



2025년 6월 19일

Truncated Proximal Policy Optimization
(Tiantian Fan, Lingjun Liu, Yu Yue, Jiaze Chen, Chengyi Wang, Qiying Yu, Chi Zhang, Zhiqi Lin, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Bole Ma, Mofan Zhang, Gaohong Liu, Ru Zhang, Haotian Zhou, Cong Xie, Ruidong Zhu, Zhi Zhang, Xin Liu, Mingxuan Wang, Lin Yan, Yonghui Wu)

Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
PPO의 학습 효율화. 생성이 끝나지 않은 궤적에 대해서도 Policy를 학습시키는 것이 요점이군요.
Efficiency improvement for PPO training. The key point is training the policy on trajectories where generation is not yet complete.
#rl #efficiency
ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
(Feng He, Zijun Chen, Xinnian Liang, Tingting Ma, Yunqi Qiu, Shuangzhi Wu, Junchi Yan)

Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought (Long CoT) reasoning have demonstrated remarkable cross-domain generalization capabilities. However, the underlying mechanisms supporting such transfer remain poorly understood. We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes -- fundamental reasoning patterns that capture the essence of problems across domains. These prototypes minimize the nuances of the representation, revealing that seemingly diverse tasks are grounded in shared reasoning structures.Based on this hypothesis, we propose ProtoReasoning, a framework that enhances the reasoning ability of LLMs by leveraging scalable and verifiable prototypical representations (Prolog for logical reasoning, PDDL for planning).ProtoReasoning features: (1) an automated prototype construction pipeline that transforms problems into corresponding prototype representations; (2) a comprehensive verification system providing reliable feedback through Prolog/PDDL interpreters; (3) the scalability to synthesize problems arbitrarily within prototype space while ensuring correctness. Extensive experiments show that ProtoReasoning achieves 4.7% improvement over baseline models on logical reasoning (Enigmata-Eval), 6.3% improvement on planning tasks, 4.0% improvement on general reasoning (MMLU) and 1.0% on mathematics (AIME24). Significantly, our ablation studies confirm that learning in prototype space also demonstrates enhanced generalization to structurally similar problems compared to training solely on natural language representations, validating our hypothesis that reasoning prototypes serve as the foundation for generalizable reasoning in large language models.
