



2025년 5월 8일

Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
(Yehui Tang, Yichun Yin, Yaoyuan Wang, Hang Zhou, Yu Pan, Wei Guo, Ziyang Zhang, Miao Rang, Fangcheng Liu, Naifu Zhang, Binghan Li, Yonghan Dong, Xiaojun Meng, Yasheng Wang, Dong Li, Yin Li, Dandan Tu, Can Chen, Youliang Yan, Fisher Yu, Ruiming Tang, Yunhe Wang, Botian Huang, Bo Wang, Boxiao Liu, Changzheng Zhang, Da Kuang, Fei Liu, Gang Huang, Jiansheng Wei, Jiarui Qin, Jie Ran, Jinpeng Li, Jun Zhao, Liang Dai, Lin Li, Liqun Deng, Peifeng Qin, Pengyuan Zeng, Qiang Gu, Shaohua Tang, Shengjun Cheng, Tao Gao, Tao Yu, Tianshu Li, Tianyu Bi, Wei He, Weikai Mao, Wenyong Huang, Wulong Liu, Xiabing Li, Xianzhi Yu, Xueyu Wu, Xu He, Yangkai Du, Yan Xu, Ye Tian, Yimeng Wu, Yongbing Huang, Yong Tian, Yong Zhu, Yue Li, Yufei Wang, Yuhang Gai, Yujun Li, Yu Luo, Yunsheng Ni, Yusen Sun, Zelin Chen, Zhe Liu, Zhicheng Liu, Zhipeng Tu, Zilin Ding, Zongyuan Zhan)
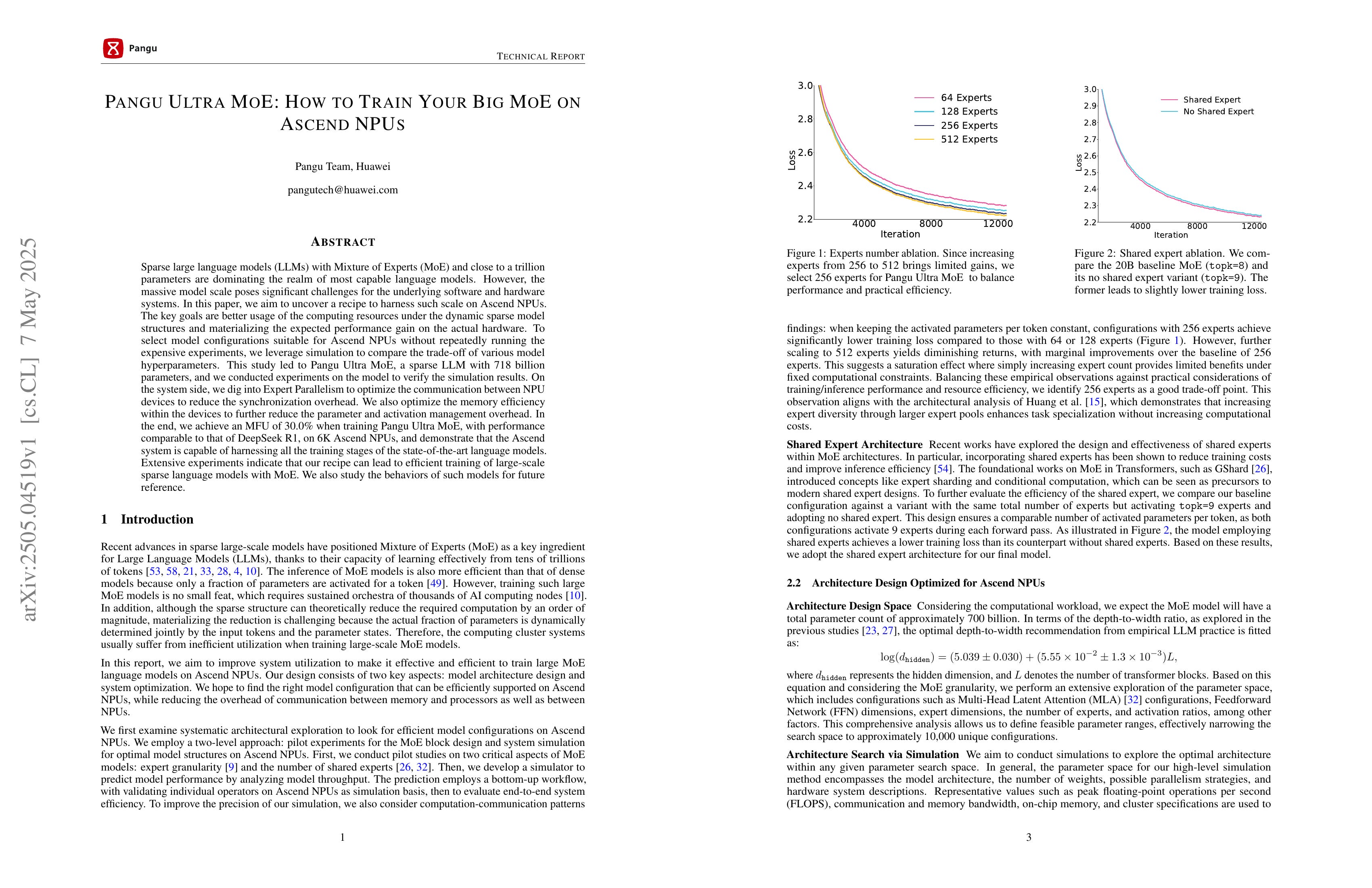
Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
화웨이의 Ascend를 사용한 모델 학습 리포트 시리즈인데 MoE 세팅에 관해서도 (로드 밸런싱 등) 흥미로운 점이 많군요.
Part of a series of model training reports using Huawei's Ascend. There are many interesting points regarding MoE settings, such as load balancing.
#moe
On Path to Multimodal Generalist: General-Level and General-Bench
(Hao Fei, Yuan Zhou, Juncheng Li, Xiangtai Li, Qingshan Xu, Bobo Li, Shengqiong Wu, Yaoting Wang, Junbao Zhou, Jiahao Meng, Qingyu Shi, Zhiyuan Zhou, Liangtao Shi, Minghe Gao, Daoan Zhang, Zhiqi Ge, Weiming Wu, Siliang Tang, Kaihang Pan, Yaobo Ye, Haobo Yuan, Tao Zhang, Tianjie Ju, Zixiang Meng, Shilin Xu, Liyu Jia, Wentao Hu, Meng Luo, Jiebo Luo, Tat-Seng Chua, Shuicheng Yan, Hanwang Zhang)

