

2025년 9월 4일

Any-Order Flexible Length Masked Diffusion
(Jaeyeon Kim, Lee Cheuk-Kit, Carles Domingo-Enrich, Yilun Du, Sham Kakade, Timothy Ngotiaoco, Sitan Chen, Michael Albergo)

Masked diffusion models (MDMs) have recently emerged as a promising alternative to autoregressive models over discrete domains. MDMs generate sequences in an any-order, parallel fashion, enabling fast inference and strong performance on non-causal tasks. However, a crucial limitation is that they do not support token insertions and are thus limited to fixed-length generations. To this end, we introduce Flexible Masked Diffusion Models (FlexMDMs), a discrete diffusion paradigm that simultaneously can model sequences of flexible length while provably retaining MDMs' flexibility of any-order inference. Grounded in an extension of the stochastic interpolant framework, FlexMDMs generate sequences by inserting mask tokens and unmasking them. Empirically, we show that FlexMDMs match MDMs in perplexity while modeling length statistics with much higher fidelity. On a synthetic maze planning task, they achieve ≈ 60 % higher success rate than MDM baselines. Finally, we show pretrained MDMs can easily be retrofitted into FlexMDMs: on 16 H100s, it takes only three days to fine-tune LLaDA-8B into a FlexMDM, achieving superior performance on math (GSM8K, 58%→67%) and code infilling performance (52%→65%).
가변 길이를 지원하는 Masked Diffusion. Unmasking 스케줄과 함께 Insertion 스케줄을 도입함.
Masked diffusion that supports variable length. It incorporates both insertion and unmasking schedules.
#diffusion
Benchmarking Optimizers for Large Language Model Pretraining
(Andrei Semenov, Matteo Pagliardini, Martin Jaggi)

