



2025년 5월 21일

General-Reasoner: Advancing LLM Reasoning Across All Domains
(Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, Wenhu Chen)
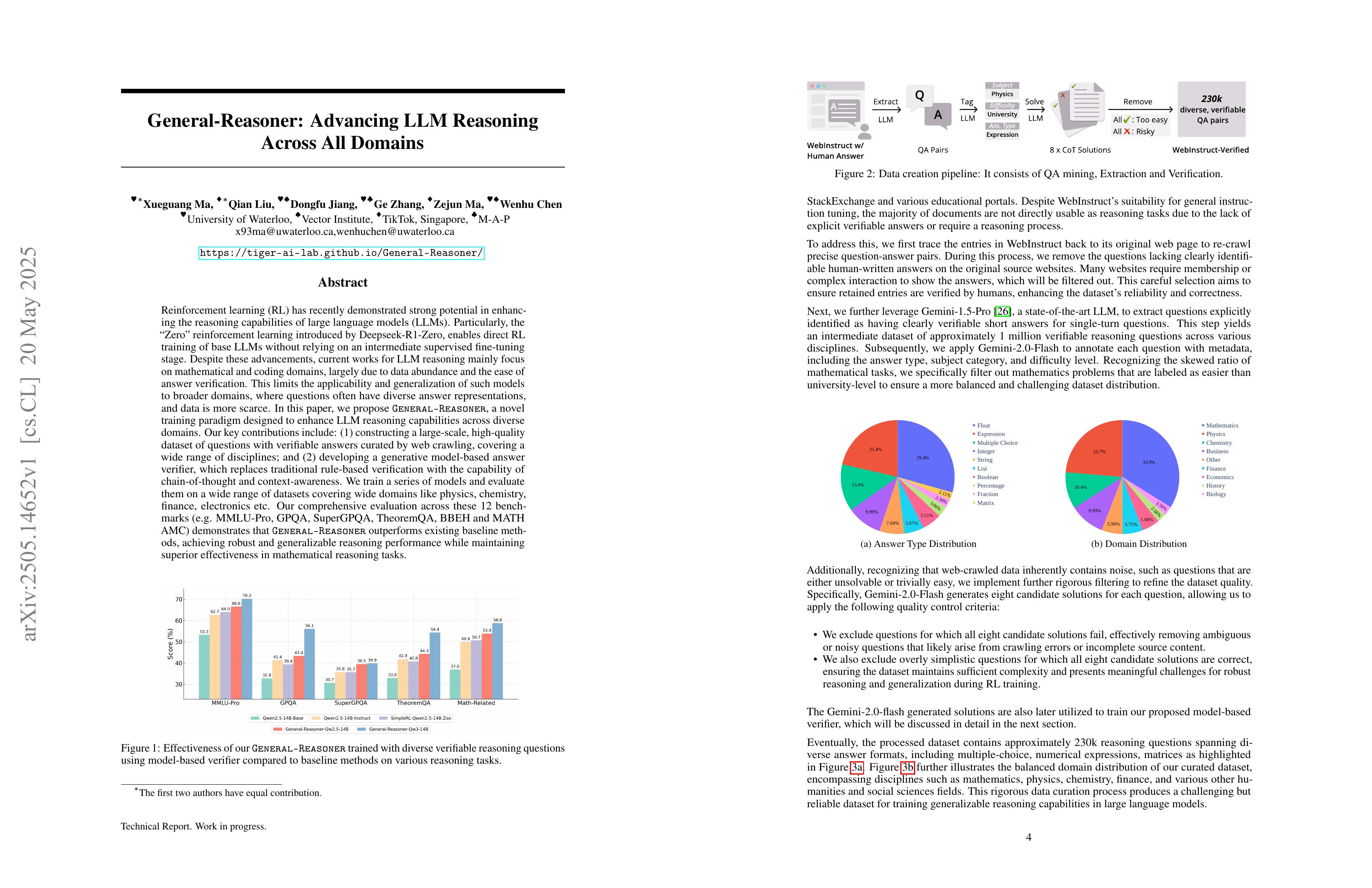
Reinforcement learning (RL) has recently demonstrated strong potential in enhancing the reasoning capabilities of large language models (LLMs). Particularly, the "Zero" reinforcement learning introduced by Deepseek-R1-Zero, enables direct RL training of base LLMs without relying on an intermediate supervised fine-tuning stage. Despite these advancements, current works for LLM reasoning mainly focus on mathematical and coding domains, largely due to data abundance and the ease of answer verification. This limits the applicability and generalization of such models to broader domains, where questions often have diverse answer representations, and data is more scarce. In this paper, we propose General-Reasoner, a novel training paradigm designed to enhance LLM reasoning capabilities across diverse domains. Our key contributions include: (1) constructing a large-scale, high-quality dataset of questions with verifiable answers curated by web crawling, covering a wide range of disciplines; and (2) developing a generative model-based answer verifier, which replaces traditional rule-based verification with the capability of chain-of-thought and context-awareness. We train a series of models and evaluate them on a wide range of datasets covering wide domains like physics, chemistry, finance, electronics etc. Our comprehensive evaluation across these 12 benchmarks (e.g. MMLU-Pro, GPQA, SuperGPQA, TheoremQA, BBEH and MATH AMC) demonstrates that General-Reasoner outperforms existing baseline methods, achieving robust and generalizable reasoning performance while maintaining superior effectiveness in mathematical reasoning tasks.
웹 데이터에서 QA를 추출하고 모델 기반 Verifier로 RL. 추론 RL에서 다음 단계로 바로 생각할 수 있는 방향이겠죠.
Reasoning RL by extracting QA data from the web and using a model-based verifier. This is a logical next step for reasoning RL, which has previously focused on math or code datasets.
#synthetic-data #rl #reasoning
Power Lines: Scaling Laws for Weight Decay and Batch Size in LLM Pre-training
(Shane Bergsma, Nolan Dey, Gurpreet Gosal, Gavia Gray, Daria Soboleva, Joel Hestness)

