



2025년 6월 24일

ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
(Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, Mengdi Wang)
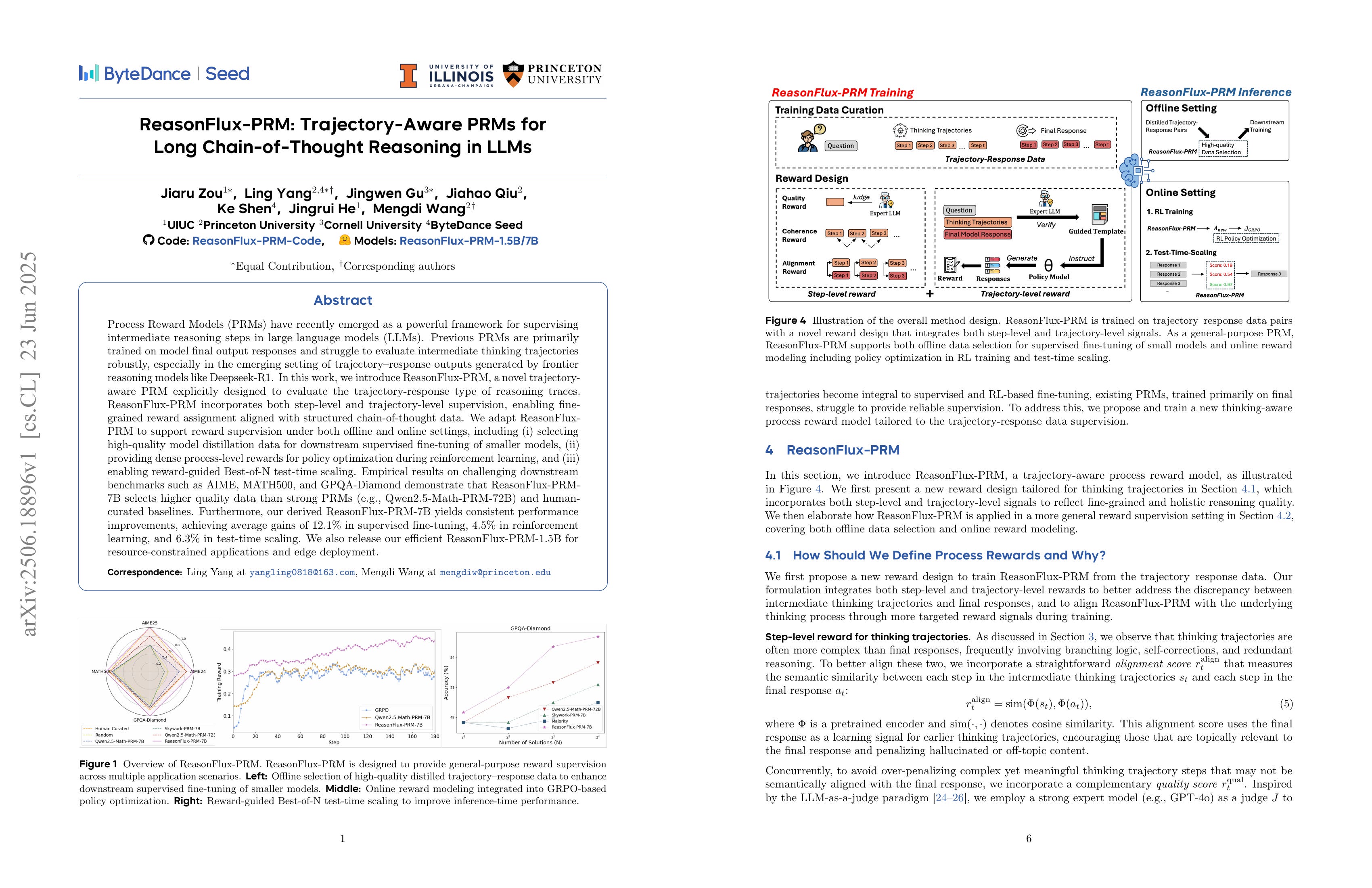
Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model final output responses and struggle to evaluate intermediate thinking trajectories robustly, especially in the emerging setting of trajectory-response outputs generated by frontier reasoning models like Deepseek-R1. In this work, we introduce ReasonFlux-PRM, a novel trajectory-aware PRM explicitly designed to evaluate the trajectory-response type of reasoning traces. ReasonFlux-PRM incorporates both step-level and trajectory-level supervision, enabling fine-grained reward assignment aligned with structured chain-of-thought data. We adapt ReasonFlux-PRM to support reward supervision under both offline and online settings, including (i) selecting high-quality model distillation data for downstream supervised fine-tuning of smaller models, (ii) providing dense process-level rewards for policy optimization during reinforcement learning, and (iii) enabling reward-guided Best-of-N test-time scaling. Empirical results on challenging downstream benchmarks such as AIME, MATH500, and GPQA-Diamond demonstrate that ReasonFlux-PRM-7B selects higher quality data than strong PRMs (e.g., Qwen2.5-Math-PRM-72B) and human-curated baselines. Furthermore, our derived ReasonFlux-PRM-7B yields consistent performance improvements, achieving average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling. We also release our efficient ReasonFlux-PRM-1.5B for resource-constrained applications and edge deployment. Projects: https://github.com/Gen-Verse/ReasonFlux
PRM. 각 단계가 일관된지, 추론의 템플릿이 적절한지 등을 평가하게 했군요.
A PRM. The authors designed it to evaluate aspects such as the coherence between steps and the appropriateness of reasoning templates.
#rl #reasoning #reward-model
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
(Yuhao Wu, Yushi Bai, Zhiqiang Hu, Roy Ka-Wei Lee, Juanzi Li)

