



2025년 4월 8일

VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
(YuYue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xiangpeng Wei, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Ru Zhang, Xin Liu, Mingxuan Wang, Yonghui Wu, Lin Yan)
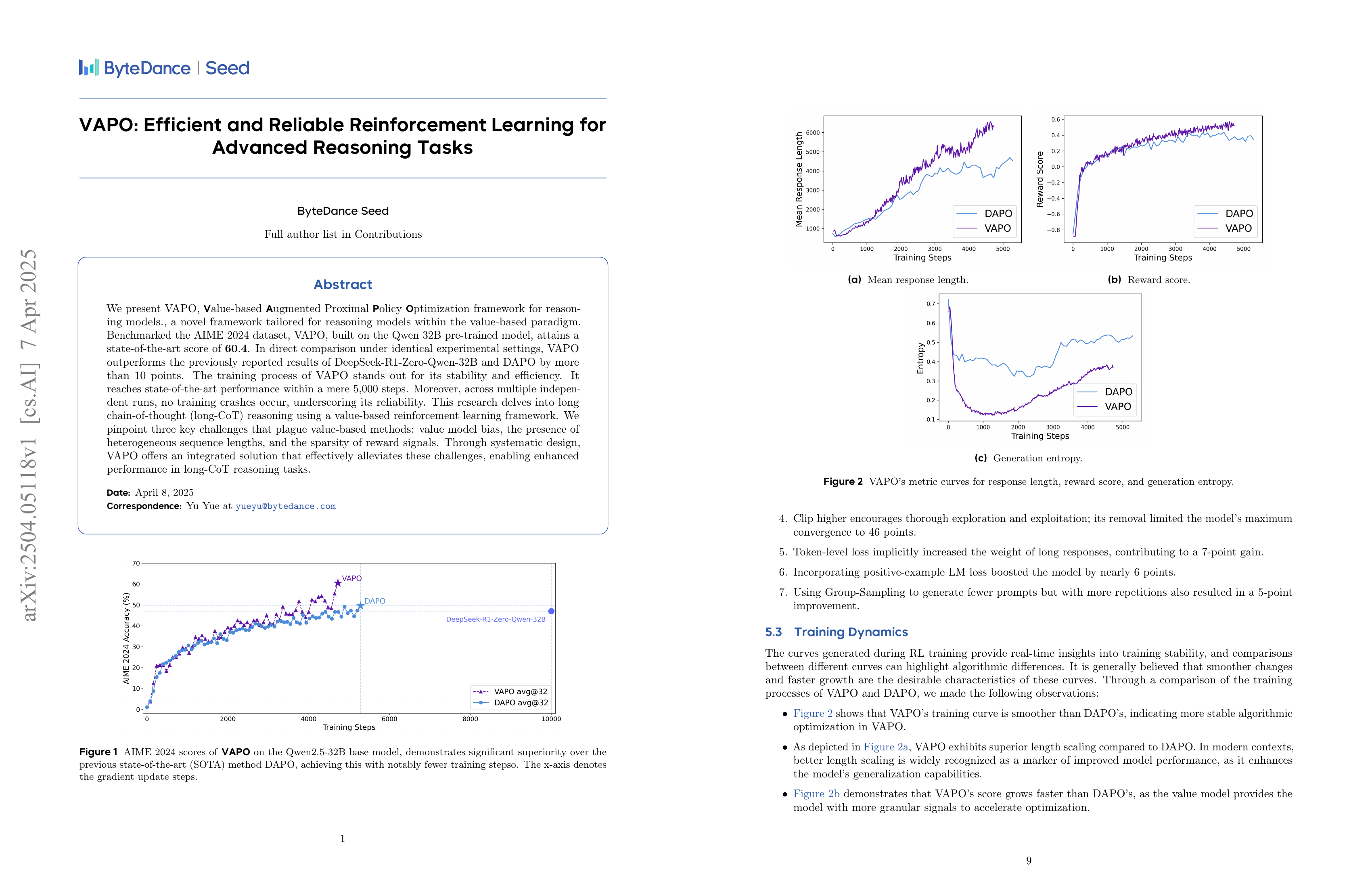
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of 60.4. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
PPO의 개선 버전도 만들었군요. DAPO의 (https://arxiv.org/abs/2503.14476) 개선들을 가져오고 Value에 대한 프리트레이닝과 길이에 따라 다른 λ를 쓰는 방법.
ByteDance also created an improved version of PPO. They incorporated improvements from DAPO (https://arxiv.org/abs/2503.14476), implemented value pre-training, and used a λ that varies with sequence length.
#rl #reasoning
Concise Reasoning via Reinforcement Learning
(Mehdi Fatemi, Banafsheh Rafiee, Mingjie Tang, Kartik Talamadupula)

