



2025년 6월 18일

Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.
(Gemini Team, Google)

In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable model yet, achieving SoTA performance on frontier coding and reasoning benchmarks. In addition to its incredible coding and reasoning skills, Gemini 2.5 Pro is a thinking model that excels at multimodal understanding and it is now able to process up to 3 hours of video content. Its unique combination of long context, multimodal and reasoning capabilities can be combined to unlock new agentic workflows. Gemini 2.5 Flash provides excellent reasoning abilities at a fraction of the compute and latency requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together, the Gemini 2.X model generation spans the full Pareto frontier of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving.
제미나이 2.5의 테크 리포트가 나왔군요. 힌트 정도는 있긴 합니다.
The technical report for Gemini 2.5 has been released. It provides some hints about the model.
#llm
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs
(Xumeng Wen, Zihan Liu, Shun Zheng, Zhijian Xu, Shengyu Ye, Zhirong Wu, Xiao Liang, Yang Wang, Junjie Li, Ziming Miao, Jiang Bian, Mao Yang)

Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising paradigm for advancing the reasoning capabilities of Large Language Models (LLMs). However, a critical paradox clouds its efficacy: RLVR-tuned models often underperform their base models on the Pass@K metric for solution-finding, leading to the hypothesis that RLVR merely re-weights existing reasoning paths at the cost of reasoning diversity. In this work, we resolve this contradiction by identifying the source of the problem: the Pass@K metric itself is a flawed measure of reasoning, as it credits correct final answers that probably arise from inaccurate or incomplete chains of thought (CoTs). To address this, we introduce a more precise evaluation metric, CoT-Pass@K, which mandates that both the reasoning path and the final answer be correct. We provide a new theoretical foundation that formalizes how RLVR, unlike traditional RL, is uniquely structured to incentivize logical integrity. Our empirical results are supportive: using CoT-Pass@K, we observe that RLVR can incentivize the generalization of correct reasoning for all values of K. Furthermore, by analyzing the training dynamics, we find that this enhanced reasoning capability emerges early in the training process and smoothly generalizes. Our work provides a clear perspective on the role of RLVR, offers a more reliable method for its evaluation, and confirms its potential to genuinely advance machine reasoning.
Pass@K를 기반으로 추론 RL이 정답에 필요한 샘플의 수와 다양성을 감소시키는 형태로 동작한다는 주장이 있었죠 (https://arxiv.org/abs/2504.13837). 여기서는 CoT의 내용이 올바른지도 체크하면 패턴이 달라진다는 주장을 합니다. 사실 Pass@K 자체가 베이스라인에 대한 고려가 필요한 지표죠 (https://arxiv.org/abs/2410.15466).
There was a claim that reasoning-based RL operates by reducing the number of samples needed for correct answers and decreasing diversity, based on the Pass@K metric (https://arxiv.org/abs/2504.13837). This study argues that the pattern changes if we also check whether the content of the CoT itself is correct. In fact, Pass@K is a metric that inherently requires consideration of the baseline performance (https://arxiv.org/abs/2410.15466).
#rl #reasoning
Essential-Web v1.0: 24T tokens of organized web data
(Essential AI: Andrew Hojel, Michael Pust, Tim Romanski, Yash Vanjani, Ritvik Kapila, Mohit Parmar, Adarsh Chaluvaraju, Alok Tripathy, Anil Thomas, Ashish Tanwer, Darsh J Shah, Ishaan Shah, Karl Stratos, Khoi Nguyen, Kurt Smith, Michael Callahan, Peter Rushton, Philip Monk, Platon Mazarakis, Saad Jamal, Saurabh Srivastava, Somanshu Singla, Ashish Vaswani)

