



2025년 5월 20일

Mean Flows for One-step Generative Modeling
(Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, Kaiming He)

We propose a principled and effective framework for one-step generative modeling. We introduce the notion of average velocity to characterize flow fields, in contrast to instantaneous velocity modeled by Flow Matching methods. A well-defined identity between average and instantaneous velocities is derived and used to guide neural network training. Our method, termed the MeanFlow model, is self-contained and requires no pre-training, distillation, or curriculum learning. MeanFlow demonstrates strong empirical performance: it achieves an FID of 3.43 with a single function evaluation (1-NFE) on ImageNet 256x256 trained from scratch, significantly outperforming previous state-of-the-art one-step diffusion/flow models. Our study substantially narrows the gap between one-step diffusion/flow models and their multi-step predecessors, and we hope it will motivate future research to revisit the foundations of these powerful models.
평균 속도를 추정하는 방식의 1/Few-shot Flow Matching. 이건 상당히 흥미롭네요.
An 1/few-shot flow matching that estimates average velocity. Very interesting.
#diffusion
Model Merging in Pre-training of Large Language Models
(Yunshui Li, Yiyuan Ma, Shen Yan, Chaoyi Zhang, Jing Liu, Jianqiao Lu, Ziwen Xu, Mengzhao Chen, Minrui Wang, Shiyi Zhan, Jin Ma, Xunhao Lai, Yao Luo, Xingyan Bin, Hongbin Ren, Mingji Han, Wenhao Hao, Bairen Yi, LingJun Liu, Bole Ma, Xiaoying Jia, Zhou Xun, Liang Xiang, Yonghui Wu)
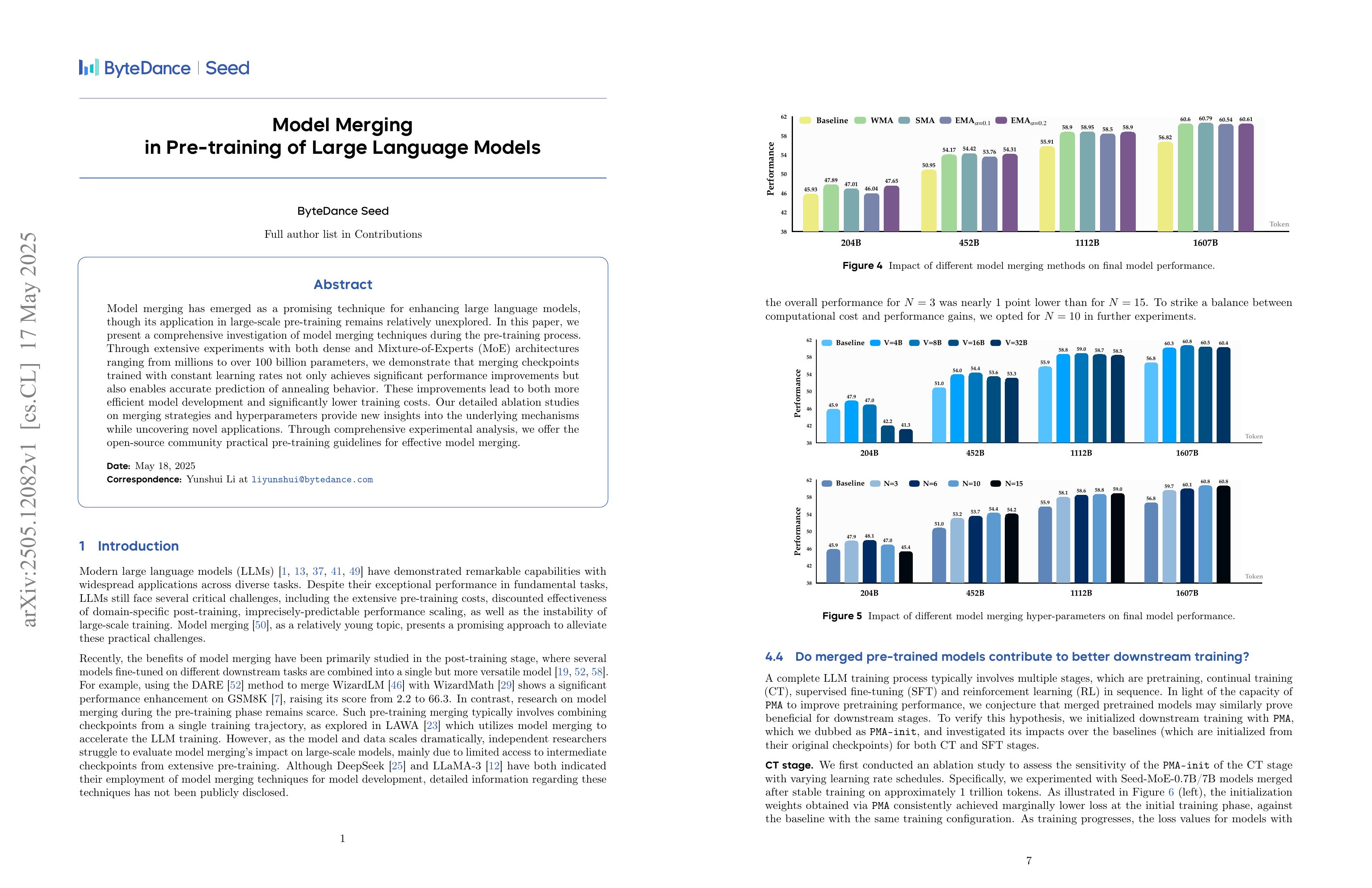
Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
프리트레이닝에 Averaged SGD를 쓴 실험에 대한 결과군요. 학습 중간에 LR Annealing을 하지 않더라도 Annealing을 한 것과 비슷한 결과가 나온다는 것이 유용한 경우도 있을 것 같습니다. 그리고 파인튜닝의 초기 체크포인트로 쓰기에도 괜찮았다고 하는군요. MoE에 좀 더 잘 맞을 것 같기도 합니다.
This paper presents results on applying averaged SGD to pretraining. There could be useful cases where you can achieve results similar to LR annealing during pretraining without actually performing the annealing process. The paper also reports that this method was effective as an initial checkpoint for fine-tuning. I think this approach might be particularly well-suited for MoE.
#pretraining #optimizer
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
(Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, Hao Peng)

Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from updating only a small subnetwork comprising just 5 percent to 30 percent of the parameters, with the rest effectively unchanged. We refer to this phenomenon as parameter update sparsity induced by RL. It is observed across all 7 widely used RL algorithms (e.g., PPO, GRPO, DPO) and all 10 LLMs from different families in our experiments. This sparsity is intrinsic and occurs without any explicit sparsity promoting regularizations or architectural constraints. Finetuning the subnetwork alone recovers the test accuracy, and, remarkably, produces a model nearly identical to the one obtained via full finetuning. The subnetworks from different random seeds, training data, and even RL algorithms show substantially greater overlap than expected by chance. Our analysis suggests that this sparsity is not due to updating only a subset of layers, instead, nearly all parameter matrices receive similarly sparse updates. Moreover, the updates to almost all parameter matrices are nearly full-rank, suggesting RL updates a small subset of parameters that nevertheless span almost the full subspaces that the parameter matrices can represent. We conjecture that the this update sparsity can be primarily attributed to training on data that is near the policy distribution, techniques that encourage the policy to remain close to the pretrained model, such as the KL regularization and gradient clipping, have limited impact.
RL 학습 과정에서 Full Rank이지만 SFT에 비해 상당히 희소한 업데이트가 일어난다고 하네요. KL Penalty 등과는 별개로 In-distribution 데이터에 의한 학습의 효과라고. 자연스럽지만 흥미롭군요.
The study reports that during the RL learning process, although full-rank, the updates are considerably sparse compared to SFT. This effect is mainly due to training on in-distribution data, rather than factors like KL penalties. While this result seems natural, it's quite interesting.
#rl #optimizer #llm
RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics
(Jie Zhang, Cezara Petrui, Kristina Nikolić, Florian Tramèr)

Existing benchmarks for evaluating mathematical reasoning in large language models (LLMs) rely primarily on competition problems, formal proofs, or artificially challenging questions -- failing to capture the nature of mathematics encountered in actual research environments. We introduce RealMath, a novel benchmark derived directly from research papers and mathematical forums that assesses LLMs' abilities on authentic mathematical tasks. Our approach addresses three critical challenges: sourcing diverse research-level content, enabling reliable automated evaluation through verifiable statements, and designing a continually refreshable dataset to mitigate contamination risks. Experimental results across multiple LLMs reveal surprising capabilities in handling research mathematics compared to competition problems, suggesting current models may already serve as valuable assistants for working mathematicians despite limitations on highly challenging problems. The code and dataset for RealMath are publicly available.
수학 벤치마크. AIME 외의 좋은 선택이 될 수 있을지 궁금하네요.
Math benchmark. I wonder if this could be a good alternative to AIME.
#math #benchmark
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
(Zhihe Yang, Xufang Luo, Zilong Wang, Dongqi Han, Zhiyuan He, Dongsheng Li, Yunjian Xu)