Despite significant advancements in large language models (LLMs), a major drawback of reasoning models is their enormous token usage, which increases computational cost, resource requirements, and response time. In this work, we revisit the core principles of reinforcement learning (RL) and, through mathematical analysis, demonstrate that the tendency to generate lengthy responses arises inherently from RL-based optimization during training. This finding questions the prevailing assumption that longer responses inherently improve reasoning accuracy. Instead, we uncover a natural correlation between conciseness and accuracy that has been largely overlooked. Moreover, we show that introducing a secondary phase of RL post-training, using a small set of problems and limited resources, can significantly reduce a model's chain of thought while maintaining or even enhancing accuracy. Finally, we validate our conclusions through extensive experimental results.
PPO를 사용할 때 정답률이 높으면 추론의 길이가 짧아지는 경향이 있다는 분석이군요. VAPO에서도 그렇고 RL 알고리즘의 형태와 길이에 대한 관련성에 대해 좀 더 깊이 분석할 필요가 있네요.
The analysis suggests that when using PPO, there's a tendency for the length of reasoning to decrease as the correct rate increases. Similar to VAPO, this indicates a need for deeper analysis on the relationship between RL algorithms and the length of reasoning.
#rl #reasoning
Dion: A Communication-Efficient Optimizer for Large Models
(Kwangjun Ahn, Byron Xu)
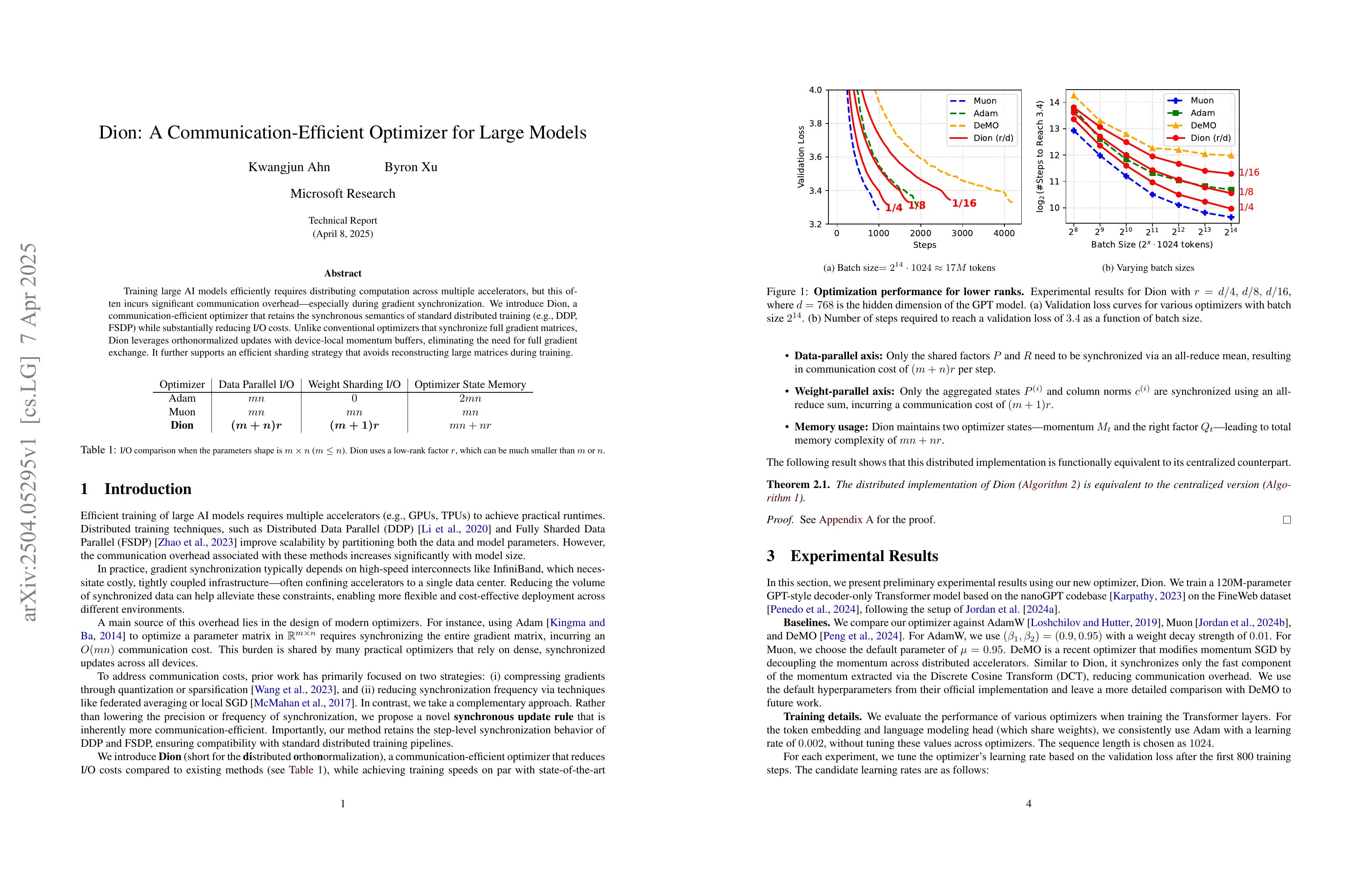
Training large AI models efficiently requires distributing computation across multiple accelerators, but this often incurs significant communication overhead -- especially during gradient synchronization. We introduce Dion, a communication-efficient optimizer that retains the synchronous semantics of standard distributed training (e.g., DDP, FSDP) while substantially reducing I/O costs. Unlike conventional optimizers that synchronize full gradient matrices, Dion leverages orthonormalized updates with device-local momentum buffers, eliminating the need for full gradient exchange. It further supports an efficient sharding strategy that avoids reconstructing large matrices during training.
Muon의 Low Rank 버전이네요.
Low rank version of Muon.
#optimizer
A Unified Pairwise Framework for RLHF: Bridging Generative Reward Modeling and Policy Optimization
(Wenyuan Xu, Xiaochen Zuo, Chao Xin, Yu Yue, Lin Yan, Yonghui Wu)