The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page:
https://generalist.top/
일반 멀티모달 모델, 그리고 그 모델이 모달리티 간에서 시너지가 발생하는 단계까지 발전할 수 있는가를 평가하기 위한 벤치마크.
A benchmark for evaluating whether generalist multimodal models can develop to the point where synergy occurs between modalities.
#benchmark #multimodal
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
(Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Fei Huang, Yan Zhang)

Effective information searching is essential for enhancing the reasoning and generation capabilities of large language models (LLMs). Recent research has explored using reinforcement learning (RL) to improve LLMs' search capabilities by interacting with live search engines in real-world environments. While these approaches show promising results, they face two major challenges: (1) Uncontrolled Document Quality: The quality of documents returned by search engines is often unpredictable, introducing noise and instability into the training process. (2) Prohibitively High API Costs: RL training requires frequent rollouts, potentially involving hundreds of thousands of search requests, which incur substantial API expenses and severely constrain scalability. To address these challenges, we introduce ZeroSearch, a reinforcement learning framework that incentivizes the search capabilities of LLMs without interacting with real search engines. Our approach begins with lightweight supervised fine-tuning to transform the LLM into a retrieval module capable of generating both relevant and noisy documents in response to a query. During RL training, we employ a curriculum-based rollout strategy that incrementally degrades the quality of generated documents, progressively eliciting the model's reasoning ability by exposing it to increasingly challenging retrieval scenarios. Extensive experiments demonstrate that ZeroSearch effectively incentivizes the search capabilities of LLMs using a 3B LLM as the retrieval module. Remarkably, a 7B retrieval module achieves comparable performance to the real search engine, while a 14B retrieval module even surpasses it. Furthermore, it generalizes well across both base and instruction-tuned models of various parameter sizes and is compatible with a wide range of RL algorithms.
LLM에 검색 능력을 탑재시킬 때 실제 검색 엔진 대신 LLM으로 문서를 생성하도록 시도. 실제 검색 엔진과의 차이가 문제겠죠. 물론 검색 엔진 자체도 시간에 따라 변화하는 타겟이긴 합니다만.
For training an LLM to have search capabilities, this paper attempts to have the LLM generate documents instead of using an actual search engine. The main challenge would be the difference from real search engine results. Of course, search engines themselves are also moving targets that change over time.
#rl #tool #reasoning