



2025년 4월 7일

Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
(NVIDIA)

As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3× faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
NVIDIA의 Mamba 2 - Attention 하이브리드 모델이군요. Window와 Global Attention의 조합은 기본이 되었고 State Space Model을 사용한 하이브리드와 Sparse Attention이 다음 주자군요.
This is NVIDIA's Mamba 2 - Attention hybrid model. The combination of window and global attention has become standard, and the next contenders are hybrids using state space models and sparse attention.
#llm #state-space-model
AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
(Bingxiang He, Wenbin Zhang, Jiaxi Song, Cheng Qian, Zixuan Fu, Bowen Sun, Ning Ding, Haiwen Hong, Longtao Huang, Hui Xue, Ganqu Cui, Wanxiang Che, Zhiyuan Liu, Maosong Sun)

Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference Annotations, Instructions, and Response Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose AIR, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.
Preference 데이터셋 구축에서 어노테이션 방법, Instruction 선택, Response Pair 생성 각각을 분석. 일단 Judge Model이 있다는 가정 하에서의 분석이긴 합니다. LLM에 따른 응답의 점수 편차가 작은 Instruction을 선택하고, 점수가 높으면서 Pair 사의 차이가 적당한 Pair를 선택하라고 하는군요.
This paper analyzes each component of preference dataset construction of annotation methods, instruction selection, and response pair generation. The analysis is conducted under the assumption that a judge model exists. The authors suggest selecting instructions with lower score variance across different LLMs, and choosing response pairs that have high absolute scores while maintaining moderate differences between the pairs.
#reward-model #alignment
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
(Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu)
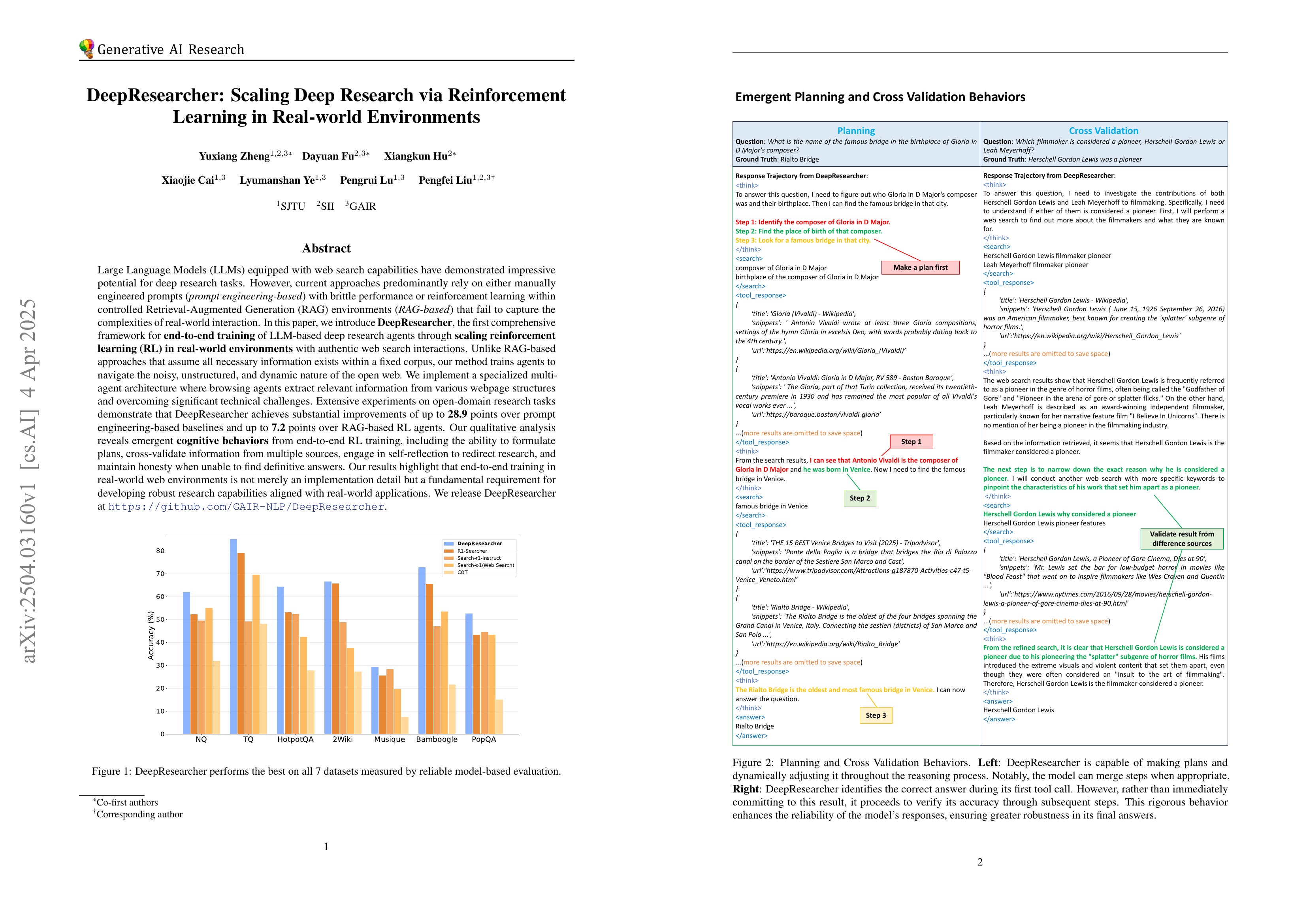
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually engineered prompts (prompt engineering-based) with brittle performance or reinforcement learning within controlled Retrieval-Augmented Generation (RAG) environments (RAG-based) that fail to capture the complexities of real-world interaction. In this paper, we introduce DeepResearcher, the first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling reinforcement learning (RL) in real-world environments with authentic web search interactions. Unlike RAG-based approaches that assume all necessary information exists within a fixed corpus, our method trains agents to navigate the noisy, unstructured, and dynamic nature of the open web. We