Reinforcement Learning from Human Feedback (RLHF) has emerged as a important paradigm for aligning large language models (LLMs) with human preferences during post-training. This framework typically involves two stages: first, training a reward model on human preference data, followed by optimizing the language model using reinforcement learning algorithms. However, current RLHF approaches may constrained by two limitations. First, existing RLHF frameworks often rely on Bradley-Terry models to assign scalar rewards based on pairwise comparisons of individual responses. However, this approach imposes significant challenges on reward model (RM), as the inherent variability in prompt-response pairs across different contexts demands robust calibration capabilities from the RM. Second, reward models are typically initialized from generative foundation models, such as pre-trained or supervised fine-tuned models, despite the fact that reward models perform discriminative tasks, creating a mismatch. This paper introduces Pairwise-RL, a RLHF framework that addresses these challenges through a combination of generative reward modeling and a pairwise proximal policy optimization (PPO) algorithm. Pairwise-RL unifies reward model training and its application during reinforcement learning within a consistent pairwise paradigm, leveraging generative modeling techniques to enhance reward model performance and score calibration. Experimental evaluations demonstrate that Pairwise-RL outperforms traditional RLHF frameworks across both internal evaluation datasets and standard public benchmarks, underscoring its effectiveness in improving alignment and model behavior.
Principle과 응답 페어를 입력으로 사용하는 Generative Reward Model과 Pairwise PPO의 결합. RLHF 쪽은 비슷한 방향으로 흘러가고 있네요.
A combination of a generative reward model that uses principle and response pairs as input and pairwise PPO. It seems that RLHF approaches are converging in similar directions.
#rlhf #reward-model
Retro-Search: Exploring Untaken Paths for Deeper and Efficient Reasoning
(Ximing Lu, Seungju Han, David Acuna, Hyunwoo Kim, Jaehun Jung, Shrimai Prabhumoye, Niklas Muennighoff, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Yejin Choi)

