



Log-Linear Attention
(Han Guo, Songlin Yang, Tarushii Goel, Eric P. Xing, Tri Dao, Yoon Kim)

The attention mechanism in Transformers is an important primitive for accurate and scalable sequence modeling. Its quadratic-compute and linear-memory complexity however remain significant bottlenecks. Linear attention and state-space models enable linear-time, constant-memory sequence modeling and can moreover be trained efficiently through matmul-rich parallelization across sequence length. However, at their core these models are still RNNs, and thus their use of a fixed-size hidden state to model the context is a fundamental limitation. This paper develops log-linear attention, an attention mechanism that balances linear attention's efficiency and the expressiveness of softmax attention. Log-linear attention replaces the fixed-size hidden state with a logarithmically growing set of hidden states. We show that with a particular growth function, log-linear attention admits a similarly matmul-rich parallel form whose compute cost is log-linear in sequence length. Log-linear attention is a general framework and can be applied on top of existing linear attention variants. As case studies, we instantiate log-linear variants of two recent architectures -- Mamba-2 and Gated DeltaNet -- and find they perform well compared to their linear-time variants.
길이에 따라 메모리가 고정되거나 혹은 선형 증가하는 것이 아니라 로그 증가하게 만든 절충이군요. 다만 여전히 Linear Attention 계통의 방법은 하이브리드로 사용되었을 때의 성능이 중요하겠죠.
A mid-range approach where memory increases logarithmically with sequence length, rather than being fixed or increasing linearly. However, for linear attention methods, their performance when used in hybrid models would likely still be more crucial.
#state-space-model
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
(Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Maximilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, Rif A. Saurous, Guillaume Lajoie, Charlotte Frenkel, Razvan Pascanu, Blaise Agüera y Arcas, João Sacramento)

Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
Mesa Optimization을 (https://arxiv.org/abs/2309.05858) 시퀀스 모델링에 대해 평가해봤군요. 짧은 시퀀스에 대해서 장점이 있는데 컨텍스트가 길어지면 역시 트랜스포머에 밀리네요. RNN의 어쩔 수 없는 한계이긴 합니다.
An attempt to use mesa optimization (https://arxiv.org/abs/2309.05858) for sequence modeling. It shows advantages for short sequences, but still falls behind transformers when the context becomes longer. This seems to be an inevitable limitation of RNNs.
#state-space-model
Kinetics: Rethinking Test-Time Scaling Laws
(Ranajoy Sadhukhan, Zhuoming Chen, Haizhong Zheng, Yang Zhou, Emma Strubell, Beidi Chen)

We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-N, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential for realizing the full potential of test-time scaling because, unlike training, where parameter scaling saturates, test-time accuracy continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
샘플링 비용을 고려한 추론 모델의 효율성 분석. 추론이 길어질수록 Attention에 의한 비용이 증가하고 이로 인해 모델 크기가 일정 이상일 때 추론에 의한 효율성이 높아진다고 하네요.
Analysis of inference model efficiency considering sampling costs. As inference length increases, the cost due to attention becomes dominant, resulting in higher efficiency from inference only when the model size exceeds a certain threshold.
#reasoning #scaling-law #efficiency #test-time-compute
Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
(Thao Nguyen, Yang Li, Olga Golovneva, Luke Zettlemoyer, Sewoong Oh, Ludwig Schmidt, Xian Li)

Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost all data sources publicly available on the internet so far. However, this pool of natural data does not grow at the same rate as the compute supply. Furthermore, the availability of high-quality texts is even more limited: data filtering pipelines often remove up to 99% of the initial web scrapes to achieve state-of-the-art. To address the "data wall" of pre-training scaling, our work explores ways to transform and recycle data discarded in existing filtering processes. We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.
저품질 데이터를 재작성해서 프리트레이닝에 사용한다는 아이디어.
The idea of rewriting low-quality data for use in pretraining.
#pretraining #corpus
FlashDMoE: Fast Distributed MoE in a Single Kernel
(Osayamen Jonathan Aimuyo, Byungsoo Oh, Rachee Singh)
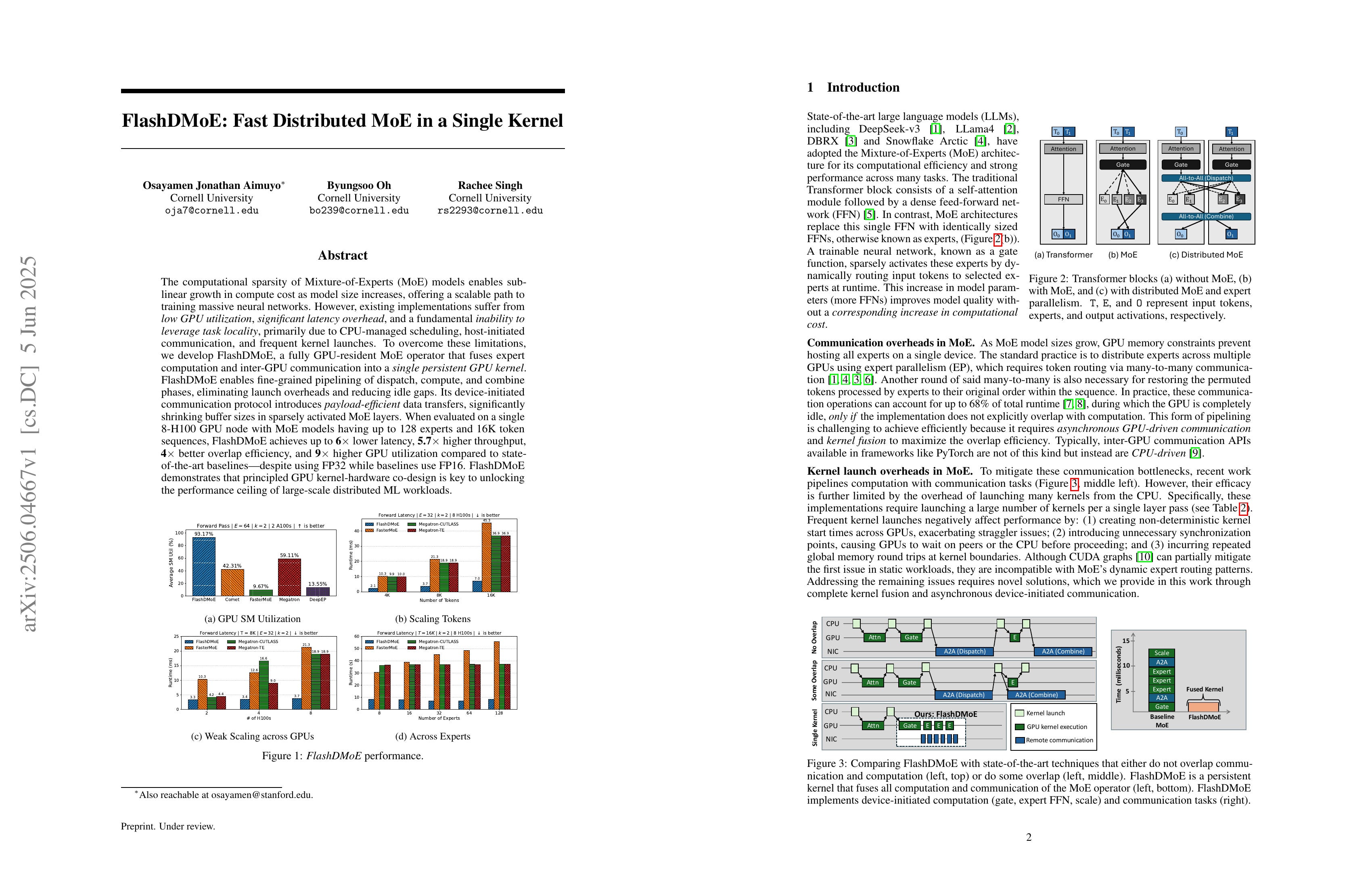
The computational sparsity of Mixture-of-Experts (MoE) models enables sub-linear growth in compute cost as model size increases, offering a scalable path to training massive neural networks. However, existing implementations suffer from low GPU utilization, significant latency overhead, and a fundamental inability to leverage task locality, primarily due to CPU-managed scheduling, host-initiated communication, and frequent kernel launches. To overcome these limitations, we develop FlashDMoE, a fully GPU-resident MoE operator that fuses expert computation and inter-GPU communication into a single persistent GPU kernel. FlashDMoE enables fine-grained pipelining of dispatch, compute, and combine phases, eliminating launch overheads and reducing idle gaps. Its device-initiated communication protocol introduces payload-efficient data transfers, significantly shrinking buffer sizes in sparsely activated MoE layers. When evaluated on a single 8-H100 GPU node with MoE models having up to 128 experts and 16K token sequences, FlashDMoE achieves up to 6x lower latency, 5.7x higher throughput, 4x better weak scaling efficiency, and 9x higher GPU utilization compared to state-of-the-art baselines, despite using FP32 while baselines use FP16. FlashDMoE demonstrates that principled GPU kernel-hardware co-design is key to unlocking the performance ceiling of large-scale distributed ML workloads.
MoE를 위한 단일 커널. 다만 현재 FP32에 대해서만 구현됐군요.
A single kernel for MoE. However, it's currently implemented only for FP32.