Data plays the most prominent role in how language models acquire skills and knowledge. The lack of massive, well-organized pre-training datasets results in costly and inaccessible data pipelines. We present Essential-Web v1.0, a 24-trillion-token dataset in which every document is annotated with a twelve-category taxonomy covering topic, format, content complexity, and quality. Taxonomy labels are produced by EAI-Distill-0.5b, a fine-tuned 0.5b-parameter model that achieves an annotator agreement within 3% of Qwen2.5-32B-Instruct. With nothing more than SQL-style filters, we obtain competitive web-curated datasets in math (-8.0% relative to SOTA), web code (+14.3%), STEM (+24.5%) and medical (+8.6%). Essential-Web v1.0 is available on HuggingFace: https://huggingface.co/datasets/EssentialAI/essential-web-v1.0
Common Crawl에서 추출한 24B 문서, 24T 토큰에 대해 카테고리를 부여해 큐레이션했네요. 요즘 대세인 LLM 기반 전처리에 대한 상세한 리포트군요.
The authors have curated 24B documents and 24T tokens extracted from Common Crawl by assigning categories to them. This is a detailed report on LLM-based preprocessing, which is currently the mainstream approach.
#pretraining #corpus
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
(Ring Team, Bin Hu, Cai Chen, Deng Zhao, Ding Liu, Dingnan Jin, Feng Zhu, Hao Dai, Hongzhi Luan, Jia Guo, Jiaming Liu, Jiewei Wu, Jun Mei, Jun Zhou, Junbo Zhao, Junwu Xiong, Kaihong Zhang, Kuan Xu, Lei Liang, Liang Jiang, Liangcheng Fu, Longfei Zheng, Qiang Gao, Qing Cui, Quan Wan, Shaomian Zheng, Shuaicheng Li, Tongkai Yang, Wang Ren, Xiaodong Yan, Xiaopei Wan, Xiaoyun Feng, Xin Zhao, Xinxing Yang, Xinyu Kong, Xuemin Yang, Yang Li, Yingting Wu, Yongkang Liu, Zhankai Xu, Zhenduo Zhang, Zhenglei Zhou, Zhenyu Huang, Zhiqiang Zhang, Zihao Wang, Zujie Wen)

We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Ant Group의 추론 모델. 길이에 따른 업데이트 차이 문제를 해소하려고 시도했군요. 토큰 예산에 맞춰 잘라버리는 방식을 썼네요.
Ant Group's reasoning model. They attempted to address the issue of update differences caused by varying sequence lengths. They employed a method of truncating sequences to fit within token budgets.
#rl #reasoning
From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
(Mathurin Videau, Badr Youbi Idrissi, Alessandro Leite, Marc Schoenauer, Olivier Teytaud, David Lopez-Paz)