implement a specialized multi-agent architecture where browsing agents extract relevant information from various webpage structures and overcoming significant technical challenges. Extensive experiments on open-domain research tasks demonstrate that DeepResearcher achieves substantial improvements of up to 28.9 points over prompt engineering-based baselines and up to 7.2 points over RAG-based RL agents. Our qualitative analysis reveals emergent cognitive behaviors from end-to-end RL training, including the ability to formulate plans, cross-validate information from multiple sources, engage in self-reflection to redirect research, and maintain honesty when unable to find definitive answers. Our results highlight that end-to-end training in real-world web environments is not merely an implementation detail but a fundamental requirement for developing robust research capabilities aligned with real-world applications. We release DeepResearcher at https://github.com/GAIR-NLP/DeepResearcher.
검색과 RL 추론을 결합해 검색을 통해 응답하는 에이전트를 학습시키는 연구는 계속 나오고 있네요. Deep Research의 특징 중 하나는 어마어마한 길이의 리포트인데 이것이 RL 파이프라인과 어떻게 결합할 수 있을지가 궁금한 부분입니다.
Research on developing agents that can respond through search by combining search tools with RL reasoning continues to emerge. One of the notable characteristics of Deep Research is its extremely long reports, and I'm curious about how this can be effectively integrated with RL pipelines.
#rl #reasoning
Thoughts on Llama 4
이미 수많은 사람들이 이야기하고 있고 앞으로도 이야기할 것이기 때문에 거기에 노이즈를 추가하는 것에는 좀 조심스럽긴 하다.
Scout, Maverick, Behemoth라는 세 가지 모델 규모가 나왔는데 세팅이 좀 혼란스럽다. 예를 들어 Scout에는 QK Norm에 (Weight 없는 RMSNorm) RoPE Scaling을 사용했고 Maverick은 그렇지 않다. 그리고 Maverick만 Behemoth에서 Distill을 했고, Scout는 40T, Maverick는 22T 학습이다. 모델 개발 과정이 선형적으로 순탄하지는 않았다는 증거일지도.
모델 구조적으로는 모두 MoE를 사용했다. 다만 좀 고전적인 스타일의 Top 1 MoE이여기에 Shared Expert, Sigmoid Routing을 사용한 정도. Fine-grained MoE가 명백히 대세이긴 한데 통신량 증가 같은 귀찮은 부분들이 있긴 하다. 그 때문이었는지 큰 고의는(?) 없었는지는 물론 알 수 없다.
또 하나의 대세인 Local Attention과 Global Attention의 조합. Local Attention은 Window Attention이 아니라 (0, K) 내의 구간에서는 (0, K)에만, (K, 2K) 구간에는 (K, 2K) 구간에만 Attention을 계산하는 Chunked Attention이다. 훨씬 단순하긴 하다.
Long Context 대응으로 Global Attention에는 NoPE를 사용하고 Scaled Softmax를 사용 (https://arxiv.org/abs/2501.19399). NoPE가 Position Encoding으로서의 역할을 하지 못하는 것은 아니지만 Long Context에서는 위치에 대한 명확한 구분보다 의미 기반 Retrieval이 더 필요하다는 의미일 수 있다. 예컨대 1M 거리에 있는 토큰의 위치가 1M인지 1M + 1인지는 그렇게 중요하지 않을 것이다 (https://arxiv.org/abs/2501.18795). 그리고 Softmax Scaling을 통한 길이에 따른 Attention Score의 엔트로피 증가를 억제.