프롤로그 같은 언어로 논리 추론을 학습시키면 이 추론 능력이 다른 도메인에서도 작동하지 않겠는가 하는 아이디어. 다양한 도메인과 Verifier를 사용하는 것은 좋은 일이겠죠. 물론 그 모든 것을 통합하는 Objective가 있을지도 모르겠습니다만.
하루키, 토우마, 세츠나가 대체 누구인가 했는데 꽤 고전적인 게임의 캐릭터들인 것 같군요.
The idea is that training logical reasoning using languages like Prolog might develop transferable reasoning capabilities that could work across different domains. It's a good to use diverse domains and verifiers. Of course, there might be an objective that unifies all of these elements.
I was wondering who Haruki, Touma, and Setsuna were, but it seems they're characters from a fairly classic game.
#reasoning #rl
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
(Zhoujun Cheng, Shibo Hao, Tianyang Liu, Fan Zhou, Yutao Xie, Feng Yao, Yuexin Bian, Yonghao Zhuang, Nilabjo Dey, Yuheng Zha, Yi Gu, Kun Zhou, Yuqi Wang, Yuan Li, Richard Fan, Jianshu She, Chengqian Gao, Abulhair Saparov, Haonan Li, Taylor W. Killian, Mikhail Yurochkin, Zhengzhong Liu, Eric P. Xing, Zhiting Hu)
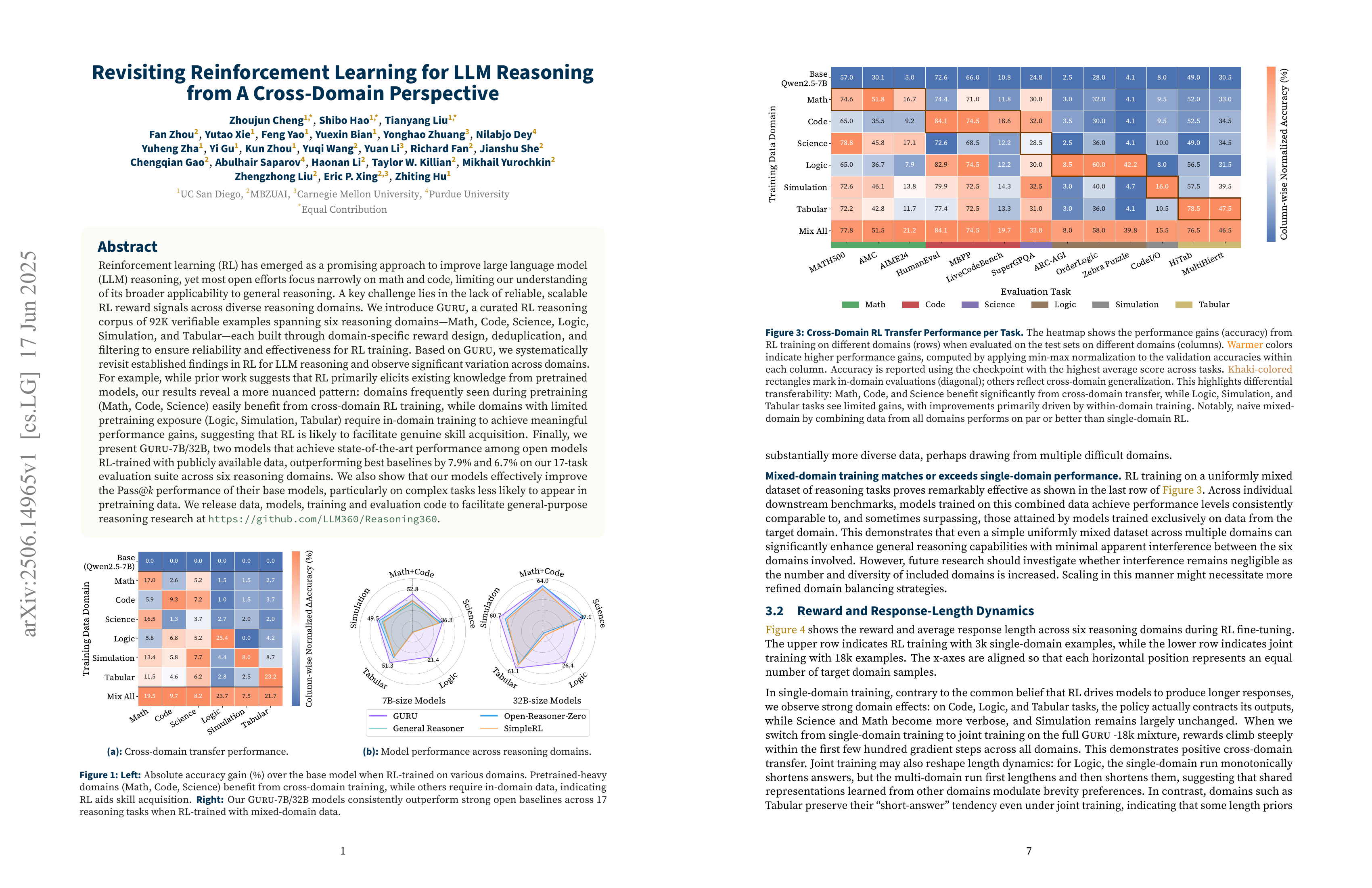
Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
다양한 도메인의 데이터로 RL을 진행했을 때 추론 능력이 다른 도메인에서 어떻게 나타나는지에 대한 연구. 프리트레이닝에 많이 포함된 수학, 코드, 과학의 경우에는 다른 도메인으로 학습해도 성능 향상이 뚜렷한데 많이 포함되지 않은 도메인은 그 도메인의 데이터가 필요하군요. 그런데 이걸 반대로 RL을 통해 프리트레이닝에 많이 포함되지 않은 도메인에 대해서도 능력을 함양할 수 있다는 증거로 분석했네요.
This study investigates how reasoning abilities emerge across different domains when RL is applied to diverse data domains. Domains heavily represented in pretraining, such as math, code, and science, show clear performance improvements even when trained on data from other domains. However, domains less prevalent in pretraining require domain-specific data for significant improvements. Interestingly, the authors interpret this finding as evidence that RL can potentially enhance capabilities in domains underrepresented in pretraining data.
#rlhf #reasoning
RATTENTION: Towards the Minimal Sliding Window Size in Local-Global Attention Models
(Bailin Wang, Chang Lan, Chong Wang, Ruoming Pang)

