



2025년 6월 17일

MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
(MiniMax)
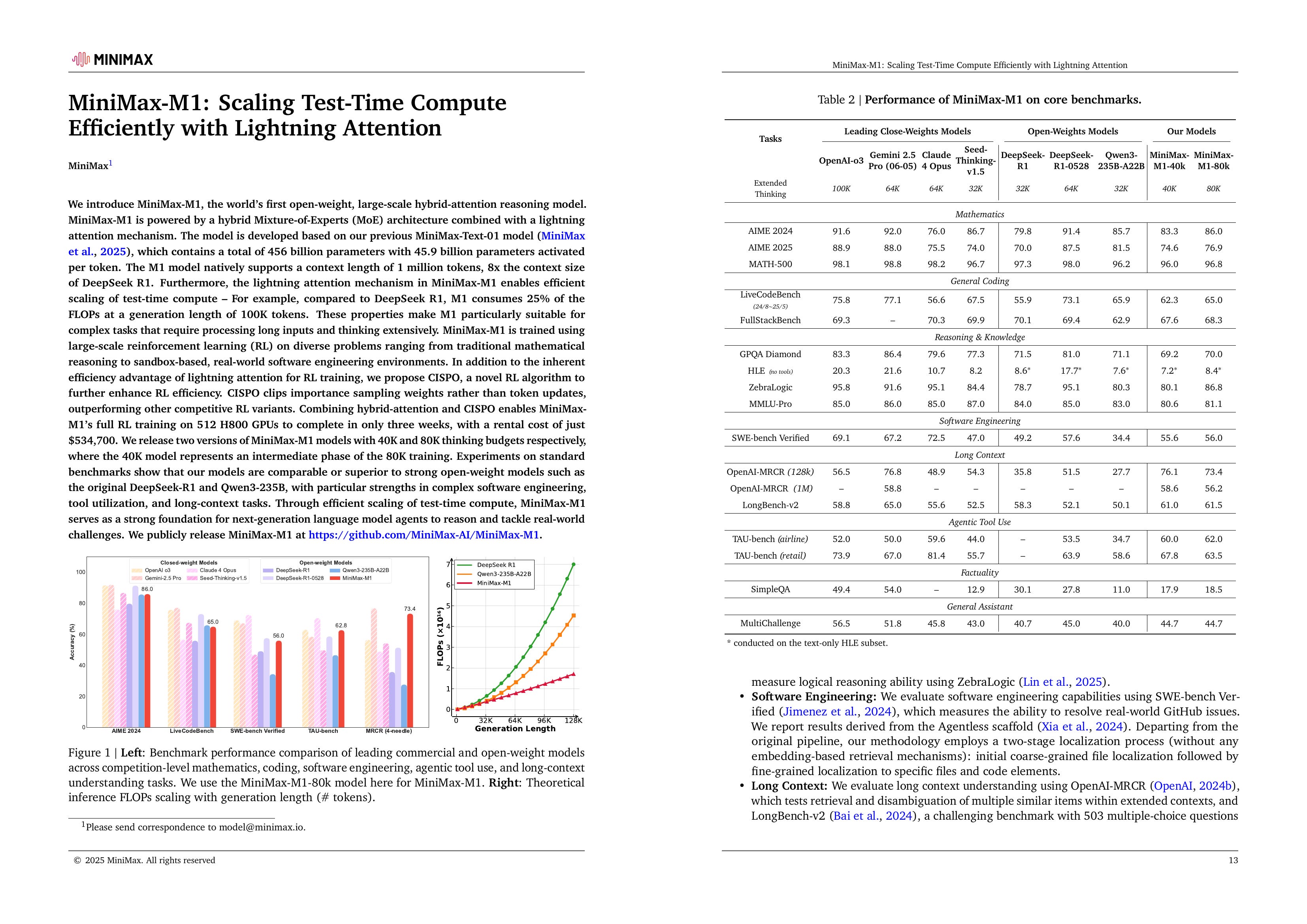
We introduce MiniMax-M1, the world’s first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model (MiniMax et al., 2025), which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute – For example, compared to DeepSeek R1, M1 consumes 25% of the FLOPs at a generation length of 100K tokens. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems ranging from traditional mathematical reasoning to sandbox-based, real-world software engineering environments. In addition to the inherent efficiency advantage of lightning attention for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax- M1’s full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. Through efficient scaling of test-time compute, MiniMax-M1 serves as a strong foundation for next-generation language model agents to reason and tackle real-world challenges. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax의 추론 모델. 7.5T를 추가 학습해서 총 19T 정도를 학습했군요. 재미있게도 합성 데이터를 의도적으로 배제했다고 언급하고 있네요.