The recent development of Large Language Models (LLMs) has been accompanied by an effervescence of novel ideas and methods to better optimize the loss of deep learning models. Claims from those methods are myriad: from faster convergence to removing reliance on certain hyperparameters. However, the diverse experimental protocols used to validate these claims make direct comparisons between methods challenging. This study presents a comprehensive evaluation of recent optimization techniques across standardized LLM pretraining scenarios, systematically varying model size, batch size, and training duration. Through careful tuning of each method, we provide guidance to practitioners on which optimizer is best suited for each scenario. For researchers, our work highlights promising directions for future optimization research. Finally, by releasing our code and making all experiments fully reproducible, we hope our efforts can help the development and rigorous benchmarking of future methods.
Optimizer 벤치마크 1. AdEMAMix는 흥미로움. (최근에 쓰인 사례도 등장. https://github.com/swiss-ai/apertus-tech-report/blob/main/Apertus_Tech_Report.pdf) 유망한 Optimizer가 몇 있는데 토큰 효율성은 어느 정도일지?
Optimizer benchmarks 1. AdEMAMix is interesting. (It has been used in a recent model, https://github.com/swiss-ai/apertus-tech-report/blob/main/Apertus_Tech_Report.pdf) There are promising optimizers. How would they compare in token efficiency?
#optimizer
Fantastic Pretraining Optimizers and Where to Find Them
(Kaiyue Wen, David Hall, Tengyu Ma, Percy Liang)
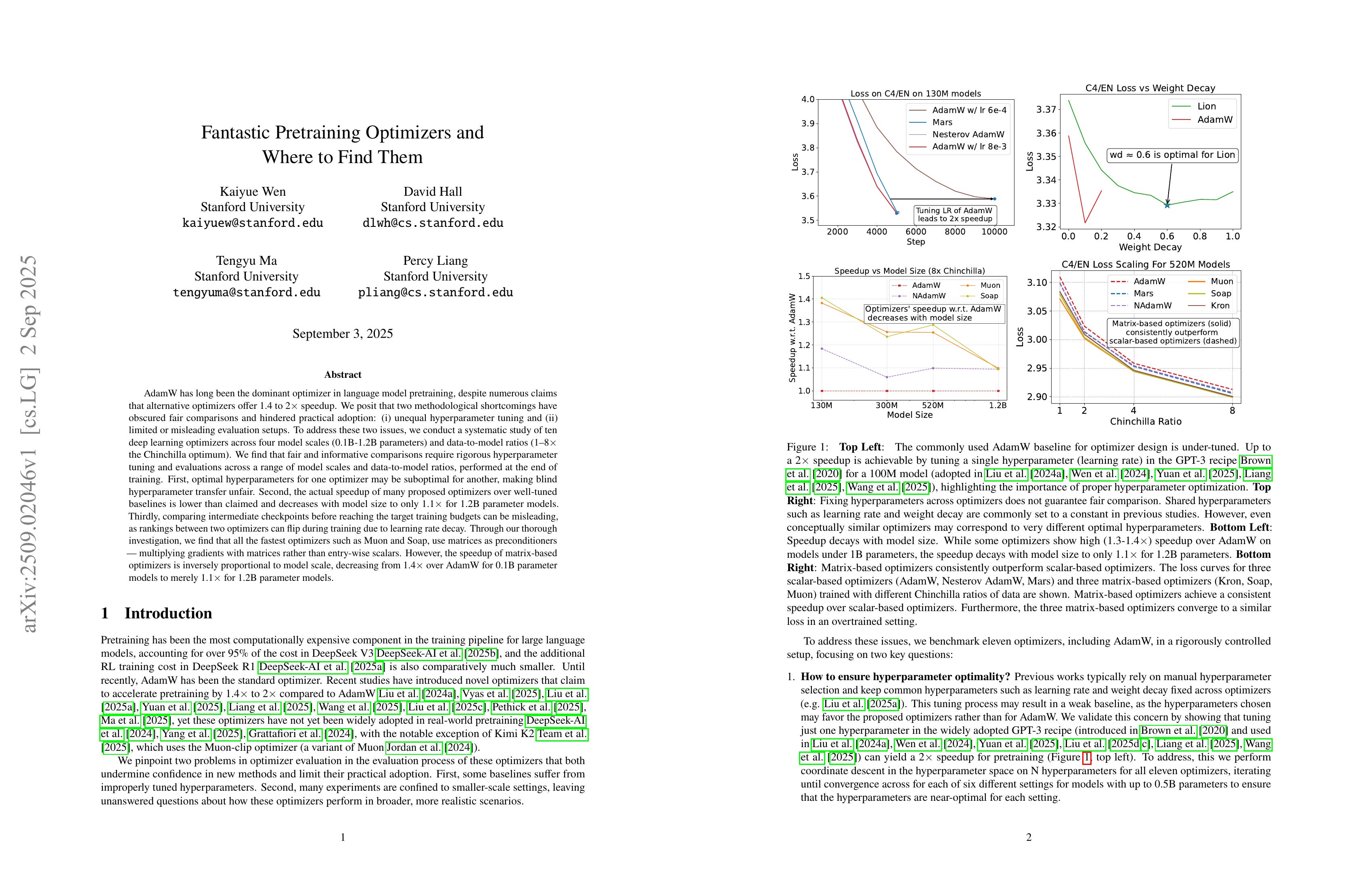
AdamW has long been the dominant optimizer in language model pretraining, despite numerous claims that alternative optimizers offer 1.4 to 2x speedup. We posit that two methodological shortcomings have obscured fair comparisons and hindered practical adoption: (i) unequal hyperparameter tuning and (ii) limited or misleading evaluation setups. To address these two issues, we conduct a systematic study of ten deep learning optimizers across four model scales (0.1B-1.2B parameters) and data-to-model ratios (1-8x the Chinchilla optimum). We find that fair and informative comparisons require rigorous hyperparameter tuning and evaluations across a range of model scales and data-to-model ratios, performed at the end of training. First, optimal hyperparameters for one optimizer may be suboptimal for another, making blind hyperparameter transfer unfair. Second, the actual speedup of many proposed optimizers over well-tuned baselines is lower than claimed and decreases with model size to only 1.1x for 1.2B parameter models. Thirdly, comparing intermediate checkpoints before reaching the target training budgets can be misleading, as rankings between two optimizers can flip during training due to learning rate decay. Through our thorough investigation, we find that all the fastest optimizers such as Muon and Soap, use matrices as preconditioners -- multiplying gradients with matrices rather than entry-wise scalars. However, the speedup of matrix-based optimizers is inversely proportional to model scale, decreasing from 1.4x over AdamW for 0.1B parameter models to merely 1.1x for 1.2B parameter models.
Optimizer 벤치마크 2. 하이퍼파라미터 튜닝과 모델과 데이터 크기의 충분한 Scaling이 중요하다는 것을 다시 한 번 보여줌. 사실 Chinchilla 최적 휴리스틱은 (20x 룰) 최근 기준에서는 연산 최적 관점에서도 Undertraining일 수 있음.
Optimizer benchmark 2. This again shows that proper hyperparameter tuning and sufficient scaling of both model and data are crucial for correctly comparing optimizers. Actually, the chinchilla optimal heuristic (20x rule) could be undertraining by modern standards, even with respect to compute optimality.
#optimizer
Distilled Pretraining: A modern lens of Data, In-Context Learning and Test-Time Scaling
(Sachin Goyal, David Lopez-Paz, Kartik Ahuja)