Ultra-long generation by large language models (LLMs) is a widely demanded scenario, yet it remains a significant challenge due to their maximum generation length limit and overall quality degradation as sequence length increases. Previous approaches, exemplified by LongWriter, typically rely on ''teaching'', which involves supervised fine-tuning (SFT) on synthetic long-form outputs. However, this strategy heavily depends on synthetic SFT data, which is difficult and costly to construct, often lacks coherence and consistency, and tends to be overly artificial and structurally monotonous. In this work, we propose an incentivization-based approach that, starting entirely from scratch and without relying on any annotated or synthetic data, leverages reinforcement learning (RL) to foster the emergence of ultra-long, high-quality text generation capabilities in LLMs. We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement during the writing process. To support this, we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting. Experimental evaluations show that our LongWriter-Zero model, trained from Qwen2.5-32B, consistently outperforms traditional SFT methods on long-form writing tasks, achieving state-of-the-art results across all metrics on WritingBench and Arena-Write, and even surpassing 100B+ models such as DeepSeek R1 and Qwen3-235B. We open-source our data and model checkpoints under https://huggingface.co/THU-KEG/LongWriter-Zero-32B
SFT 없이 RL로 장문을 생성하는 추론 모델을 학습. Continual Pretraining도 사용했군요.
Training a reasoning model to generate long-form text using RL, without SFT. They also used continual pretraining.
#reasoning #rl
ReDit: Reward Dithering for Improved LLM Policy Optimization
(Chenxing Wei, Jiarui Yu, Ying Tiffany He, Hande Dong, Yao Shu, Fei Yu)

DeepSeek-R1 has successfully enhanced Large Language Model (LLM) reasoning capabilities through its rule-based reward system. While it's a ''perfect'' reward system that effectively mitigates reward hacking, such reward functions are often discrete. Our experimental observations suggest that discrete rewards can lead to gradient anomaly, unstable optimization, and slow convergence. To address this issue, we propose ReDit (Reward Dithering), a method that dithers the discrete reward signal by adding simple random noise. With this perturbed reward, exploratory gradients are continuously provided throughout the learning process, enabling smoother gradient updates and accelerating convergence. The injected noise also introduces stochasticity into flat reward regions, encouraging the model to explore novel policies and escape local optima. Experiments across diverse tasks demonstrate the effectiveness and efficiency of ReDit. On average, ReDit achieves performance comparable to vanilla GRPO with only approximately 10% the training steps, and furthermore, still exhibits a 4% performance improvement over vanilla GRPO when trained for a similar duration. Visualizations confirm significant mitigation of gradient issues with ReDit. Moreover, theoretical analyses are provided to further validate these advantages.
Reward에 노이즈를 추가하는 것으로 학습 속도를 가속시킬 수 있다는 연구군요 (https://www.arxiv.org/abs/2506.08737).
This study shows that adding noise to rewards can accelerate the training speed (https://www.arxiv.org/abs/2506.08737).
#rl #reasoning
RLPR: Extrapolating RLVR to General Domains without Verifiers
(Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, Tat-Seng Chua)

