



2025년 6월 3일

Esoteric Language Models
(Subham Sekhar Sahoo, Zhihan Yang, Yash Akhauri, Johnna Liu, Deepansha Singh, Zhoujun Cheng, Zhengzhong Liu, Eric Xing, John Thickstun, Arash Vahdat)

Diffusion-based language models offer a compelling alternative to autoregressive (AR) models by enabling parallel and controllable generation. Among this family of models, Masked Diffusion Models (MDMs) achieve the strongest performance but still underperform AR models in perplexity and lack key inference-time efficiency features--most notably, KV caching. In this work, we introduce Eso-LMs, a new family of models that fuses AR and MDM paradigms, enabling smooth interpolation between their perplexities while overcoming their respective limitations. Eso-LMs set a new state of the art on standard language modeling benchmarks. Crucially, we are the first to introduce KV caching for MDMs while preserving parallel generation, significantly improving inference efficiency. Combined with an optimized sampling schedule, our method achieves up to 65x faster inference than standard MDMs and 4x faster inference than prior semi-autoregressive approaches. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/Eso-LMs
Diffusion과 Autoregressive 모델을 내삽하는 모델. KV 캐시를 허용하고 디노이징할 토큰만 Forward하는 구조로 속도를 더 높였군요.
A model interpolates between diffusion and autoregressive models. It enhances sampling speed by allowing KV caching and only forwarding tokens that need to be denoised.
#diffusion #autoregressive-model
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
(Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, Junyang Lin)
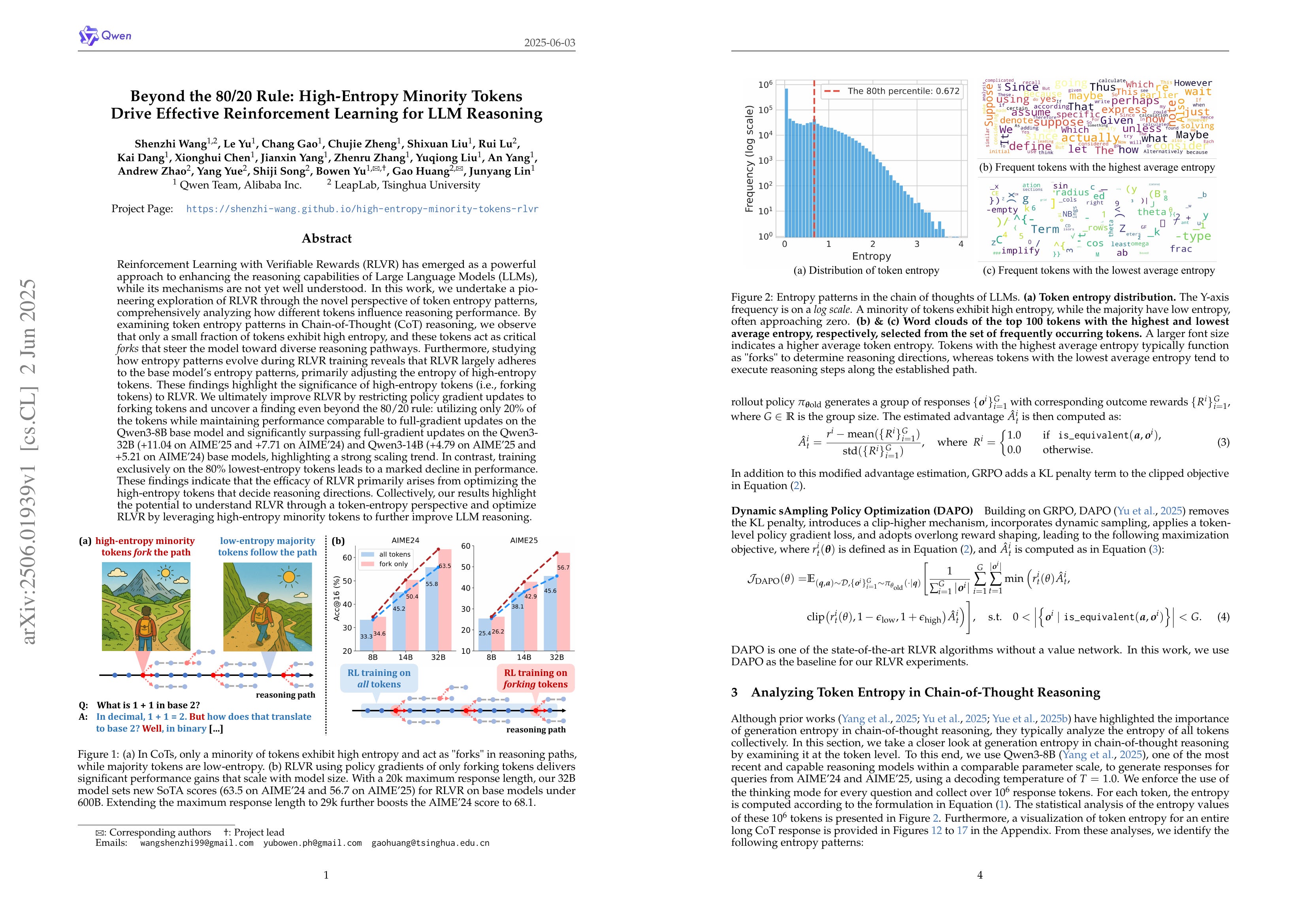
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful approach to enhancing the reasoning capabilities of Large Language Models (LLMs), while its mechanisms are not yet well understood. In this work, we undertake a pioneering exploration of RLVR through the novel perspective of token entropy patterns, comprehensively analyzing how different tokens influence reasoning performance. By examining token entropy patterns in Chain-of-Thought (CoT) reasoning, we observe that only a small fraction of tokens exhibit high entropy, and these tokens act as critical forks that steer the model toward diverse reasoning pathways. Furthermore, studying how entropy patterns evolve during RLVR training reveals that RLVR largely adheres to the base model's entropy patterns, primarily adjusting the entropy of high-entropy tokens. These findings highlight the significance of high-entropy tokens (i.e., forking tokens) to RLVR. We ultimately improve RLVR by restricting policy gradient updates to forking tokens and uncover a finding even beyond the 80/20 rule: utilizing only 20% of the tokens while maintaining performance comparable to full-gradient updates on the Qwen3-8B base model and significantly surpassing full-gradient updates on the Qwen3-32B (+11.04 on AIME'25 and +7.71 on AIME'24) and Qwen3-14B (+4.79 on AIME'25 and +5.21 on AIME'24) base models, highlighting a strong scaling trend. In contrast, training exclusively on the 80% lowest-entropy tokens leads to a marked decline in performance. These findings indicate that the efficacy of RLVR primarily arises from optimizing the high-entropy tokens that decide reasoning directions. Collectively, our results highlight the potential to understand RLVR through a token-entropy perspective and optimize RLVR by leveraging high-entropy minority tokens to further improve LLM reasoning.
추론 과정에서 엔트로피가 높은 토큰들은 소수인데 이 토큰이 중요한 역할을 한다는 분석. 이 엔트로피가 높은 토큰들만 대상으로 RL을 진행했을 때 오히려 성능이 높다고 하네요. 다시 한 번 엔트로피에 대한 이해가 중요하다는 것을 시사하는군요.
An analysis shows that while the proportion of high-entropy tokens during the reasoning process is rather small, these tokens play a crucial role. Interestingly, performing RL only on these high-entropy tokens actually leads to better performance. This once again highlights the importance of understanding entropy in reasoning.
#rl #reasoning