Local-global attention models have recently emerged as compelling alternatives to standard Transformers, promising improvements in both training and inference efficiency. However, the crucial choice of window size presents a Pareto tradeoff: larger windows maintain performance akin to full attention but offer minimal efficiency gains in short-context scenarios, while smaller windows can lead to performance degradation. Current models, such as Gemma2 and Mistral, adopt conservative window sizes (e.g., 4096 out of an 8192 pretraining length) to preserve performance. This work investigates strategies to shift this Pareto frontier, enabling local-global models to achieve efficiency gains even in short-context regimes. Our core motivation is to address the intrinsic limitation of local attention -- its complete disregard for tokens outside the defined window. We explore RATTENTION, a variant of local attention integrated with a specialized linear attention mechanism designed to capture information from these out-of-window tokens. Pretraining experiments at the 3B and 12B scales demonstrate that RATTENTION achieves a superior Pareto tradeoff between performance and efficiency. As a sweet spot, RATTENTION with a window size of just 512 consistently matches the performance of full-attention models across diverse settings. Furthermore, the recurrent nature inherent in the linear attention component of RATTENTION contributes to enhanced long-context performance, as validated on the RULER benchmark. Crucially, these improvements do not compromise training efficiency; thanks to a specialized kernel implementation and the reduced window size, RATTENTION maintains training speeds comparable to existing state-of-the-art approaches.
Local-Global Attention의 하이브리드에서 최적 Local Window의 크기는 무엇인가? 여기서는 단순히 Local Attention을 쓰지는 않고 Linear Attention도 결합했군요.
What is the optimal size of the local window in local-global attention hybrids? This work doesn't simply use local attention, but also combines it with linear attention.
#transformer #efficiency
Optimal Embedding Learning Rate in LLMs: The Effect of Vocabulary Size
(Soufiane Hayou, Liyuan Liu)

Pretraining large language models is a costly process. To make this process more efficient, several methods have been proposed to optimize model architecture/parametrization and hardware use. On the parametrization side, μP (Maximal Update Parametrization) parametrizes model weights and learning rate (LR) in a way that makes hyperparameters (HPs) transferable with width (embedding dimension): HPs can be tuned for a small model and used for larger models without additional tuning. While μP showed impressive results in practice, recent empirical studies have reported conflicting observations when applied to LLMs. One limitation of the theory behind μP is the fact that input dimension (vocabulary size in LLMs) is considered fixed when taking the width to infinity. This is unrealistic since vocabulary size is generally much larger than width in practice. In this work, we provide a theoretical analysis of the effect of vocabulary size on training dynamics, and subsequently show that as vocabulary size increases, the training dynamics interpolate between the μP regime and another regime that we call Large Vocab (LV) Regime, where optimal scaling rules are different from those predicted by μP. Our analysis reveals that in the LV regime, the optimal embedding LR to hidden LR ratio should roughly scale as Θ(sqrt(width)), surprisingly close to the empirical findings previously reported in the literature, and different from the Θ(width) ratio predicted by μP. We conduct several experiments to validate our theory, and pretrain a 1B model from scratch to show the benefit of our suggested scaling rule for the embedding LR.
임베딩 LR을 sqrt(dim)으로 맞춰주는 것이 좋다는 연구. 이런 Parameterization을 보면 최초의 트랜스포머의 세팅에 대해 생각하게 되네요.
This study suggests that scaling the embedding LR by sqrt(dim) is beneficial. When considering such parameterizations, it reminds me of the original settings used in the first transformer model.
#optimization