



2025년 5월 2일

Understanding the Skill Gap in Recurrent Language Models: The Role of the Gather-and-Aggregate Mechanism
(Aviv Bick, Eric Xing, Albert Gu)

SSMs offer efficient processing of long sequences with fixed state sizes, but struggle with algorithmic tasks like retrieving past context. In this work, we examine how such in-context retrieval operates within Transformer- and SSM-based language models. We find that both architectures develop the same fundamental Gather-and-Aggregate (G&A) mechanism. A Gather Head first identifies and extracts relevant information from the context, which an Aggregate Head then integrates into a final representation. Across both model types, G&A concentrates in just a few heads, making them critical bottlenecks even for benchmarks that require a basic form of retrieval. For example, disabling a single Gather or Aggregate Head of a pruned Llama-3.1-8B degrades its ability to retrieve the correct answer letter in MMLU, reducing accuracy from 66% to 25%. This finding suggests that in-context retrieval can obscure the limited knowledge demands of certain tasks. Despite strong MMLU performance with retrieval intact, the pruned model fails on other knowledge tests. Similar G&A dependencies exist in GSM8K, BBH, and dialogue tasks. Given the significance of G&A in performance, we show that retrieval challenges in SSMs manifest in how they implement G&A, leading to smoother attention patterns rather than the sharp token transitions that effective G&A relies on. Thus, while a gap exists between Transformers and SSMs in implementing in-context retrieval, it is confined to a few heads, not the entire model. This insight suggests a unified explanation for performance differences between Transformers and SSMs while also highlighting ways to combine their strengths. For example, in pretrained hybrid models, attention components naturally take on the role of Aggregate Heads. Similarly, in a pretrained pure SSM, replacing a single G&A head with an attention-based variant significantly improves retrieval.
MMLU를 메인으로 SSM과 Attention의 차이를 분석. 여러 토큰의 정보를 압축하는 Gather Head와 이렇게 합쳐진 토큰을 종합하는 Aggregate Head가 중요한데 SSM의 경우 엔트로피가 높아서 이 헤드가 잘 구현되지 않는군요. 반대로 하이브리드 모델은 이 헤드들을 Attention으로 구현할 수 있으니 문제를 해소할 수 있죠.
This paper analyzes the differences between SSMs and Attention models, primarily using MMLU as a target. It highlights the importance of two key components, the gather head, which condenses information from multiple tokens, and the aggregate head, which synthesizes these condensed tokens. SSMs struggle to implement these heads effectively due to their higher entropy. Conversely, hybrid models can implement these heads using Attention mechanisms, thus resolving this issue.
#state-space-model #attention
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
(Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, Hongsheng Li)

Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1
이미지 생성을 위한 CoT와 이미지 생성 과정에 대해 GRPO를 시도했군요.
An attempt to apply GRPO on CoT for image generation and token by token image generation process.
#rl #image-generation #autoregressive-model
On the generalization of language models from in-context learning and finetuning: a controlled study
(Andrew K. Lampinen, Arslan Chaudhry, Stephanie C.Y. Chan, Cody Wild, Diane Wan, Alex Ku, Jörg Bornschein, Razvan Pascanu, Murray Shanahan, James L. McClelland)
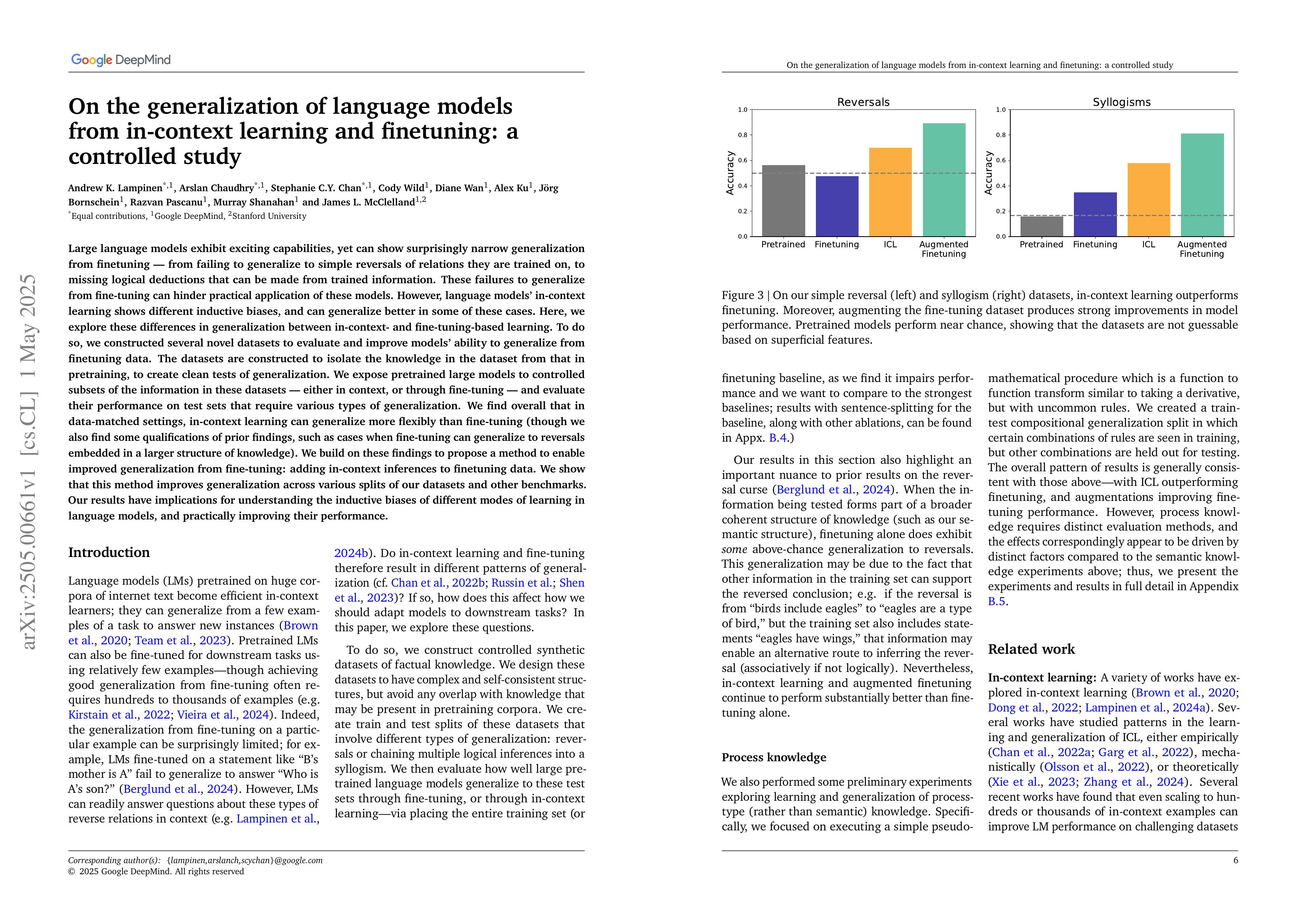
Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning -- from failing to generalize to simple reversals of relations they are trained on, to missing logical deductions that can be made from trained information. These failures to generalize from fine-tuning can hinder practical application of these models. However, language models' in-context learning shows different inductive biases, and can generalize better in some of these cases. Here, we explore these differences in generalization between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' ability to generalize from finetuning data. The datasets are constructed to isolate the knowledge in the dataset from that in pretraining, to create clean tests of generalization. We expose pretrained large models to controlled subsets of the information in these datasets -- either in context, or through fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, in-context learning can generalize more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context inferences to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the inductive biases of different modes of learning in language models, and practically improving their performance.
Reversal Curse 같은 문제에 대해 In-context Learning이 Finetuning보다 나은 일반화를 나타내는 현상에 대한 분석. In-context Learning을 통해 데이터를 증폭시키는 것으로 더 나은 일반화가 가능하다는 결론.
This paper analyzes the phenomenon where in-context learning demonstrates better generalization compared to fine-tuning for problems such as the reversal curse. The authors suggest that better generalization can be achieved by augmenting data through in-context learning.
#generalization #in-context-learning