Efficient LLM pre-training requires well-tuned hyperparameters (HPs), including learning rate η and weight decay λ. We study scaling laws for HPs: formulas for how to scale HPs as we scale model size N, dataset size D, and batch size B. Recent work suggests the AdamW timescale, B/(ηλD), should remain constant across training settings, and we verify the implication that optimal λ scales linearly with B, for a fixed N,D. However, as N,D scale, we show the optimal timescale obeys a precise power law in the tokens-per-parameter ratio, D/N. This law thus provides a method to accurately predict λopt in advance of large-scale training. We also study scaling laws for optimal batch size Bopt (the B enabling lowest loss at a given N,D) and critical batch size Bcrit (the B beyond which further data parallelism becomes ineffective). In contrast with prior work, we find both Bopt and Bcrit scale as power laws in D, independent of model size, N. Finally, we analyze how these findings inform the real-world selection of Pareto-optimal N and D under dual training time and compute objectives.
Cerebras는 Hyperparameter Scaling Law 추정도 시도했군요. 여기에서는 Optimal Timescale = Batch Size / (LR * Weight Decay * Training Data Size)이 Critical Batch Size 이하에서 일정하고 Critical Batch Size는 이전의 연구 결과와 같이 (https://arxiv.org/abs/2503.04715) Training Data Size에만 의존한다는 결론을 냈군요. 흥미롭네요.
Cerebras has also attempted to estimate hyperparameter scaling laws. The paper concludes that the optimal timescale (defined as batch size / (LR * weight decay * training data size)) remains constant below the critical batch size. Additionally, it finds that the critical batch size depends only on the training data size, consistent with a previous study (https://arxiv.org/abs/2503.04715). This is quite interesting.
#scaling-law #hyperparameter
Emerging Properties in Unified Multimodal Pretraining
(Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, Haoqi Fan)

Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. In this work, we introduce BAGEL, an open0source foundational model that natively supports multimodal understanding and generation. BAGEL is a unified, decoder0only model pretrained on trillions of tokens curated from large0scale interleaved text, image, video, and web data. When scaled with such diverse multimodal interleaved data, BAGEL exhibits emerging capabilities in complex multimodal reasoning. As a result, it significantly outperforms open-source unified models in both multimodal generation and understanding across standard benchmarks, while exhibiting advanced multimodal reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and world navigation. In the hope of facilitating further opportunities for multimodal research, we share the key findings, pretraining details, data creation protocal, and release our code and checkpoints to the community. The project page is at
https://bagel-ai.org/
바이트댄스의 이미지 인식/생성 모델. 요즘 많이 시도하는 것처럼 ViT와 VAE 토큰을 동시 사용하고 Diffusion을 사용, 그리고 트랜스포머 백본을 중복시키는 MoT를 사용했군요 (https://arxiv.org/abs/2411.04996).
학습 데이터 증가에 따라 특히 생성 영역에서 창발이 나타나네요.
ByteDance's image understanding and generation model. As commonly attempted recently, they use ViT and VAE tokens simultaneously, employ diffusion, and utilize MoT which duplicates the transformer backbone (https://arxiv.org/abs/2411.04996).
As the training data increases, emergent phenomena occur, particularly in generation tasks.
#multimodal #image-generation
Scaling Law for Quantization-Aware Training
(Mengzhao Chen, Chaoyi Zhang, Jing Liu, Yutao Zeng, Zeyue Xue, Zhiheng Liu, Yunshui Li, Jin Ma, Jie Huang, Xun Zhou, Ping Luo)

Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
QAT에 대한 Scaling Law. 이쪽에서도 학습 토큰 증가에 따라 Weight Quantization이 어려워지는 문제를 지적하고 있군요 (https://arxiv.org/abs/2411.17691). 그리고 FC2 입력이 Activation Quantization의 난점이라고 (https://arxiv.org/abs/2409.12517).
Scaling law for QAT. This study also points out that weight quantization becomes more difficult as the number of training tokens increases (https://arxiv.org/abs/2411.17691). Additionally, it identifies the input to the FC2 layer as the main challenge for activation quantization (https://arxiv.org/abs/2409.12517).
#quantization #scaling-law
Do Language Models Use Their Depth Efficiently?
(Róbert Csordás, Christopher D. Manning, Christopher Potts)

Modern LLMs are increasingly deep, and depth correlates with performance, albeit with diminishing returns. However, do these models use their depth efficiently? Do they compose more features to create higher-order computations that are impossible in shallow models, or do they merely spread the same kinds of computation out over more layers? To address these questions, we analyze the residual stream of the Llama 3.1 and Qwen 3 family of models. We find: First, comparing the output of the sublayers to the residual stream reveals that layers in the second half contribute much less than those in the first half, with a clear phase transition between the two halves. Second, skipping layers in the second half has a much smaller effect on future computations and output predictions. Third, for multihop tasks, we are unable to find evidence that models are using increased depth to compose subresults in examples involving many hops. Fourth, we seek to directly address whether deeper models are using their additional layers to perform new kinds of computation. To do this, we train linear maps from the residual stream of a shallow model to a deeper one. We find that layers with the same relative depth map best to each other, suggesting that the larger model simply spreads the same computations out over its many layers. All this evidence suggests that deeper models are not using their depth to learn new kinds of computation, but only using the greater depth to perform more fine-grained adjustments to the residual. This may help explain why increasing scale leads to diminishing returns for stacked Transformer architectures.
트랜스포머 LM이 레이어들을 효과적으로 사용하지 않는 것 같다는 분석. 깊은 모델은 얕은 모델을 잡아 늘린 것과 비슷한 방식으로 작동하고 레이어들이 출력 결과의 세부 조정을 위해 사용되고 있다고 하네요.
LM이라는 학습 목표의 문제일 수도 있고 Pre Norm 혹은 Layer Reuse 같은 아키텍처 관련 문제일 수도 있겠죠. 이를 해소할 수 있다면 LM의 성능이 크게 달라질까요.
Analysis suggests that transformer language models do not use their layers effectively. Deeper models seem to function similarly to stretched-out versions of shallower models, with many layers being used for fine-adjustment of output results.
This could be due to the learning objective of language models, or it might be related to architectural issues such as pre norm or layer reuse. If we could address this issue, would it significantly improve the performance of language models?
#transformer #lm
TinyV: Reducing False Negatives in Verification Improves RL for LLM Reasoning
(Zhangchen Xu, Yuetai Li, Fengqing Jiang, Bhaskar Ramasubramanian, Luyao Niu, Bill Yuchen Lin, Radha Poovendran)

Reinforcement Learning (RL) has become a powerful tool for enhancing the reasoning abilities of large language models (LLMs) by optimizing their policies with reward signals. Yet, RL's success relies on the reliability of rewards, which are provided by verifiers. In this paper, we expose and analyze a widespread problem--false negatives--where verifiers wrongly reject correct model outputs. Our in-depth study of the Big-Math-RL-Verified dataset reveals that over 38% of model-generated responses suffer from false negatives, where the verifier fails to recognize correct answers. We show, both empirically and theoretically, that these false negatives severely impair RL training by depriving the model of informative gradient signals and slowing convergence. To mitigate this, we propose tinyV, a lightweight LLM-based verifier that augments existing rule-based methods, which dynamically identifies potential false negatives and recovers valid responses to produce more accurate reward estimates. Across multiple math-reasoning benchmarks, integrating TinyV boosts pass rates by up to 10% and accelerates convergence relative to the baseline. Our findings highlight the critical importance of addressing verifier false negatives and offer a practical approach to improve RL-based fine-tuning of LLMs. Our code is available at https://github.com/uw-nsl/TinyV.
RLVR에서 Verifier의 False Negative가 미치는 영향 분석. False Negative 문제 해소를 위해 모델 기반 Verifier를 가져왔군요. 모델 기반 Verifier가 대세가 될 것 같긴 합니다.
Analysis of the impact of false negatives from verifiers in RLVR. They introduced a model-based verifier to address the false negative problem. I think model-based verifiers are likely to become the mainstream.
#rl #reasoning