



2025년 7월 10일

First Return, Entropy-Eliciting Explore
(Tianyu Zheng, Tianshun Xing, Qingshui Gu, Taoran Liang, Xingwei Qu, Xin Zhou, Yizhi Li, Zhoufutu Wen, Chenghua Lin, Wenhao Huang, Qian Liu, Ge Zhang, Zejun Ma)

Reinforcement Learning from Verifiable Rewards (RLVR) improves the reasoning abilities of Large Language Models (LLMs) but it struggles with unstable exploration. We propose FR3E (First Return, Entropy-Eliciting Explore), a structured exploration framework that identifies high-uncertainty decision points in reasoning trajectories and performs targeted rollouts to construct semantically grounded intermediate feedback. Our method provides targeted guidance without relying on dense supervision. Empirical results on mathematical reasoning benchmarks(AIME24) show that FR3E promotes more stable training, produces longer and more coherent responses, and increases the proportion of fully correct trajectories. These results highlight the framework's effectiveness in improving LLM reasoning through more robust and structured exploration.
엔트로피가 높은 토큰이 보통 분기점이므로 그 지점에서 추가적인 롤아웃을 생성해서 탐색을 촉진할 수 있다는 연구군요 (https://arxiv.org/abs/2506.01939).
This study explores enhancing exploration by generating additional rollouts at tokens with high entropy, as these are typically branching points (https://arxiv.org/abs/2506.01939).
#rl #reasoning
A Systematic Analysis of Hybrid Linear Attention
(Dustin Wang, Rui-Jie Zhu, Steven Abreu, Yong Shan, Taylor Kergan, Yuqi Pan, Yuhong Chou, Zheng Li, Ge Zhang, Wenhao Huang, Jason Eshraghian)

Transformers face quadratic complexity and memory issues with long sequences, prompting the adoption of linear attention mechanisms using fixed-size hidden states. However, linear models often suffer from limited recall performance, leading to hybrid architectures that combine linear and full attention layers. Despite extensive hybrid architecture research, the choice of linear attention component has not been deeply explored. We systematically evaluate various linear attention models across generations - vector recurrences to advanced gating mechanisms - both standalone and hybridized. To enable this comprehensive analysis, we trained and open-sourced 72 models: 36 at 340M parameters (20B tokens) and 36 at 1.3B parameters (100B tokens), covering six linear attention variants across five hybridization ratios. Benchmarking on standard language modeling and recall tasks reveals that superior standalone linear models do not necessarily excel in hybrids. While language modeling remains stable across linear-to-full attention ratios, recall significantly improves with increased full attention layers, particularly below a 3:1 ratio. Our study highlights selective gating, hierarchical recurrence, and controlled forgetting as critical for effective hybrid models. We recommend architectures such as HGRN-2 or GatedDeltaNet with a linear-to-full ratio between 3:1 and 6:1 to achieve Transformer-level recall efficiently. Our models are open-sourced at https://huggingface.co/collections/m-a-p/hybrid-linear-attention-research-686c488a63d609d2f20e2b1e.
다양한 Linear Attention을 사용한 하이브리드 모델에 대한 비교. 단독으로 좋은 모델이 트랜스포머와의 하이브리드에서도 최선인 것은 아니라고.
A comparison of hybrid models using various linear attention mechanisms. The study suggests that the best-performing linear attention module when used independently is not necessarily the optimal choice when combined with transformers in a hybrid architecture.
#efficient-attention #transformer #state-space-model
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
(Liliang Ren, Congcong Chen, Haoran Xu, Young Jin Kim, Adam Atkinson, Zheng Zhan, Jiankai Sun, Baolin Peng, Liyuan Liu, Shuohang Wang, Hao Cheng, Jianfeng Gao, Weizhu Chen, Yelong Shen)

Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
하이브리드 모델인데 상당히 많은 레시피를 한 번에 투하했네요. Mamba, Window Attention, Cross Decoder, SSM 상태에 대한 Gating, 그리고 Differential Attention까지.
A hybrid model that incorporates numerous techniques simultaneously. They've deployed a wide array of components including Mamba, window attention, cross decoder, gating for SSM states, and even differential attention.
#state-space-model #transformer #scaling-law
Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
(Martin Marek, Sanae Lotfi, Aditya Somasundaram, Andrew Gordon Wilson, Micah Goldblum)
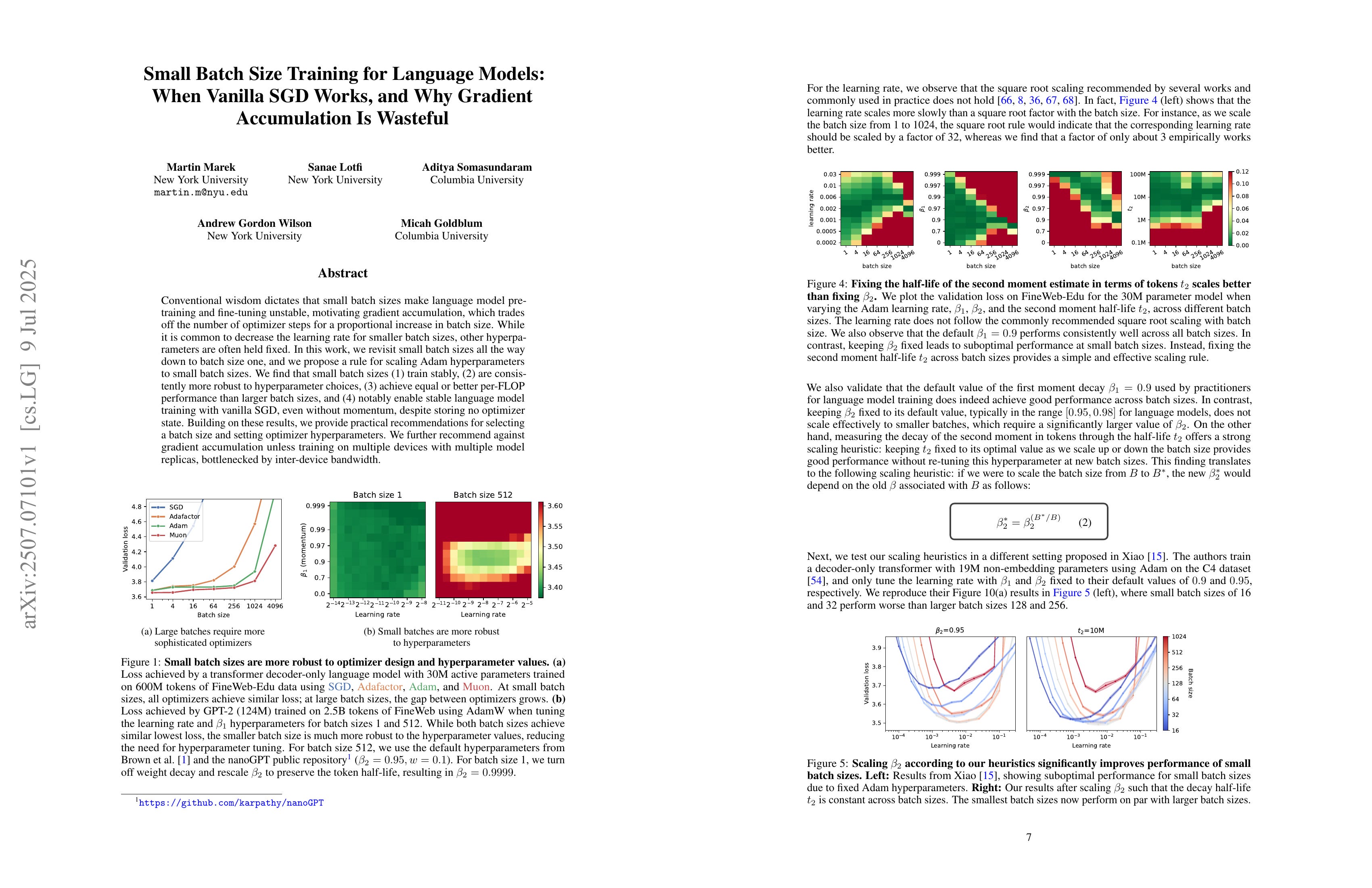
Conventional wisdom dictates that small batch sizes make language model pretraining and fine-tuning unstable, motivating gradient accumulation, which trades off the number of optimizer steps for a proportional increase in batch size. While it is common to decrease the learning rate for smaller batch sizes, other hyperparameters are often held fixed. In this work, we revisit small batch sizes all the way down to batch size one, and we propose a rule for scaling Adam hyperparameters to small batch sizes. We find that small batch sizes (1) train stably, (2) are consistently more robust to hyperparameter choices, (3) achieve equal or better per-FLOP performance than larger batch sizes, and (4) notably enable stable language model training with vanilla SGD, even without momentum, despite storing no optimizer state. Building on these results, we provide practical recommendations for selecting a batch size and setting optimizer hyperparameters. We further recommend against gradient accumulation unless training on multiple devices with multiple model replicas, bottlenecked by inter-device bandwidth.
작은 배치 크기에서는 SGD도 트랜스포머 LM 학습이 가능하다는 결과의 연장선이군요 (https://arxiv.org/abs/2506.12543). 여기서는 β_2를 조정해 Adam이 작은 배치 크기에서 잘 작동하게 만드는 실험을 했습니다.
This study extends previous research showing that SGD can be used for transformer LM training with small batch sizes (https://arxiv.org/abs/2506.12543). This work demonstrates that Adam can be made to work effectively with small batch sizes by adjusting β_2.
#optimization
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
(Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, Jianye Hao)

Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
Off-policy 데이터를 사용하기 위한 방법. KL Penalty를 베이스 모델과 이전 스텝의 모델에 대해서 계산한 다음 결합하고, 적당한 시점에서 On-policy로 전환하는군요.
A method for utilizing off-policy data. They calculate a combined KL penalty based on both the base model and models from previous steps, and then transition to on-policy at an appropriate point.
#rl #reasoning