그렇지만 Llama 4의 Long Context 능력은 현재 논란이 있다. (https://x.com/ficlive/status/1908911992686931989)
MetaP라고 하는 Hyperparameter Transfer 기법으로 서로 다른 배치 크기, 모델 폭, 깊이에 대해 Hyperparameter Transfer를 할 수 있었다고. muP 같은 계통의 방법일 듯 한데 모델 구현에는 Multiplier 등의 흔적은 없다. (Weight에 합쳤을지도.)
이미지와 비디오 등을 포함해 30T 토큰 정도가 유니크 토큰인 것 같다. 다국어 데이터가 Llama 3에 비해 10배 증가했다고 하니 대략 12T 토큰이 다국어 토큰인 듯.
FP8 학습을 했고 Behemoth가 20% MFU 정도. MoE로 인한 오버헤드의 영향이 있을지도.
멀티모달은 Cross Attention에서 입력 시퀀스에 포함시키는 형태로.
포스트트레이닝. 요즘 흔히 이야기하는 것처럼 과도한 SFT와 DPO가 RL 과정에서의 Exploration을 방해한다는 언급을 한다. 그래서 쉬운 데이터들을 필터링하고 "Lightweight" SFT와 DPO를 했다고.
이전에 떠돌았던 DeepSeek 때문에 메타가 뒤집혔다던 루머가 사실일지도 모르겠다. 블로그에 나온 DeepSeek V3와의 비교들을 참조한다면. 물론 대놓고 2T 규모인 Behemoth은 다른 레벨이긴 하다.
현재 성능 문제가 계속 언급되고 있다. (https://aider.chat/docs/leaderboards/)
개발 과정과 팀 및 회사 내의 동역학이라거나 포스트트레이닝 방법과 방향에 대한 취향 등에 대한 추측도 하게 되지만 그것은 생략하는 게 맞을지도.
Many people are now talking about Llama 4, and there are many controversies currently. So I'm somewhat cautious about adding more noise on this topic.
There are 3 model scales, namely Scout, Maverick, and Behemoth. But overall model settings seem inconsistent across models. For example, Scout uses QK norm (RMSNorm without weights) and RoPE scaling, but Maverick does not. Also, Maverick is distilled from Behemoth and trained on 22T tokens, while Scout is trained on 40T tokens. This may suggest that the overall model development was not linear.
All the models use MoE, but they implement a classical style Top-1 MoE with shared experts and sigmoid routing. Fine-grained MoE is definitely the go-to approach these days. While it can have some caveats like increased communication volumes, it's not apparent whether they considered those factors or simply adopted more conservative choices.
They used a combination of local and global attention mechanisms, which is also common these days. The local attention uses chunked attention that computes queries on the interval of (0, K) with attention scores only on (0, K), and for (K, 2K), only on (K, 2K). It is much simpler.
They addressed long context handling with global attention using NoPE and scaled softmax (https://arxiv.org/abs/2501.19399). While NoPE itself can function as positional encoding, it suggests that semantic retrieval is more important than precise position distinction for long contexts. For example, it might not be very important to distinguish between positions at 1M and 1M+1 tokens (https://arxiv.org/abs/2501.18795). They also suppressed the increase of entropy using scaled softmax.
However, the long context capability of Llama 4 is currently under controversy (https://x.com/ficlive/status/1908911992686931989).
They employed hyperparameter transfer techniques called MetaP, which allowed them to transfer hyperparameters between different batch sizes, model widths, and depths. I suspect it is a method in line with muP, but there are no traces in the model implementations like multipliers (perhaps they merged it into the weights).
About 30T tokens appear to be unique, including image and video tokens. As they report a 10-fold increase in multilingual data from Llama 3, around 12T tokens would be multilingual.
They conducted FP8 training, and Behemoth achieved about 20% MFU. This might reflect overhead from the MoE architecture.
Instead of cross attention, they use plain in-sequence inputs for multimodal processing.
Regarding post-training, as is commonly noted these days, they suggest that excessive SFT and DPO can hinder exploration. So they filtered out easy samples and performed what they call "Lightweight" SFT and DPO.
Perhaps the rumor that Meta was in panic due to DeepSeek is true. You can refer to comparisons with DeepSeek V3 in the blog. Of course, Behemoth with its 2T parameters is playing at a totally different scale.
Currently, many sources are reporting performance problems with Llama 4 (https://aider.chat/docs/leaderboards/).
The available information leads to speculation about the development process, team dynamics, and post-training approaches, but it might be better to refrain from such speculation.