RL 알고리즘에서는 토큰 업데이트를 클리핑하는 것이 아니라 Importance Sampling 가중치를 클리핑하는 방법을 썼군요. 학습-추론 갭도 그렇고 하이브리드 모델에서 발생하는 난점이 조금 있는 것 같습니다.
MiniMax's reasoning model. They've trained an additional 7.5T, bringing the total training to about 19T. Interestingly, they intentionally excluded synthetic data.
For their RL algorithm, instead of clipping token updates, they clipped importance sampling weights. It seems there are some challenges arising from the hybrid model, including the training-inference gap.
#reasoning #rl
Can Mixture-of-Experts Surpass Dense LLMs Under Strictly Equal Resources?
(Houyi Li, Ka Man Lo, Ziqi Wang, Zili Wang, Wenzhen Zheng, Shuigeng Zhou, Xiangyu Zhang, Daxin Jiang)

Mixture-of-Experts (MoE) language models dramatically expand model capacity and achieve remarkable performance without increasing per-token compute. However, can MoEs surpass dense architectures under strictly equal resource constraints - that is, when the total parameter count, training compute, and data budget are identical? This question remains under-explored despite its significant practical value and potential. In this paper, we propose a novel perspective and methodological framework to study this question thoroughly. First, we comprehensively investigate the architecture of MoEs and achieve an optimal model design that maximizes the performance. Based on this, we subsequently find that an MoE model with activation rate in an optimal region is able to outperform its dense counterpart under the same total parameter, training compute and data resource. More importantly, this optimal region remains consistent across different model sizes. Although additional amount of data turns out to be a trade-off for the enhanced performance, we show that this can be resolved via reusing data. We validate our findings through extensive experiments, training nearly 200 language models at 2B scale and over 50 at 7B scale, cumulatively processing 50 trillion tokens. All models will be released publicly.
MoE vs Dense. 총 파라미터가 동일한 경우에도 최적 아키텍처 세팅 하에서는 동일 연산량에서 MoE가 Dense보다 우수하다는 결과. 최적 아키텍처가 비전형적이긴 하네요 (K = 1). Activated Weight의 비율은 20% 정도가 최적이라는 결론.
동일 연산량이기 때문에 데이터를 더 써야 하는데 이 부분은 Multi Epoch로 극복이 가능할 것이라고 추정.
MoE vs Dense. The results show that under optimal architectural settings, MoE outperforms dense models even with the same total number of parameters and computational resources. The optimal architecture is somewhat unconventional (K = 1). The study concludes that the optimal ratio of activated weights is around 20%.
Since the comparison is made under equal computational resources, it requires more data. The authors suggest that this can be overcome by using multiple epochs.
#moe
Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks
(Yifei Xu, Tusher Chakraborty, Srinagesh Sharma, Leonardo Nunes, Emre Kıcıman, Songwu Lu, Ranveer Chandra)

Recent advances in Large Language Models (LLMs) have showcased impressive reasoning abilities in structured tasks like mathematics and programming, largely driven by Reinforcement Learning with Verifiable Rewards (RLVR), which uses outcome-based signals that are scalable, effective, and robust against reward hacking. However, applying similar techniques to open-ended long-form reasoning tasks remains challenging due to the absence of generic, verifiable reward signals. To address this, we propose Direct Reasoning Optimization (DRO), a reinforcement learning framework for fine-tuning LLMs on open-ended, particularly long-form, reasoning tasks, guided by a new reward signal: the Reasoning Reflection Reward (R3). At its core, R3 selectively identifies and emphasizes key tokens in the reference outcome that reflect the influence of the model's preceding chain-of-thought reasoning, thereby capturing the consistency between reasoning and reference outcome at a fine-grained level. Crucially, R3 is computed internally using the same model being optimized, enabling a fully self-contained training setup. Additionally, we introduce a dynamic data filtering strategy based on R3 for open-ended reasoning tasks, reducing cost while improving downstream performance. We evaluate DRO on two diverse datasets -- ParaRev, a long-form paragraph revision task, and FinQA, a math-oriented QA benchmark -- and show that it consistently outperforms strong baselines while remaining broadly applicable across both open-ended and structured domains.
