiong, Binchen Xu, Xander Xu, Yuchi Xu, Qipeng Zhang, Xixia Zhang, Haizhou Zhao, Jie Zhao, Shuaibing Zhao, Baihui Zheng, Jianhui Zheng, Suhang Zheng, Yanni Zhu, Mengze Cai, Kerui Cao, Xitong Chen, Yue Dai, Lifan Du, Tao Feng, Tao He, Jin Hu, Yijie Hu, Ziyu Jiang, Cheng Li, Xiang Li, Jing Liang, Chonghuan Liu, ZhenDong Liu, Haodong Mi, Yanhu Mo, Junjia Ni, Shixin Pei, Jingyu Shen, XiaoShuai Song, Cecilia Wang, Chaofan Wang, Kangyu Wang, Pei Wang, Tao Wang, Wei Wang, Ke Xiao, Mingyu Xu, Tiange Xu, Nan Ya, Siran Yang, Jianan Ye, Yaxing Zang, Duo Zhang, Junbo Zhang, Boren Zheng, Wanxi Deng, Ling Pan, Lin Qu, Wenbo Su, Jiamang Wang, Wei Wang, Hu Wei, Minggang Wu, Cheng Yu, Bing Zhao, Zhicheng Zheng, Bo Zheng)

Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Agentic RL 학습 프레임워크, 환경 실행 엔진, 학습 전략에 대한 상세한 리포트. 에이전트 RL 파이프라인에 대해서는 가장 종합적인 리포트 중 하나일지도.
Detailed report on an agentic RL training framework, environment engine, and training strategies. I think this is one of the most comprehensive ones for agentic RL pipelines.
#rl #agent
Efficient Context Scaling with LongCat ZigZag Attention
(Chen Zhang, Yang Bai, Jiahuan Li, Anchun Gui, Keheng Wang, Feifan Liu, Guanyu Wu, Yuwei Jiang, Defei Bu, Li Wei, Haihang Jing, Hongyin Tang, Xin Chen, Xiangzhou Huang, Fengcun Li, Rongxiang Weng, Yulei Qian, Yifan Lu, Yerui Sun, Jingang Wang, Yuchen Xie, Xunliang Cai)