Reinforcement learning (RL) has become a cornerstone for enhancing the reasoning capabilities of large language models (LLMs), with recent innovations such as Group Relative Policy Optimization (GRPO) demonstrating exceptional effectiveness. In this study, we identify a critical yet underexplored issue in RL training: low-probability tokens disproportionately influence model updates due to their large gradient magnitudes. This dominance hinders the effective learning of high-probability tokens, whose gradients are essential for LLMs' performance but are substantially suppressed. To mitigate this interference, we propose two novel methods: Advantage Reweighting and Low-Probability Token Isolation (Lopti), both of which effectively attenuate gradients from low-probability tokens while emphasizing parameter updates driven by high-probability tokens. Our approaches promote balanced updates across tokens with varying probabilities, thereby enhancing the efficiency of RL training. Experimental results demonstrate that they substantially improve the performance of GRPO-trained LLMs, achieving up to a 46.2% improvement in K&K Logic Puzzle reasoning tasks. Our implementation is available at https://github.com/zhyang2226/AR-Lopti.
GRPO 과정에서 확률이 낮은 토큰에 대한 그래디언트가 지나치게 높다는 분석. RL 과정에도 Top-P 마스킹이 필요하지 않나 싶네요.
This analysis suggests that gradients for low-probability tokens are excessively high during GRPO. It seems we might need top-P masking for RL training.
#rl #reasoning
Optimizing Anytime Reasoning via Budget Relative Policy Optimization
(Penghui Qi, Zichen Liu, Tianyu Pang, Chao Du, Wee Sun Lee, Min Lin)

