



2025년 7월 4일

Flexible Language Modeling in Continuous Space with Transformer-based Autoregressive Flows
(Ruixiang Zhang, Shuangfei Zhai, Jiatao Gu, Yizhe Zhang, Huangjie Zheng, Tianrong Chen, Miguel Angel Bautista, Josh Susskind, Navdeep Jaitly)

Autoregressive models have driven remarkable progress in language modeling. Their foundational reliance on discrete tokens, unidirectional context, and single-pass decoding, while central to their success, also inspires the exploration of a design space that could offer new axes of modeling flexibility. In this work, we explore an alternative paradigm, shifting language modeling from a discrete token space to a continuous latent space. We propose a novel framework TarFlowLM, that employs transformer-based autoregressive normalizing flows to model these continuous representations. This approach unlocks substantial flexibility, enabling the construction of models that can capture global bi-directional context through stacked, alternating-direction autoregressive transformations, support block-wise generation with flexible token patch sizes, and facilitate a hierarchical multi-pass generation process. We further propose new mixture-based coupling transformations designed to capture complex dependencies within the latent space shaped by discrete data, and demonstrate theoretical connections to conventional discrete autoregressive models. Extensive experiments on language modeling benchmarks demonstrate strong likelihood performance and highlight the flexible modeling capabilities inherent in our framework.
Autoregressive Flow를 사용한 LM. 입출력은 VAE에 의존하네요. Diffusion도 그렇고 애플이 대안적 LM을 여럿 시도하는군요 (https://arxiv.org/abs/2506.20639).
A LM using autoregressive flow. It relies on VAE for input and output. Similar to recent diffusion-based LMs, Apple seems to be exploring various alternative approaches to LM (https://arxiv.org/abs/2506.20639).
#flow #lm
Energy-Based Transformers are Scalable Learners and Thinkers
(Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, Tariq Iqbal)

Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
EBM으로 텍스트와 비디오 생성을 학습. 전반적으로 EBM 강의 같은 논문이네요.
An EBM for text and image generation. Overall, it reads like a lecture on EBMs.
#energy-based-model
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
(Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Poovendran, Graham Neubig, Xiang Yue)

Math reasoning has become the poster child of progress in large language models (LLMs), with new models rapidly surpassing human-level performance on benchmarks like MATH and AIME. But as math leaderboards improve week by week, it is worth asking: do these gains reflect broader problem-solving ability or just narrow overfitting? To answer this question, we evaluate over 20 open-weight reasoning-tuned models across a broad suite of tasks, including math, scientific QA, agent planning, coding, and standard instruction-following. We surprisingly find that most models that succeed in math fail to transfer their gains to other domains. To rigorously study this phenomenon, we conduct controlled experiments on Qwen3-14B models using math-only data but different tuning methods. We find that reinforcement learning (RL)-tuned models generalize well across domains, while supervised fine-tuning (SFT)-tuned models often forget general capabilities. Latent-space representation and token-space distribution shift analyses reveal that SFT induces substantial representation and output drift, while RL preserves general-domain structure. Our results suggest a need to rethink standard post-training recipes, particularly the reliance on SFT-distilled data for advancing reasoning models.
수학에 대해 학습한 추론 모델이 다른 도메인에도 일반화가 되는가라는 질문. RL로 학습한 경우에는 되는데 SFT로 한 경우에는 안 된다고. RL을 하라던 사람들이 또다시 1승을 거두는군요.
The question on whether reasoning models trained on math can generalize to other domains. The results show that RL-trained models can generalize, while SFT-trained models cannot. This is another win for those who have been advocating for RL.
#generalization #rl #reasoning
Scaling Collapse Reveals Universal Dynamics in Compute-Optimally Trained Neural Networks
(Shikai Qiu, Lechao Xiao, Andrew Gordon Wilson, Jeffrey Pennington, Atish Agarwala)

What scaling limits govern neural network training dynamics when model size and training time grow in tandem? We show that despite the complex interactions between architecture, training algorithms, and data, compute-optimally trained models exhibit a remarkably precise universality. Specifically, loss curves from models of varying sizes collapse onto a single universal curve when training compute and loss are normalized to unity at the end of training. With learning rate decay, the collapse becomes so tight that differences in the normalized curves across models fall below the noise floor of individual loss curves across random seeds, a phenomenon we term supercollapse. We observe supercollapse across learning rate schedules, datasets, and architectures, including transformers trained on next-token prediction, and find it breaks down when hyperparameters are scaled suboptimally, providing a precise and practical indicator of good scaling. We explain these phenomena by connecting collapse to the power-law structure in typical neural scaling laws, and analyzing a simple yet surprisingly effective model of SGD noise dynamics that accurately predicts loss curves across various learning rate schedules and quantitatively explains the origin of supercollapse.
Compute Optimal한 모델의 학습 과정에서 최종 Loss로 Loss를 나눠주면 Loss의 커브의 개형이 모델 크기와는 관계 없이 거의 일치한다는 발견에 대한 분석.
This paper analyzes the discovery that during the training of compute-optimal models, when the loss is normalized by the final loss value, the shape of the loss curve remains nearly identical regardless of model size.
#scaling-law
Fast and Simplex: 2-Simplicial Attention in Triton
(Aurko Roy, Timothy Chou, Sai Surya Duvvuri, Sijia Chen, Jiecao Yu, Xiaodong Wang, Manzil Zaheer, Rohan Anil)

Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern large language models increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that 2-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.
Trilinear Attention. 고전적인 아이디어가 다시 등장했네요. 연산 증가는 피할 수 없으니 Local Attention을 사용했습니다.
실험 세팅이 좀 특이합니다. Scaling Law 추정도 했는데 경사가 변화했군요. 추정치가 정확할지는 모르겠네요.
Trilinear attention. A classical idea has re-emerged. As it's impossible to avoid increased computation, they used local attention.
The experimental setting is somewhat unique. They also estimated scaling laws and found that the slope has changed. However, I'm not sure if the estimated values are accurate.
#transformer #scaling-law
Answer Matching Outperforms Multiple Choice for Language Model Evaluation
(Nikhil Chandak, Shashwat Goel, Ameya Prabhu, Moritz Hardt, Jonas Geiping)

Multiple choice benchmarks have long been the workhorse of language model evaluation because grading multiple choice is objective and easy to automate. However, we show multiple choice questions from popular benchmarks can often be answered without even seeing the question. These shortcuts arise from a fundamental limitation of discriminative evaluation not shared by evaluations of the model's free-form, generative answers. Until recently, there appeared to be no viable, scalable alternative to multiple choice--but, we show that this has changed. We consider generative evaluation via what we call answer matching: Give the candidate model the question without the options, have it generate a free-form response, then use a modern language model with the reference answer to determine if the response matches the reference. To compare the validity of different evaluation strategies, we annotate MMLU-Pro and GPQA-Diamond to obtain human grading data, and measure the agreement of each evaluation approach. We find answer matching using recent models--even small ones--achieves near-perfect agreement, in the range of inter-annotator agreement. In contrast, both multiple choice evaluation and using LLM-as-a-judge without reference answers aligns poorly with human grading. Improving evaluations via answer matching is not merely a conceptual concern: the rankings of several models change significantly when evaluating their free-form responses with answer matching. In light of these findings, we discuss how to move the evaluation ecosystem from multiple choice to answer matching.
MCQ 벤치마크에서 선택지를 제외하고 정답을 생성하게 한 다음 LLM으로 검증. 벤치마크의 난이도도 높아지고 좀 더 실용적인 척도라는 점에서 쓸만하겠네요.
In this study, the authors removed choices from MCQ benchmarks, and let the model to generate answers which are then verified using an LLM. This method seems promising as it increases the difficulty of the benchmarks while providing a more practical measure of LM performance.
#benchmark
Generalizing Verifiable Instruction Following
(Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, Hannaneh Hajishirzi)

A crucial factor for successful human and AI interaction is the ability of language models or chatbots to follow human instructions precisely. A common feature of instructions are output constraints like "only answer with yes or no" or "mention the word 'abrakadabra' at least 3 times" that the user adds to craft a more useful answer. Even today's strongest models struggle with fulfilling such constraints. We find that most models strongly overfit on a small set of verifiable constraints from the benchmarks that test these abilities, a skill called precise instruction following, and are not able to generalize well to unseen output constraints. We introduce a new benchmark, IFBench, to evaluate precise instruction following generalization on 58 new, diverse, and challenging verifiable out-of-domain constraints. In addition, we perform an extensive analysis of how and on what data models can be trained to improve precise instruction following generalization. Specifically, we carefully design constraint verification modules and show that reinforcement learning with verifiable rewards (RLVR) significantly improves instruction following. In addition to IFBench, we release 29 additional new hand-annotated training constraints and verification functions, RLVR training prompts, and code.
IFEval의 확장. 그리고 Instruction Following에 대한 Verifiable Reward를 사용한 RL.
An extension of IFEval. Additionally, RL using verifiable rewards for instruction following.
#rl #reasoning #instruction
Understanding and Improving Length Generalization in Recurrent Models
(Ricardo Buitrago Ruiz, Albert Gu)