LM에 추론을 컨텍스트로 제공했을 때의 정답의 확률을 사용해서 보상을 주는 방법에 대한 개선. 정답 토큰들 중에서 실제로 추론에 영향을 크게 받는 토큰들을 구분해서 사용한다는 아이디어군요.
This paper presents an improvement on the method of assigning rewards by using the probability of the correct answer when reasoning is provided as context to LM. The key idea is to identify and utilize specific tokens from the answer that are most significantly influenced by the reasoning.
#reasoning #rl
AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy
(Zihan Liu, Zhuolin Yang, Yang Chen, Chankyu Lee, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping)
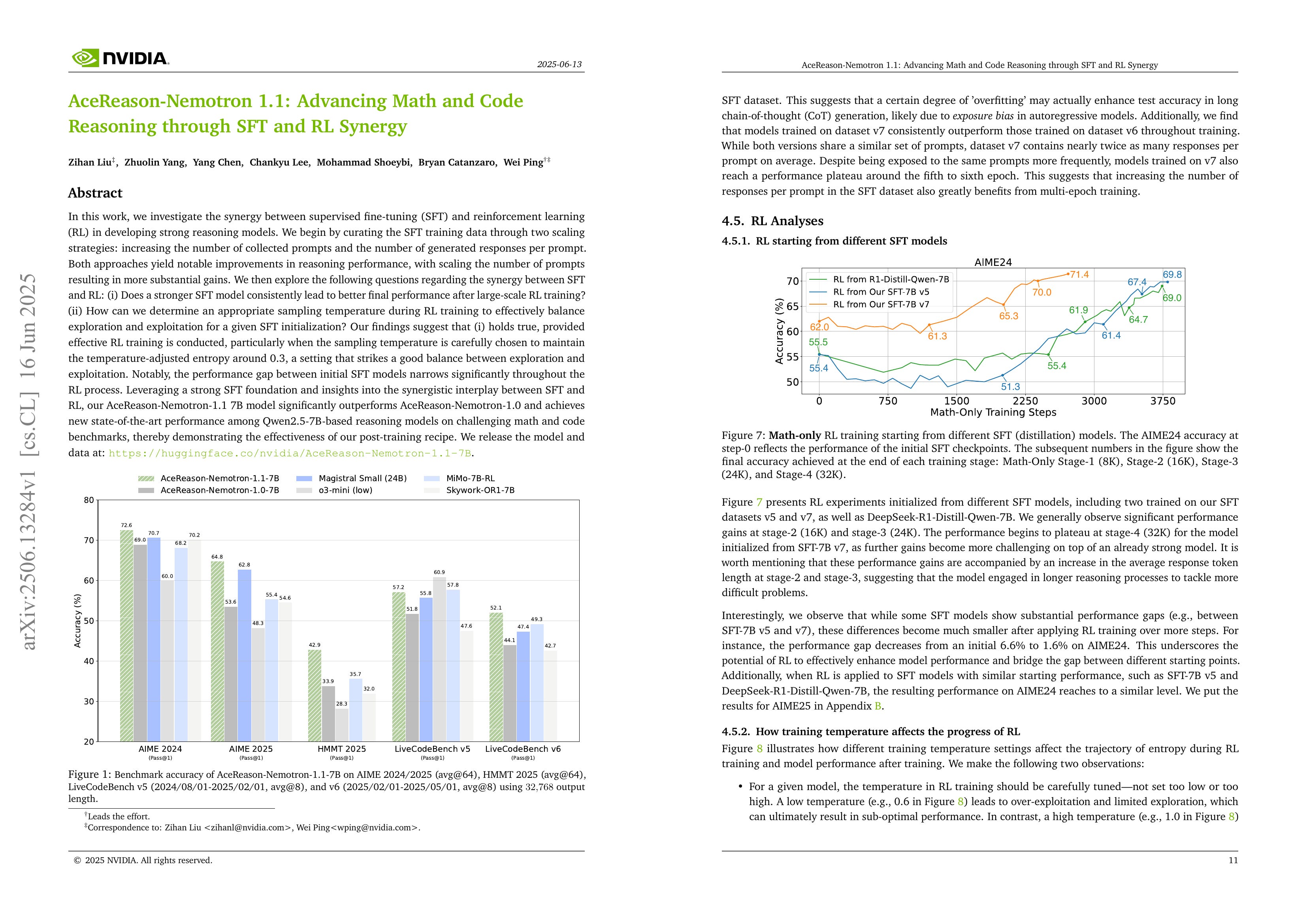
In this work, we investigate the synergy between supervised fine-tuning (SFT) and reinforcement learning (RL) in developing strong reasoning models. We begin by curating the SFT training data through two scaling strategies: increasing the number of collected prompts and the number of generated responses per prompt. Both approaches yield notable improvements in reasoning performance, with scaling the number of prompts resulting in more substantial gains. We then explore the following questions regarding the synergy between SFT and RL: (i) Does a stronger SFT model consistently lead to better final performance after large-scale RL training? (ii) How can we determine an appropriate sampling temperature during RL training to effectively balance exploration and exploitation for a given SFT initialization? Our findings suggest that (i) holds