Tokenization imposes a fixed granularity on the input text, freezing how a language model operates on data and how far in the future it predicts. Byte Pair Encoding (BPE) and similar schemes split text once, build a static vocabulary, and leave the model stuck with that choice. We relax this rigidity by introducing an autoregressive U-Net that learns to embed its own tokens as it trains. The network reads raw bytes, pools them into words, then pairs of words, then up to 4 words, giving it a multi-scale view of the sequence. At deeper stages, the model must predict further into the future -- anticipating the next few words rather than the next byte -- so deeper stages focus on broader semantic patterns while earlier stages handle fine details. When carefully tuning and controlling pretraining compute, shallow hierarchies tie strong BPE baselines, and deeper hierarchies have a promising trend. Because tokenization now lives inside the model, the same system can handle character-level tasks and carry knowledge across low-resource languages.
바이트 UNet 형태의 시퀀스 모델인데 풀링에서 시퀀스를 쪼개는 메커니즘을 요구하는군요. 여기서는 공백으로 쪼개고 있습니다.
A byte-level U-Net style sequence model, and it requires a mechanism for splitting sequences during pooling. In this study, they used a space-based splitter.
#transformer #llm
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs
(Xiaoran Liu, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, Xipeng Qiu)
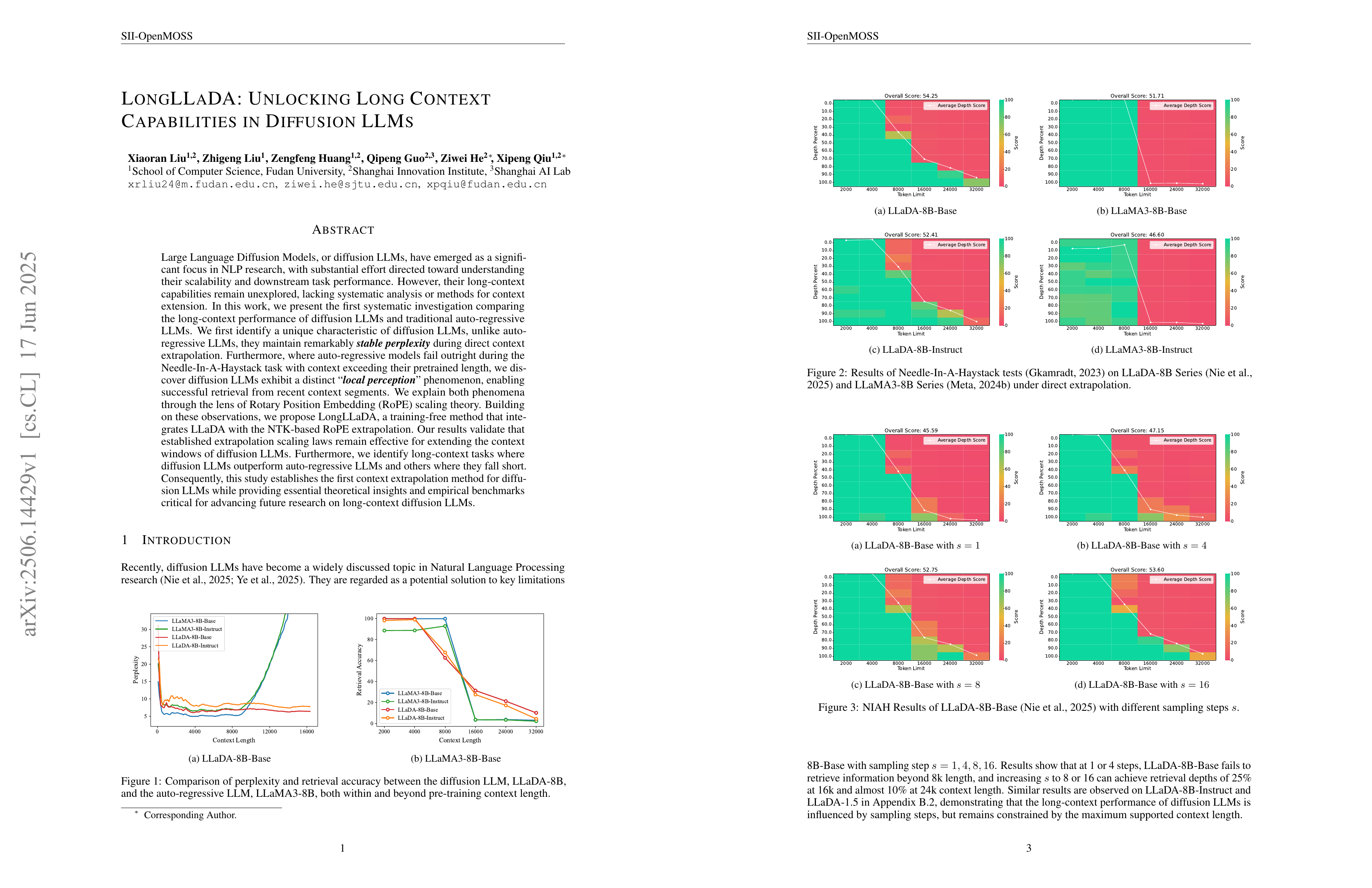
Large Language Diffusion Models, or diffusion LLMs, have emerged as a significant focus in NLP research, with substantial effort directed toward understanding their scalability and downstream task performance. However, their long-context capabilities remain unexplored, lacking systematic analysis or methods for context extension. In this work, we present the first systematic investigation comparing the long-context performance of diffusion LLMs and traditional auto-regressive LLMs. We first identify a unique characteristic of diffusion LLMs, unlike auto-regressive LLMs, they maintain remarkably stable perplexity during direct context extrapolation. Furthermore, where auto-regressive models fail outright during the Needle-In-A-Haystack task with context exceeding their pretrained length, we discover diffusion LLMs exhibit a distinct local perception phenomenon, enabling successful retrieval from recent context segments. We explain both phenomena through the lens