In the past year, distillation has seen a renewed prominence in large language model (LLM) pretraining, exemplified by the Llama-3.2 and Gemma model families. While distillation has historically been shown to improve statistical modeling, its effects on new paradigms that are key to modern LLMs, such as test-time scaling and in-context learning, remain underexplored. In this work, we make three main contributions. First, we show that pretraining with distillation yields models that exhibit remarkably better test-time scaling. Second, we observe that this benefit comes with a trade-off: distillation impairs in-context learning capabilities, particularly the one modeled via induction heads. Third, to demystify these findings, we study distilled pretraining in a sandbox of a bigram model, which helps us isolate the common principal factor behind our observations. Finally, using these insights, we shed light on various design choices for pretraining that should help practitioners going forward.
프리트레이닝 시점의 Distillation에 대한 분석. Diversity를 향상시키나 In-context Learning에 문제가 생김 (데이터 엔트로피가 낮을 때는 노이즈를 첨가하는 것일 수 있음). 이 문제에 대해 어떻게 대응할지, RL 학습된 모델이 더 나은 Teacher일 수 있다는 결과 등등도 포함.
Analysis of distillation during pretraining. It enhances diversity but hurts in-context learning (potentially because it introduces noise when data entropy is low). This paper also shows how to address this and finds that RL-trained models could serve as better teachers.
#distillation #pretraining
OneCAT: Decoder-Only Auto-Regressive Model for Unified Understanding and Generation
(Han Li, Xinyu Peng, Yaoming Wang, Zelin Peng, Xin Chen, Rongxiang Weng, Jingang Wang, Xunliang Cai, Wenrui Dai, Hongkai Xiong)

We introduce OneCAT, a unified multimodal model that seamlessly integrates understanding, generation, and editing within a novel, pure decoder-only transformer architecture. Our framework uniquely eliminates the need for external components such as Vision Transformers (ViT) or vision tokenizer during inference, leading to significant efficiency gains, especially for high-resolution inputs. This is achieved through a modality-specific Mixture-of-Experts (MoE) structure trained with a single autoregressive (AR) objective, which also natively supports dynamic resolutions. Furthermore, we pioneer a multi-scale visual autoregressive mechanism within the Large Language Model (LLM) that drastically reduces decoding steps compared to diffusion-based methods while maintaining state-of-the-art performance. Our findings demonstrate the powerful potential of pure autoregressive modeling as a sufficient and elegant foundation for unified multimodal intelligence. As a result, OneCAT sets a new performance standard, outperforming existing open-source unified multimodal models across benchmarks for multimodal generation, editing, and understanding.
이미지 이해 및 생성 통합 모델. 이해를 위해 얕은 패치 프로젝터를 사용. 생성에는 VAR. 그리고 과제와 이미지 크기에 대한 Expert를 채택.
Unified model for image understanding and generation. Uses a shallow patch projector for understanding and VAR for generation. Adopts task and scale-aware experts.
#multimodal #autoregressive-model #image-generation