Reinforcement Learning with Verifiable Rewards (RLVR) demonstrates promising potential in advancing the reasoning capabilities of LLMs. However, its success remains largely confined to mathematical and code domains. This primary limitation stems from the heavy reliance on domain-specific verifiers, which results in prohibitive complexity and limited scalability. To address the challenge, our key observation is that LLM's intrinsic probability of generating a correct free-form answer directly indicates its own evaluation of the reasoning reward (i.e., how well the reasoning process leads to the correct answer). Building on this insight, we propose RLPR, a simple verifier-free framework that extrapolates RLVR to broader general domains. RLPR uses the LLM's own token probability scores for reference answers as the reward signal and maximizes the expected reward during training. We find that addressing the high variance of this noisy probability reward is crucial to make it work, and propose prob-to-reward and stabilizing methods to ensure a precise and stable reward from LLM intrinsic probabilities. Comprehensive experiments in four general-domain benchmarks and three mathematical benchmarks show that RLPR consistently improves reasoning capabilities in both areas for Gemma, Llama, and Qwen based models. Notably, RLPR outperforms concurrent VeriFree by 7.6 points on TheoremQA and 7.5 points on Minerva, and even surpasses strong verifier-model-dependent approaches General-Reasoner by 1.6 average points across seven benchmarks.
추론 결과에 대한 정답의 확률을 LM으로 계산해 Reward를 부여해서 도메인을 확장하는 방법. 얼마 전에도 비슷한 방법이 나왔죠 (https://arxiv.org/abs/2506.13351).
A method to expand domains by assigning rewards based on the probability of correct answers calculated by LMs for reasoning outputs. A similar approach was recently published (https://arxiv.org/abs/2506.13351).
#rl #reasoning
Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
(Jiaming Han, Hao Chen, Yang Zhao, Hanyu Wang, Qi Zhao, Ziyan Yang, Hao He, Xiangyu Yue, Lu Jiang)

This paper presents a multimodal framework that attempts to unify visual understanding and generation within a shared discrete semantic representation. At its core is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a large language model's (LLM) vocabulary. By integrating vision and text into a unified space with an expanded vocabulary, our multimodal LLM, Tar, enables cross-modal input and output through a shared interface, without the need for modality-specific designs. Additionally, we propose scale-adaptive encoding and decoding to balance efficiency and visual detail, along with a generative de-tokenizer to produce high-fidelity visual outputs. To address diverse decoding needs, we utilize two complementary de-tokenizers: a fast autoregressive model and a diffusion-based model. To enhance modality fusion, we investigate advanced pre-training tasks, demonstrating improvements in both visual understanding and generation. Experiments across benchmarks show that Tar matches or surpasses existing multimodal LLM methods, achieving faster convergence and greater training efficiency. Code, models, and data are available at
https://tar.csuhan.com
텍스트 토큰과 정렬시킨 Discrete 이미지 토큰으로 인식과 생성을 수행하는 모델이군요.
An image understanding and generation model that uses discrete image tokens aligned with text tokens.
#multimodal #image-generation #autoregressive-model #diffusion
The 4th Dimension for Scaling Model Size
(Ruike Zhu, Hanwen Zhang, Tianyu Shi, Chi Wang, Tianyi Zhou, Zengyi Qin)

Scaling the size of large language models typically involves three dimensions: depth, width, and the number of parameters. In this work, we explore a fourth dimension, virtual logical depth (VLD), which increases the effective algorithmic depth without changing the overall parameter count by reusing parameters within the model. Although parameter reuse is not a new concept, its potential and characteristics in model scaling have not been thoroughly studied. Through carefully designed controlled experiments, we make the following key discoveries regarding VLD scaling: VLD scaling forces the knowledge capacity of the model to remain almost constant, with only minor variations. VLD scaling enables a significant improvement in reasoning capability, provided the scaling method is properly implemented. The number of parameters correlates with knowledge capacity, but not with reasoning capability. Under certain conditions, it is not necessary to increase the parameter count to enhance reasoning. These findings are consistent across various model configurations and are likely to be generally valid within the scope of our experiments.
레이어 재사용으로 모델을 확장했을 때 저장하는 정보의 양은 고정하면서 추론의 능력을 향상시킬 수 있다는 연구.
This research demonstrates that by expanding a model through layer reuse, it's possible to enhance reasoning capabilities while maintaining a fixed knowledge capacity.
#transformer