of Rotary Position Embedding (RoPE) scaling theory. Building on these observations, we propose LongLLaDA, a training-free method that integrates LLaDA with the NTK-based RoPE extrapolation. Our results validate that established extrapolation scaling laws remain effective for extending the context windows of diffusion LLMs. Furthermore, we identify long-context tasks where diffusion LLMs outperform auto-regressive LLMs and others where they fall short. Consequently, this study establishes the first context extrapolation method for diffusion LLMs while providing essential theoretical insights and empirical benchmarks critical for advancing future research on long-context diffusion LLMs.
Diffusion LM의 Long Context 상황에서의 특성 분석. Bidirectional Attention과 RoPE의 조합으로 인해 상당히 다른 특성이 나타나는군요.
Analysis of diffusion LM characteristics in long context. The combination of bidirectional attention and RoPE results in notably distinct features.
#long-context #diffusion
Load Balancing Mixture of Experts with Similarity Preserving Routers
(Nabil Omi, Siddhartha Sen, Ali Farhadi)
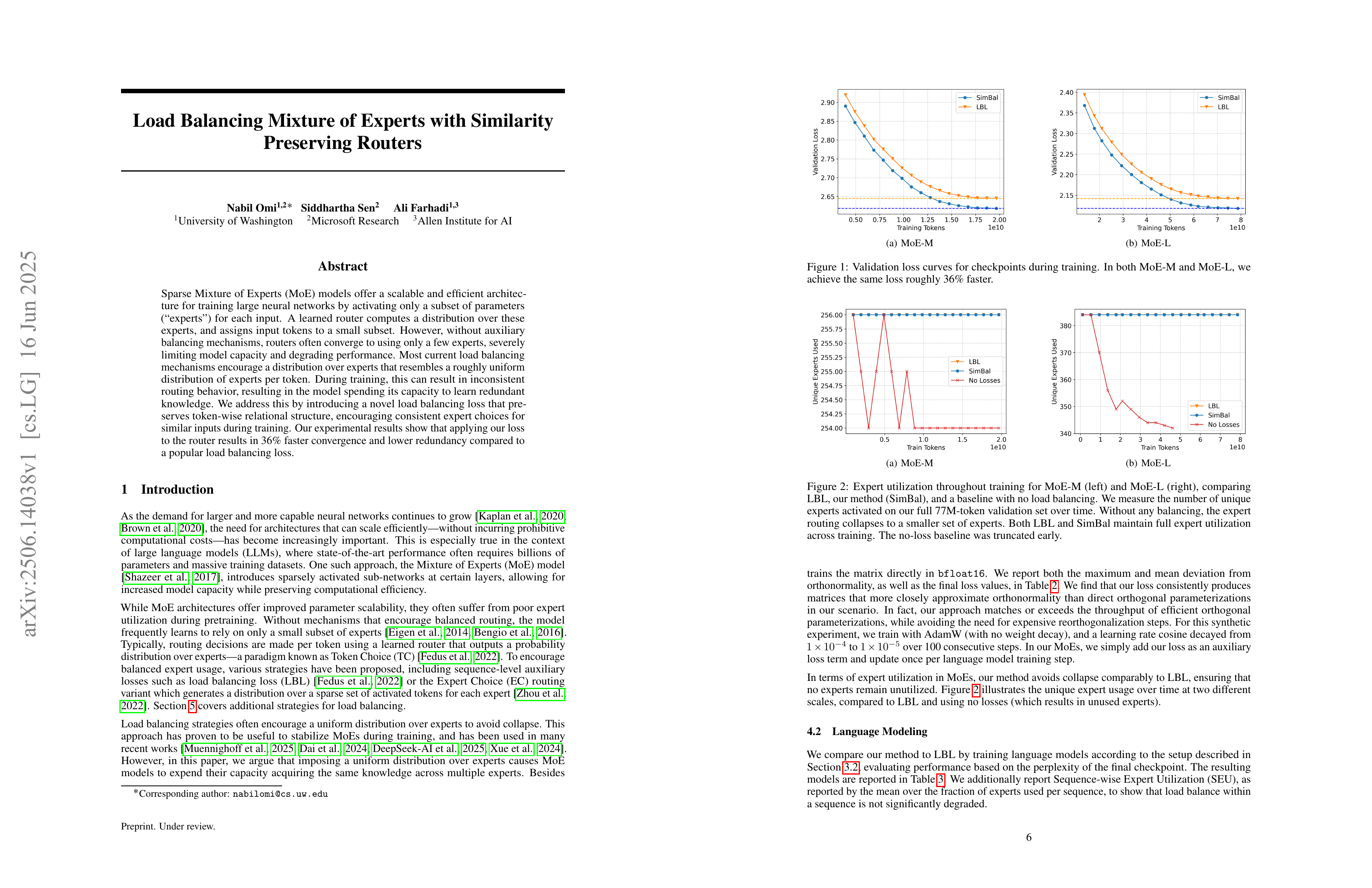
Sparse Mixture of Experts (MoE) models offer a scalable and efficient architecture for training large neural networks by activating only a subset of parameters ("experts") for each input. A learned router computes a distribution over these experts, and assigns input tokens to a small subset. However, without auxiliary balancing mechanisms, routers often converge to using only a few experts, severely limiting model capacity and degrading performance. Most current load balancing mechanisms encourage a distribution over experts that resembles a roughly uniform distribution of experts per token. During training, this can result in inconsistent routing behavior, resulting in the model spending its capacity to learn redundant knowledge. We address this by introducing a novel load balancing loss that preserves token-wise relational structure, encouraging consistent expert choices for similar inputs during training. Our experimental results show that applying our loss to the router results in 36% faster convergence and lower redundancy compared to a popular load balancing loss.
MoE 라우터 가중치를 직교 행렬로 정규화하는 형태의 Load Balancing. 실제 Load Balancing이 얼마나 잘 되는지가 궁금하네요.
A load balancing method that regularizes the MoE router weights to form an orthogonal matrix. I wonder how effectively this approach actually balances the loads.
#moe