We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.
Sparse Attention 채택을 위한 미드트레이닝. Sink 블록과 Local Window 블록 여러 개를 결합한 고정된 Sparse Mask를 사용하는 것 같은데 다만 아주 명확하지는 않음.
Mid-training to adopt sparse attention. The sparse pattern seems like a fixed mask that mixes several local windows and a sink block, but the actual construction is a bit ambiguous.
#sparse-attention
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
(Junru Lu, Jiarui Qin, Lingfeng Qiao, Yinghui Li, Xinyi Dai, Bo Ke, Jianfeng He, Ruizhi Qiao, Di Yin, Xing Sun, Yunsheng Wu, Yinsong Liu, Shuangyin Liu, Mingkong Tang, Haodong Lin, Jiayi Kuang, Fanxu Meng, Xiaojuan Tang, Yunjia Xi, Junjie Huang, Haotong Yang, Zhenyi Shen, Yangning Li, Qianwen Zhang, Yifei Yu, Siyu An, Junnan Dong, Qiufeng Wang, Jie Wang, Keyu Chen, Wei Wen, Taian Guo, Zhifeng Shen, Daohai Yu, Jiahao Li, Ke Li, Zongyi Li, Xiaoyu Tan)
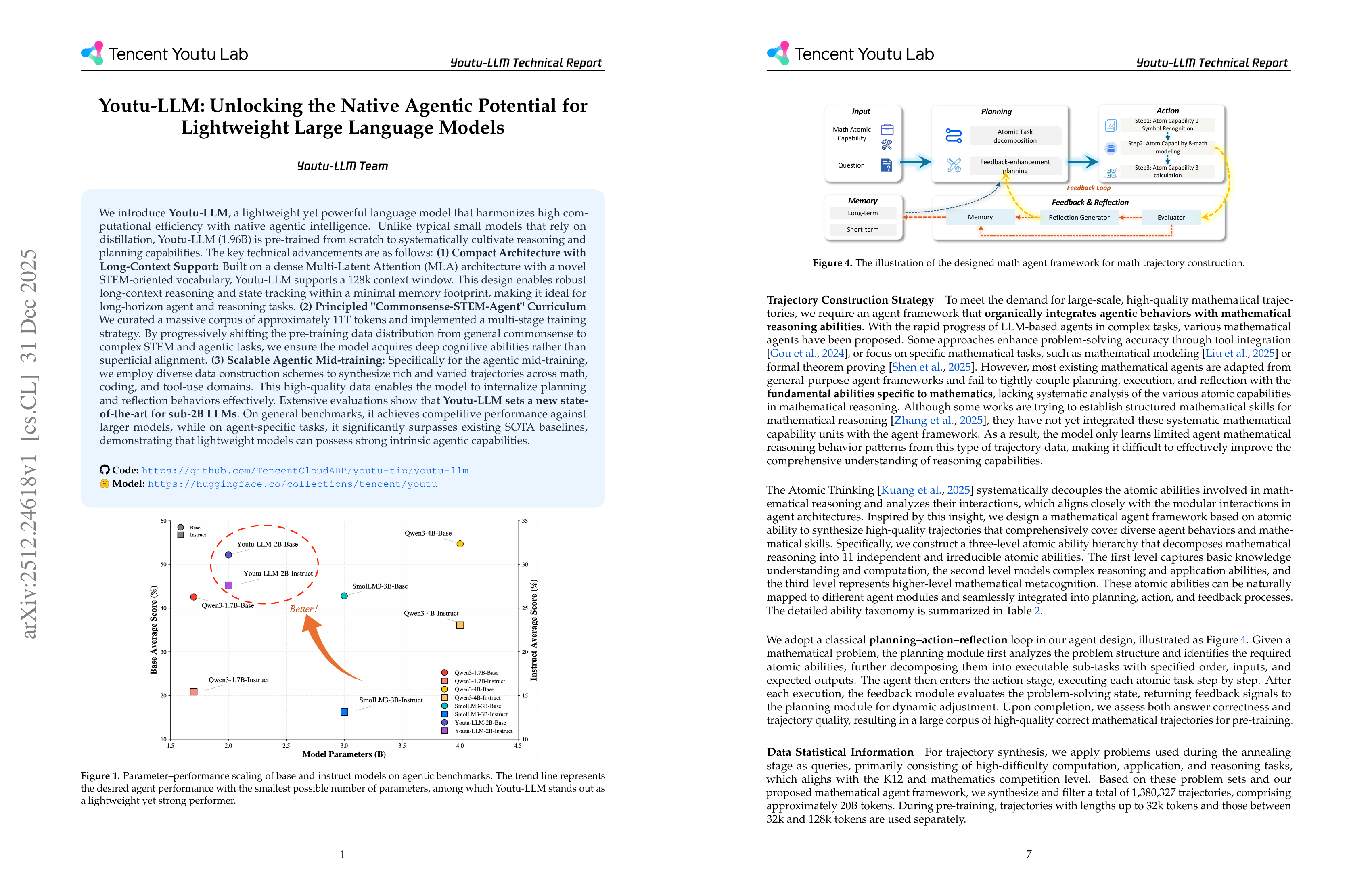
We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled “Commonsense-STEM-Agent” Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Small LLM 구축에 대한 프리트레이닝에서 포스트트레이닝까지의 리포트. Agent 궤적을 합성하는 과정에 집중하고 있음. 어쩌면 이후에 에이전트 포스트트레이닝을 시도할지도. 그런데 Tencent AI Lab과 YouTu Lab의 관계는 무엇일지?
Report on building a small LLM, from pre-training to post-training, mostly focused on synthesizing agent trajectories. Maybe they will pursue agentic post-training further later. btw, what is the relationship between Tencent AI Lab and YouTu Lab?
#synthetic-data #agent #mid-training
Trellis: Learning to Compress Key-Value Memory in Attention Models
(Mahdi Karami, Ali Behrouz, Praneeth Kacham, Vahab Mirrokni)

Transformers, while powerful, suffer from quadratic computational complexity and the ever-growing Key-Value (KV) cache of the attention mechanism. This paper introduces Trellis, a novel Transformer architecture with bounded memory that learns how to compress its key-value memory dynamically at test time. Trellis replaces the standard KV cache with a fixed-size memory and train a two-pass recurrent compression mechanism to store new keys and values into memory. To achieve this, it leverages an online gradient descent procedure with a forget gate, enabling the compressed memory to be updated recursively while learning to retain important contextual information from incoming tokens at test time. Extensive experiments on language modeling, common-sense reasoning, recall-intensive tasks, and time series show that the proposed architecture outperforms strong baselines. Notably, its performance gains increase as the sequence length grows, highlighting its potential for long-context applications.
비선형 Recurrence를 사용하는 Test-Time Training과 L2 정규화를 결합한 Slot Attention. 저자들은 이런 형태의 아키텍처에 대해 굉장히 많이 탐색해왔는데 최종적으로 하나의 아키텍처로 수렴하게 될지 궁금.
Slot attention using Test-Time Training with nonlinear recurrence and L2 regularization. The authors explored various possibilities of these architectures. Will this converge to one architecture?
#state-space-model