true, provided effective RL training is conducted, particularly when the sampling temperature is carefully chosen to maintain the temperature-adjusted entropy around 0.3, a setting that strikes a good balance between exploration and exploitation. Notably, the performance gap between initial SFT models narrows significantly throughout the RL process. Leveraging a strong SFT foundation and insights into the synergistic interplay between SFT and RL, our AceReason-Nemotron-1.1 7B model significantly outperforms AceReason-Nemotron-1.0 and achieves new state-of-the-art performance among Qwen2.5-7B-based reasoning models on challenging math and code benchmarks, thereby demonstrating the effectiveness of our post-training recipe. We release the model and data at: https://huggingface.co/nvidia/AceReason-Nemotron-1.1-7B
엔비디아의 추론 모델 실험. SFT를 많이 하면 성능이 향상된다, 그렇지만 RL 학습이 길어지면 그 차이는 감소한다, RL에서는 엔트로피를 적절하게 유지하는 것이 중요하다, RL을 통해 SFT로는 풀지 못하던 문제를 풀게 할 수 있다, 군요.
NVIDIA's experiment on reasoning models, shows that, increasing SFT improves performance, however, the performance gap narrows as RL training extends. In RL, maintaining appropriate entropy is crucial. And RL enables the model to solve problems that were unsolvable through SFT alone.
#rl #reasoning
Is your batch size the problem? Revisiting the Adam-SGD gap in language modeling
(Teodora Srećković, Jonas Geiping, Antonio Orvieto)
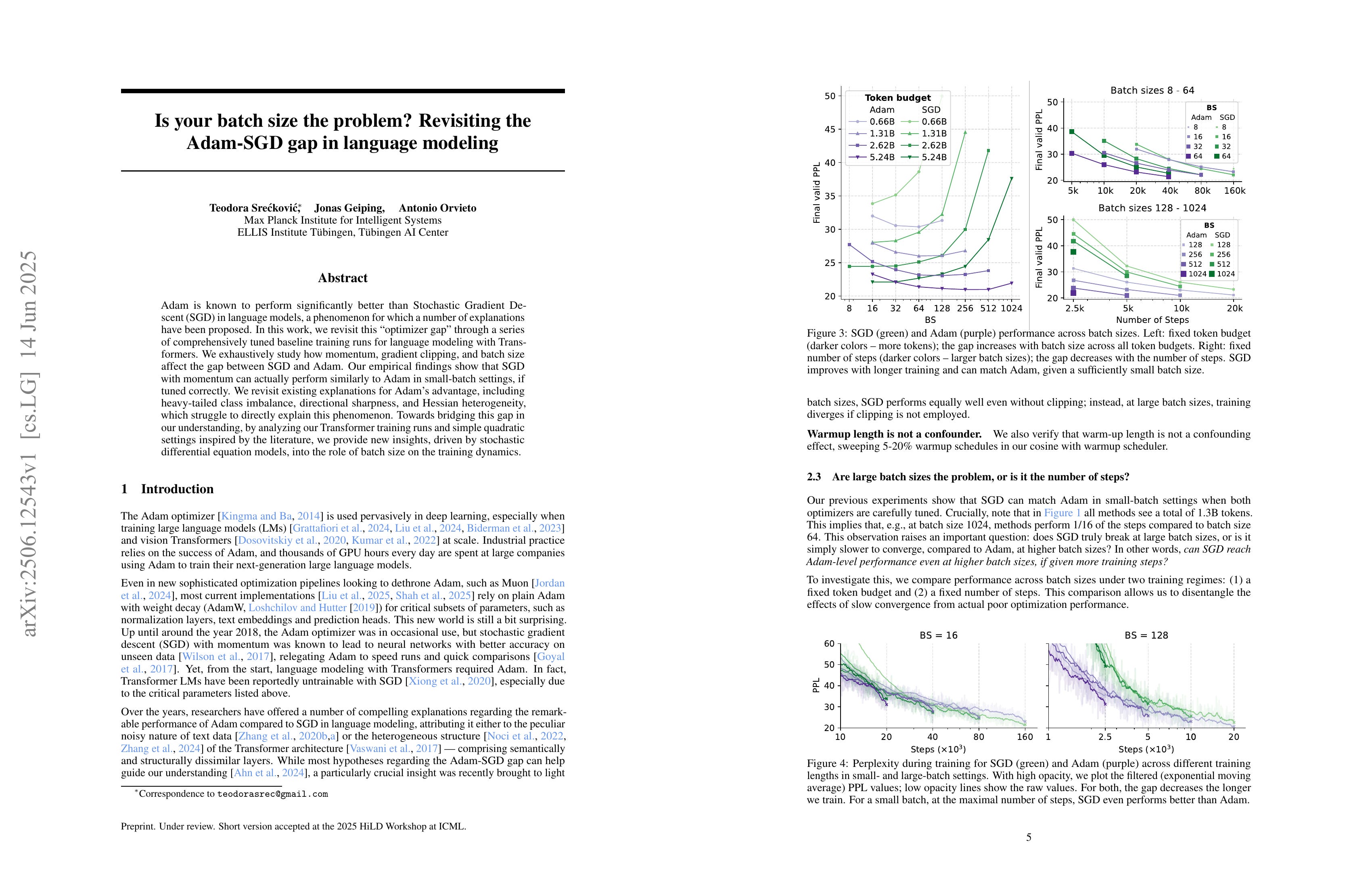