Scaling test-time compute is crucial for enhancing the reasoning capabilities of large language models (LLMs). Existing approaches typically employ reinforcement learning (RL) to maximize a verifiable reward obtained at the end of reasoning traces. However, such methods optimize only the final performance under a large and fixed token budget, which hinders efficiency in both training and deployment. In this work, we present a novel framework, AnytimeReasoner, to optimize anytime reasoning performance, which aims to improve token efficiency and the flexibility of reasoning under varying token budget constraints. To achieve this, we truncate the complete thinking process to fit within sampled token budgets from a prior distribution, compelling the model to summarize the optimal answer for each truncated thinking for verification. This introduces verifiable dense rewards into the reasoning process, facilitating more effective credit assignment in RL optimization. We then optimize the thinking and summary policies in a decoupled manner to maximize the cumulative reward. Additionally, we introduce a novel variance reduction technique, Budget Relative Policy Optimization (BRPO), to enhance the robustness and efficiency of the learning process when reinforcing the thinking policy. Empirical results in mathematical reasoning tasks demonstrate that our method consistently outperforms GRPO across all thinking budgets under various prior distributions, enhancing both training and token efficiency.
추론의 길이를 효율화하기 위한 연구가 정말 많이 나오고 있고 앞으로도 많이 나올 것 같네요. (https://arxiv.org/abs/2505.11827, https://arxiv.org/abs/2505.13417, https://arxiv.org/abs/2505.13379, https://arxiv.org/abs/2505.13326, https://arxiv.org/abs/2505.12284)
이전 연구와 비슷하게 추론과 결론의 예산을 분리하고 (https://arxiv.org/abs/2505.05315) 각 추론의 길이에 따라 보상을 부여해서 Dense Reward를 제공하는 방법.
효율적인 추론에 대해서 생각해보게 되네요. 간명한 증명은 그렇지 않은 증명과는 접근 자체가 다른 경우가 많겠죠. 그런 요인은 어떻게 반영할 수 있을까요.
There are many studies focusing on optimizing the length of reasoning, and I expect this trend to continue. (https://arxiv.org/abs/2505.11827, https://arxiv.org/abs/2505.13417, https://arxiv.org/abs/2505.13379, https://arxiv.org/abs/2505.13326, https://arxiv.org/abs/2505.12284)
Similar to previous research, this method separates the budget for reasoning and summary (https://arxiv.org/abs/2505.05315), and provides dense rewards by assigning rewards for reasoning of various lengths.
This makes me think about efficient reasoning. Concise proofs often have fundamentally different approaches compared to longer, less efficient proofs. How can we incorporate these factors into our models?
#reasoning #rl
Occult: Optimizing Collaborative Communication across Experts for Accelerated Parallel MoE Training and Inference
(Shuqing Luo, Pingzhi Li, Jie Peng, Hanrui Wang, Yang (Katie)Zhao, Yu (Kevin)Cao, Yu Cheng, Tianlong Chen)
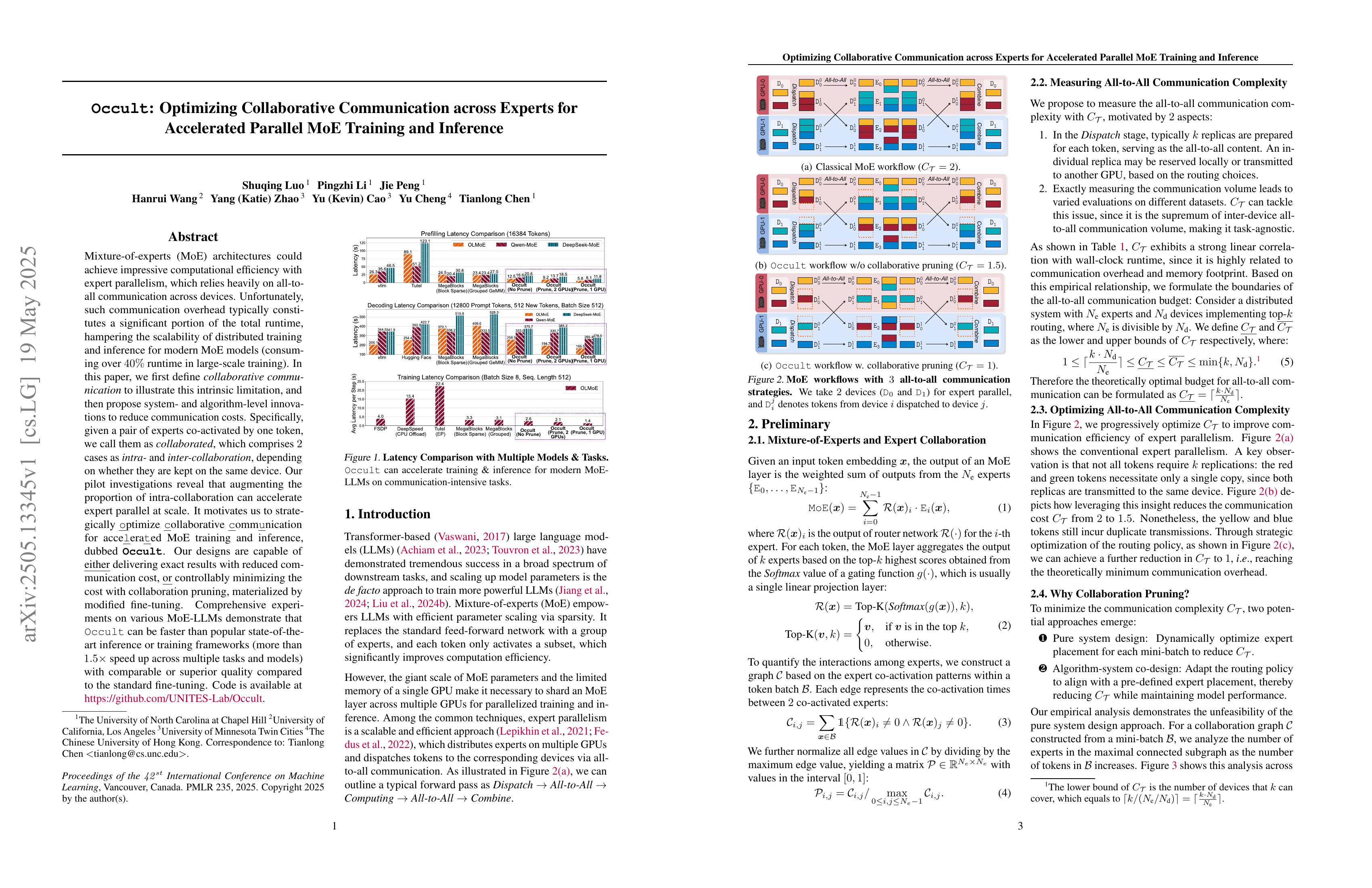
Mixture-of-experts (MoE) architectures could achieve impressive computational efficiency with expert parallelism, which relies heavily on all-to-all communication across devices. Unfortunately, such communication overhead typically constitutes a significant portion of the total runtime, hampering the scalability of distributed training and inference for modern MoE models (consuming over 40% runtime in large-scale training). In this paper, we first define collaborative communication to illustrate this intrinsic limitation, and then propose system- and algorithm-level innovations to reduce communication costs. Specifically, given a pair of experts co-activated by one token, we call them "collaborated", which comprises 2 cases as intra- and inter-collaboration, depending on whether they are kept on the same device. Our pilot investigations reveal that augmenting the proportion of intra-collaboration can accelerate expert parallelism at scale. It motivates us to strategically optimize collaborative communication for accelerated MoE training and inference, dubbed Occult. Our designs are capable of either delivering exact results with reduced communication cost or controllably minimizing the cost with collaboration pruning, materialized by modified fine-tuning. Comprehensive experiments on various MoE-LLMs demonstrate that Occult can be faster than popular state-of-the-art inference or training frameworks (more than 1.5× speed up across multiple tasks and models) with comparable or superior quality compared to the standard fine-tuning. Code is available at https://github.com/UNITES-Lab/Occult.
같이 활성화 되는 Expert를 한 디바이스에 모으면 Top-K 라우팅을 하더라도 모든 토큰을 K개 전송할 필요는 없다는 아이디어.
The idea is that if we group co-activated experts on the same device, we don't need to transmit all tokens K times even when using top-K routing.
#moe #efficiency
Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards
(Xiaoyuan Liu, Tian Liang, Zhiwei He, Jiahao Xu, Wenxuan Wang, Pinjia He, Zhaopeng Tu, Haitao Mi, Dong Yu)