Large reasoning models exhibit remarkable reasoning capabilities via long, elaborate reasoning trajectories. Supervised fine-tuning on such reasoning traces, also known as distillation, can be a cost-effective way to boost reasoning capabilities of student models. However, empirical observations reveal that these reasoning trajectories are often suboptimal, switching excessively between different lines of thought, resulting in under-thinking, over-thinking, and even degenerate responses. We introduce Retro-Search, an MCTS-inspired search algorithm, for distilling higher quality reasoning paths from large reasoning models. Retro-Search retrospectively revises reasoning paths to discover better, yet shorter traces, which can then lead to student models with enhanced reasoning capabilities with shorter, thus faster inference. Our approach can enable two use cases: self-improvement, where models are fine-tuned on their own Retro-Search-ed thought traces, and weak-to-strong improvement, where a weaker model revises stronger model's thought traces via Retro-Search. For self-improving, R1-distill-7B, fine-tuned on its own Retro-Search-ed traces, reduces the average reasoning length by 31.2% while improving performance by 7.7% across seven math benchmarks. For weak-to-strong improvement, we retrospectively revise R1-671B's traces from the OpenThoughts dataset using R1-distill-32B as the Retro-Search-er, a model 20x smaller. Qwen2.5-32B, fine-tuned on this refined data, achieves performance comparable to R1-distill-32B, yielding an 11.3% reduction in reasoning length and a 2.4% performance improvement compared to fine-tuning on the original OpenThoughts data. Our work counters recently emergent viewpoints that question the relevance of search algorithms in the era of large reasoning models, by demonstrating that there are still opportunities for algorithmic advancements, even for frontier models.
Reasoning Trace에 대해 MCTS를 사용해 개선된 Trace를 만든다는 아이디어. Trace 분할의 단위가 Wait 같은 키워드네요. Cold Start 데이터 구축 등에 사용할 수 있지 않을까 싶네요.
This paper presents the idea of using MCTS to create improved reasoning traces. The unit for segmenting traces is keywords like "Wait". I think this approach could potentially be used for constructing cold start data.
#reasoning #synthetic-data #search
Rethinking Reflection in Pre-Training
(Essential AI)

A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
오류가 있는 CoT에 대해 Wait 같은 키워드로 오류 수정을 유도했을 때 오류를 수정하는 능력이 프리트레이닝 연산량에 따라 증가한다는 분석. 프리트레이닝과 추론 포스트트레이닝의 관계를 좀 더 잘 이해하는 것이 앞으로 중요하겠죠.
This analysis shows that the ability to correct errors in faulty CoT when induced it with keywords like "Wait" increases with pre-training compute. It will be important to better understand the relationship between pre-training and reasoning post-training.
#scaling-law #reasoning
Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
(Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, Christopher D. Manning)

Reinforcement learning has been shown to improve the performance of large language models. However, traditional approaches like RLHF or RLAIF treat the problem as single-step. As focus shifts toward more complex reasoning and agentic tasks, language models must take multiple steps of text generation, reasoning and environment interaction before generating a solution. We propose a synthetic data generation and RL methodology targeting multi-step optimization scenarios. This approach, called Step-Wise Reinforcement Learning (SWiRL), iteratively generates multi-step reasoning and tool use data, and then learns from that data. It employs a simple step-wise decomposition that breaks each multi-step trajectory into multiple sub-trajectories corresponding to each action by the original model. It then applies synthetic data filtering and RL optimization on these sub-trajectories. We evaluated SWiRL on a number of multi-step tool use, question answering, and mathematical reasoning tasks. Our experiments show that SWiRL outperforms baseline approaches by 21.5%, 12.3%, 14.8%, 11.1%, and 15.3% in relative accuracy on GSM8K, HotPotQA, CofCA, MuSiQue, and BeerQA, respectively. Excitingly, the approach exhibits generalization across tasks: for example, training only on HotPotQA (text question-answering) improves zero-shot performance on GSM8K (a math dataset) by a relative 16.9%.
Multi Step 도구 사용과 추론을 위한 데이터 생성과 RL 방법. 그런데 Ground Truth 사용 없이 Reward Model만으로 액션만을 평가하는 형태군요.
This is a method for data generation and RL for multi-step tool use and reasoning. Interestingly, it evaluates actions solely using reward models, without relying on ground truth data.
#rl #reasoning #tool #synthetic-data