Adam is known to perform significantly better than Stochastic Gradient Descent (SGD) in language models, a phenomenon for which a number of explanations have been proposed. In this work, we revisit this "optimizer gap" through a series of comprehensively tuned baseline training runs for language modeling with Transformers. We exhaustively study how momentum, gradient clipping, and batch size affect the gap between SGD and Adam. Our empirical findings show that SGD with momentum can actually perform similarly to Adam in small-batch settings, if tuned correctly. We revisit existing explanations for Adam's advantage, including heavy-tailed class imbalance, directional sharpness, and Hessian heterogeneity, which struggle to directly explain this phenomenon. Towards bridging this gap in our understanding, by analyzing our Transformer training runs and simple quadratic settings inspired by the literature, we provide new insights, driven by stochastic differential equation models, into the role of batch size on the training dynamics.
SGD와 Adam의 트랜스포머 LM에 대한 학습 성능 차이의 원인에 대한 분석. SGD가 배치 크기가 커졌을 때의 수렴이 느리기 때문이라고 하네요. 원인으로는 그래디언트 노이즈에 대한 SGD와 Adam의 거동의 차이가 아닐까 추측하는군요.
Analysis of the performance gap between SGD and Adam in training transformer LMs. The study finds that SGD's convergence rate slows down significantly when the batch size increases. The authors suspect this is due to the different behaviors of SGD and Adam in response to gradient noise.
#optimization #transformer