



LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
(Zihan Zheng, Zerui Cheng, Zeyu Shen, Shang Zhou, Kaiyuan Liu, Hansen He, Dongruixuan Li, Stanley Wei, Hangyi Hao, Jianzhu Yao, Peiyao Sheng, Zixuan Wang, Wenhao Chai, Aleksandra Korolova, Peter Henderson, Sanjeev Arora, Pramod Viswanath, Jingbo Shang, Saining Xie)
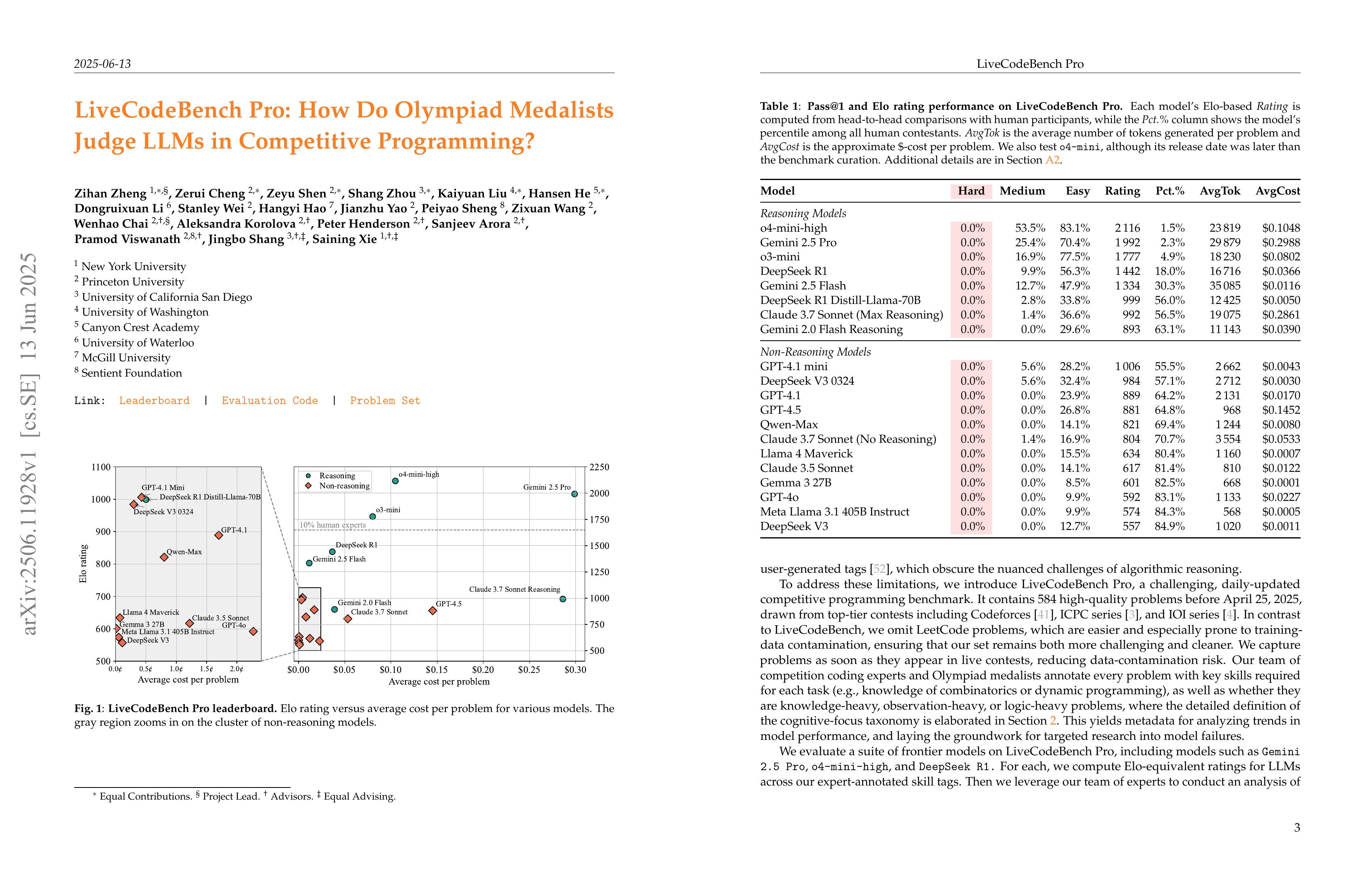
Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming. Drawing on knowledge from a group of medalists in international algorithmic contests, we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. A team of Olympiad medalists annotates every problem for algorithmic categories and conducts a line-by-line analysis of failed model-generated submissions. Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel. We also find that LLMs succeed at implementation-heavy problems but struggle with nuanced algorithmic reasoning and complex case analysis, often generating confidently incorrect justifications. High performance appears largely driven by implementation precision and tool augmentation, not superior reasoning. LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning.
코딩 대회 문제를 수집한 다음 난이도와 문제의 분류를 어노테이션해서 분석했군요.
Collected coding contest problems and then analyzed them by annotating their difficulties and categorizing the problem types.
#benchmark #code
Ambient Diffusion Omni: Training Good Models with Bad Data
(Giannis Daras, Adrian Rodriguez-Munoz, Adam Klivans, Antonio Torralba, Constantinos Daskalakis)

We show how to use low-quality, synthetic, and out-of-distribution images to improve the quality of a diffusion model. Typically, diffusion models are trained on curated datasets that emerge from highly filtered data pools from the Web and other sources. We show that there is immense value in the lower-quality images that are often discarded. We present Ambient Diffusion Omni, a simple, principled framework to train diffusion models that can extract signal from all available images during training. Our framework exploits two properties of natural images -- spectral power law decay and locality. We first validate our framework by successfully training diffusion models with images synthetically corrupted by Gaussian blur, JPEG compression, and motion blur. We then use our framework to achieve state-of-the-art ImageNet FID, and we show significant improvements in both image quality and diversity for text-to-image generative modeling. The core insight is that noise dampens the initial skew between the desired high-quality distribution and the mixed distribution we actually observe. We provide rigorous theoretical justification for our approach by analyzing the trade-off between learning from biased data versus limited unbiased data across diffusion times.
노이즈 비율이 높은 시점에 저품질 데이터를, 노이즈 비율이 낮은 시점에 OOD 데이터의 크롭을 사용해서 사용 데이터를 증가시킨다는 아이디어.
The idea of expanding the data used for training by utilizing low-quality data during periods of high noise ratio and cropped OOD data during periods of low noise ratio.
#diffusion