#moe #efficiency
Scaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets
(Marianna Nezhurina, Tomer Porian, Giovanni Pucceti, Tommie Kerssies, Romain Beaumont, Mehdi Cherti, Jenia Jitsev)
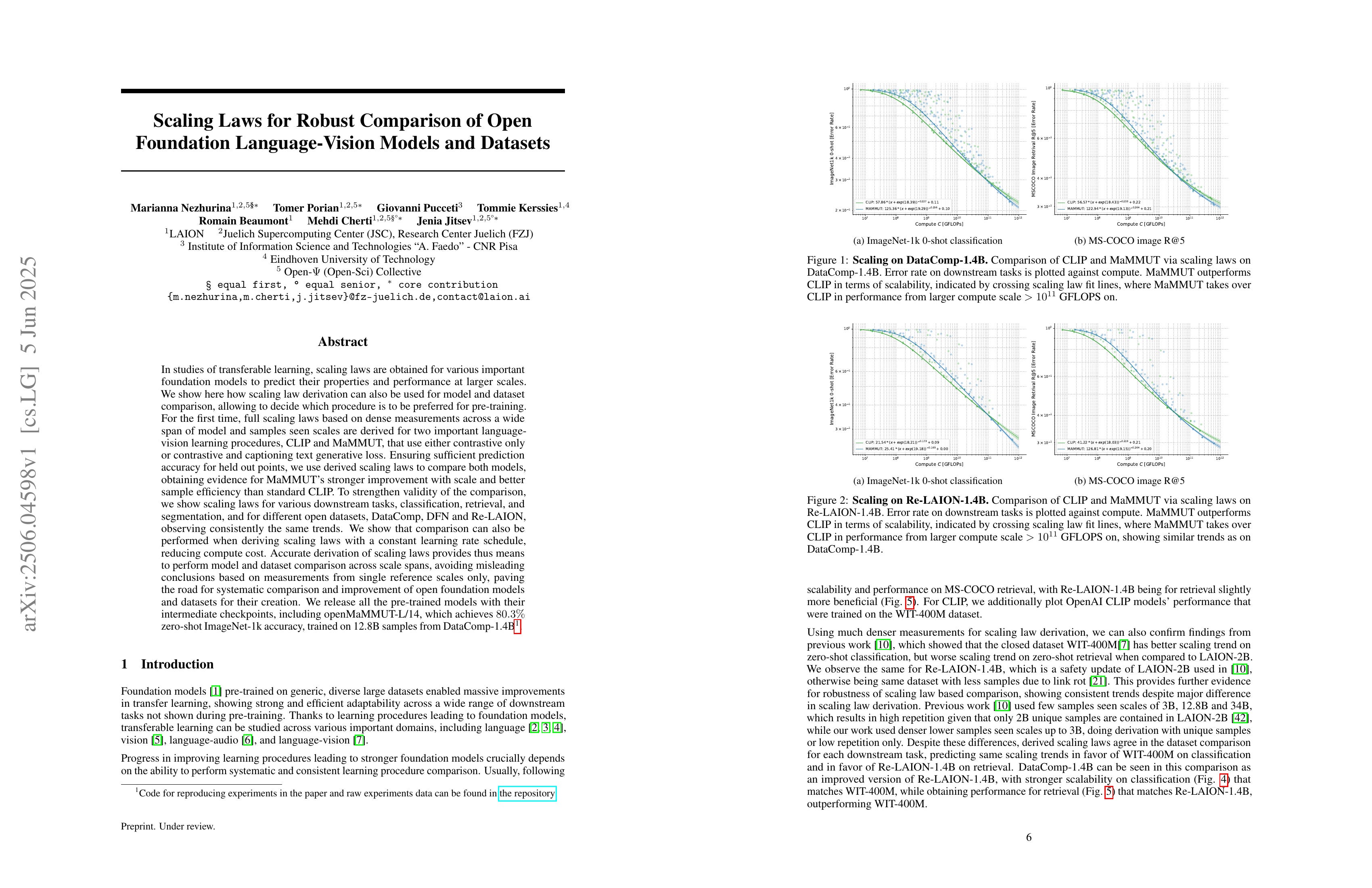
In studies of transferable learning, scaling laws are obtained for various important foundation models to predict their properties and performance at larger scales. We show here how scaling law derivation can also be used for model and dataset comparison, allowing to decide which procedure is to be preferred for pre-training. For the first time, full scaling laws based on dense measurements across a wide span of model and samples seen scales are derived for two important language-vision learning procedures, CLIP and MaMMUT, that use either contrastive only or contrastive and captioning text generative loss. Ensuring sufficient prediction accuracy for held out points, we use derived scaling laws to compare both models, obtaining evidence for MaMMUT's stronger improvement with scale and better sample efficiency than standard CLIP. To strengthen validity of the comparison, we show scaling laws for various downstream tasks, classification, retrieval, and segmentation, and for different open datasets, DataComp, DFN and Re-LAION, observing consistently the same trends. We show that comparison can also be performed when deriving scaling laws with a constant learning rate schedule, reducing compute cost. Accurate derivation of scaling laws provides thus means to perform model and dataset comparison across scale spans, avoiding misleading conclusions based on measurements from single reference scales only, paving the road for systematic comparison and improvement of open foundation models and datasets for their creation. We release all the pre-trained models with their intermediate checkpoints, including openMaMMUT-L/14, which achieves 80.3% zero-shot ImageNet-1k accuracy, trained on 12.8B samples from DataComp-1.4B. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/scaling-laws-for-comparison.
CLIP과 MaMMUT의 Scaling 특성 비교. Generative Loss가 포함되어서인지 MaMMUT이 더 낫다고 하네요.
Comparison of scaling characteristics between CLIP and MaMMUT. The paper suggests that MaMMUT performs better, possibly due to the inclusion of generative loss.
#clip #multimodal #scaling-law