Large Language Models (LLMs) show great promise in complex reasoning, with Reinforcement Learning with Verifiable Rewards (RLVR) being a key enhancement strategy. However, a prevalent issue is ``superficial self-reflection'', where models fail to robustly verify their own outputs. We introduce RISE (Reinforcing Reasoning with Self-Verification), a novel online RL framework designed to tackle this. RISE explicitly and simultaneously trains an LLM to improve both its problem-solving and self-verification abilities within a single, integrated RL process. The core mechanism involves leveraging verifiable rewards from an outcome verifier to provide on-the-fly feedback for both solution generation and self-verification tasks. In each iteration, the model generates solutions, then critiques its own on-policy generated solutions, with both trajectories contributing to the policy update. Extensive experiments on diverse mathematical reasoning benchmarks show that RISE consistently improves model's problem-solving accuracy while concurrently fostering strong self-verification skills. Our analyses highlight the advantages of online verification and the benefits of increased verification compute. Additionally, RISE models exhibit more frequent and accurate self-verification behaviors during reasoning. These advantages reinforce RISE as a flexible and effective path towards developing more robust and self-aware reasoners.
추론 RL 시점에 Verifier로 Reward를 주니 Verification 자체도 모델에 학습시키자는 아이디어. 과제 확장 효과도 있으니 나쁘지 않을 것 같네요.
The idea is to train the model to do verification simultaneously as rewards are calculated using a verifier during reasoning RL. I think this approach could be valuable as it can expand the scope of tasks.
#reasoning #rl
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
(Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, Yuandong Tian)

Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens'' before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with D steps of continuous CoTs can solve the directed graph reachability problem, where D is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires O(n^2) decoding steps where n is the number of vertices (D<n). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.
요즘 Continuous Thought에 대한 연구들이 정말 많이 나오고 있죠. (https://arxiv.org/abs/2505.12629, https://arxiv.org/abs/2505.10518, https://arxiv.org/abs/2505.13308) Continuous Thought의 잠재적인 가치를 Superposition 측면에서 분석했네요.
Many studies on continuous thought have been emerging recently (https://arxiv.org/abs/2505.12629, https://arxiv.org/abs/2505.10518, https://arxiv.org/abs/2505.13308). This paper analyzes the potential value of continuous thought from the perspective of superposition.
#reasoning #mechanistic-interpretation