Recently, recurrent models such as state space models and linear attention have become popular due to their linear complexity in the sequence length. Thanks to their recurrent nature, in principle they can process arbitrarily long sequences, but their performance sometimes drops considerably beyond their training context lengths-i.e. they fail to length generalize. In this work, we provide comprehensive empirical and theoretical analysis to support the unexplored states hypothesis, which posits that models fail to length generalize when during training they are only exposed to a limited subset of the distribution of all attainable states (i.e. states that would be attained if the recurrence was applied to long sequences). Furthermore, we investigate simple training interventions that aim to increase the coverage of the states that the model is trained on, e.g. by initializing the state with Gaussian noise or with the final state of a different input sequence. With only 500 post-training steps (∼ 0.1% of the pre-training budget), these interventions enable length generalization for sequences that are orders of magnitude longer than the training context (e.g. 2k → 128k) and show improved performance in long context tasks, thus presenting a simple and efficient way to enable robust length generalization in general recurrent models.
State Space Model의 길이 일반화 연구. 이전 시퀀스의 상태를 초기 상태로 사용해 다양한 상태를 접하게 하는 것으로 향상시킬 수 있다고. 사실 RNN 시절 LM을 학습하던 방법이죠.
SSM이 초기 상태에 민감하다는 이야기도 있었습니다만 (https://arxiv.org/abs/2406.07887) 어떨지 모르겠네요.
A study on length generalization of state space models. The paper suggests that we can improve generalization by exposing the model to various states, using the final state from previous sequences as an initial state. This is actually reminiscent of the method used for training language models in the RNN era.
There has been a report suggesting that SSMs are sensitive to initial states (https://arxiv.org/abs/2406.07887), so I'm curious about how this approach will fare.
#state-space-model #long-context
WebSailor: Navigating Super-human Reasoning for Web Agent
(Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, Jingren Zhou)
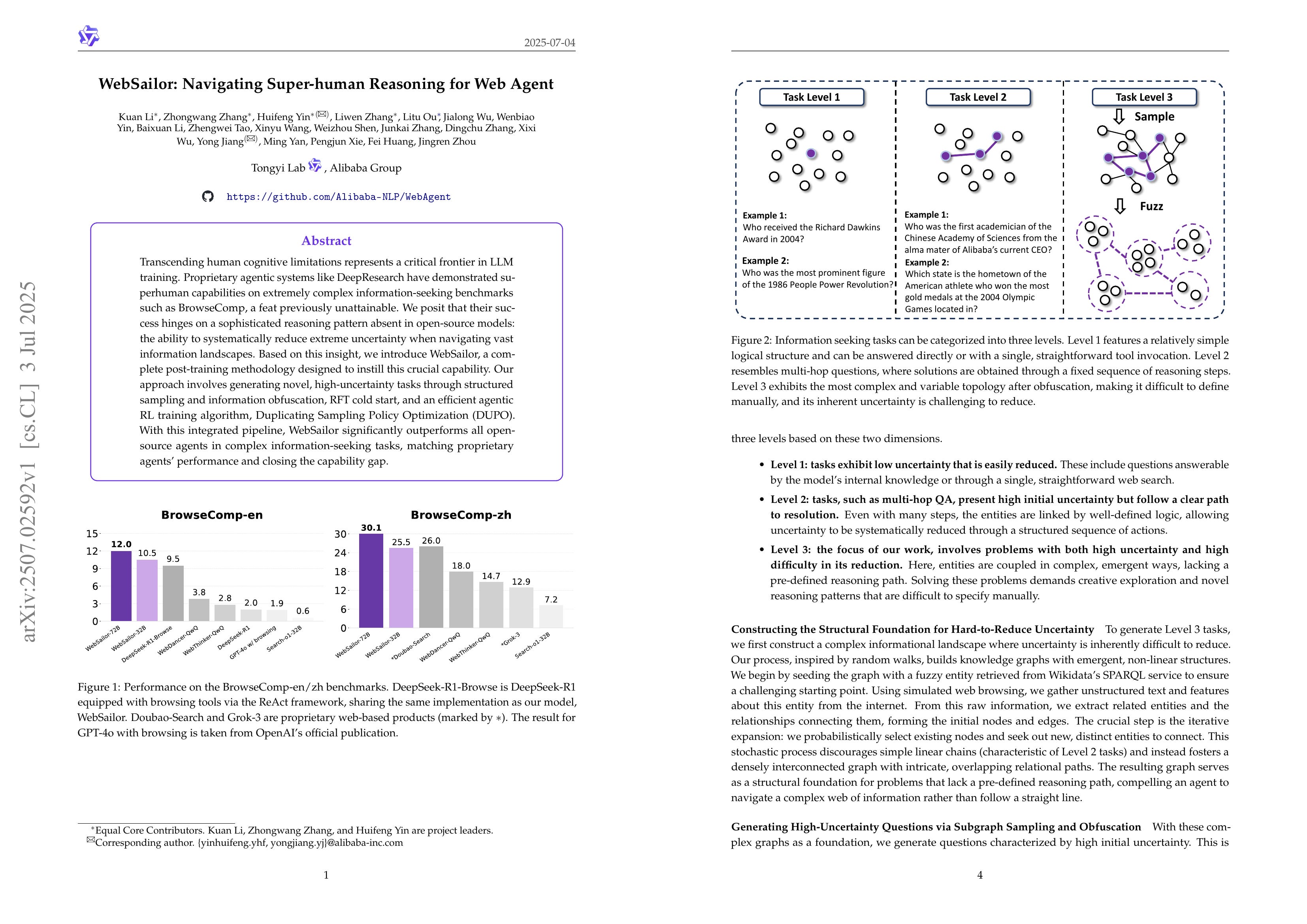
Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
웹 에이전트. 난이도가 높은 문제를 생성해내는 것이 핵심이네요.
Web agent. The key point is generating high-difficulty tasks.
#agent #rl #reasoning