



2025년 4월 4일

MegaMath: Pushing the Limits of Open Math Corpora
(Fan Zhou, Zengzhi Wang, Nikhil Ranjan, Zhoujun Cheng, Liping Tang, Guowei He, Zhengzhong Liu, Eric P. Xing)

Mathematical reasoning is a cornerstone of human intelligence and a key benchmark for advanced capabilities in large language models (LLMs). However, the research community still lacks an open, large-scale, high-quality corpus tailored to the demands of math-centric LLM pre-training. We present MegaMath, an open dataset curated from diverse, math-focused sources through following practices: (1) Revisiting web data: We re-extracted mathematical documents from Common Crawl with math-oriented HTML optimizations, fasttext-based filtering and deduplication, all for acquiring higher-quality data on the Internet. (2) Recalling Math-related code data: We identified high quality math-related code from large code training corpus, Stack-V2, further enhancing data diversity. (3) Exploring Synthetic data: We synthesized QA-style text, math-related code, and interleaved text-code blocks from web data or code data. By integrating these strategies and validating their effectiveness through extensive ablations, MegaMath delivers 371B tokens with the largest quantity and top quality among existing open math pre-training datasets.
수학 및 코드 데이터 371B. Common Crawl에서 추출한 수학 데이터만 해도 279B군요.
The corpus contains 371B tokens of math and code data. Remarkably, 279B tokens of this are mathematical text extracted from common crawl alone.
#math #corpus #pretraining
MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
(Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, Xin Liu)

Mixture-of-Experts (MoE) showcases tremendous potential to scale large language models (LLMs) with enhanced performance and reduced computational complexity. However, its sparsely activated architecture shifts feed-forward networks (FFNs) from being compute-intensive to memory-intensive during inference, leading to substantially lower GPU utilization and increased operational costs. We present MegaScale-Infer, an efficient and cost-effective system for serving large-scale MoE models. MegaScale-Infer disaggregates attention and FFN modules within each model layer, enabling independent scaling, tailored parallelism strategies, and heterogeneous deployment for both modules. To fully exploit disaggregation in the presence of MoE's sparsity, MegaScale-Infer introduces ping-pong pipeline parallelism, which partitions a request batch into micro-batches and shuttles them between attention and FFNs for inference. Combined with distinct model parallelism for each module, MegaScale-Infer effectively hides communication overhead and maximizes GPU utilization. To adapt to disaggregated attention and FFN modules and minimize data transmission overhead (e.g., token dispatch), MegaScale-Infer provides a high-performance M2N communication library that eliminates unnecessary GPU-to-CPU data copies, group initialization overhead, and GPU synchronization. Experimental results indicate that MegaScale-Infer achieves up to 1.90x higher per-GPU throughput than state-of-the-art solutions.
ByteDance의 MoE 서빙 프레임워크. Attention과 FFN을 분리하고 Pipeline Parallel로 이 둘 사이를 오가는 형태군요. 오픈소스 쪽에서는 Prefill과 Decode의 분리도 이제 도입되고 있는 상황이라는 걸 생각하면 격차가 꽤 있네요.
ByteDance's MoE serving framework. They decoupled attention and FFN modules and implemented pipeline parallelism to shuttle between the two. Considering that open-source solutions are only now starting to adopt the separation of prefill and decode stages, there seems to be a significant gap between this and company-internal serving framework solutions.
#efficiency
Inference-Time Scaling for Generalist Reward Modeling
(Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, Yu Wu)
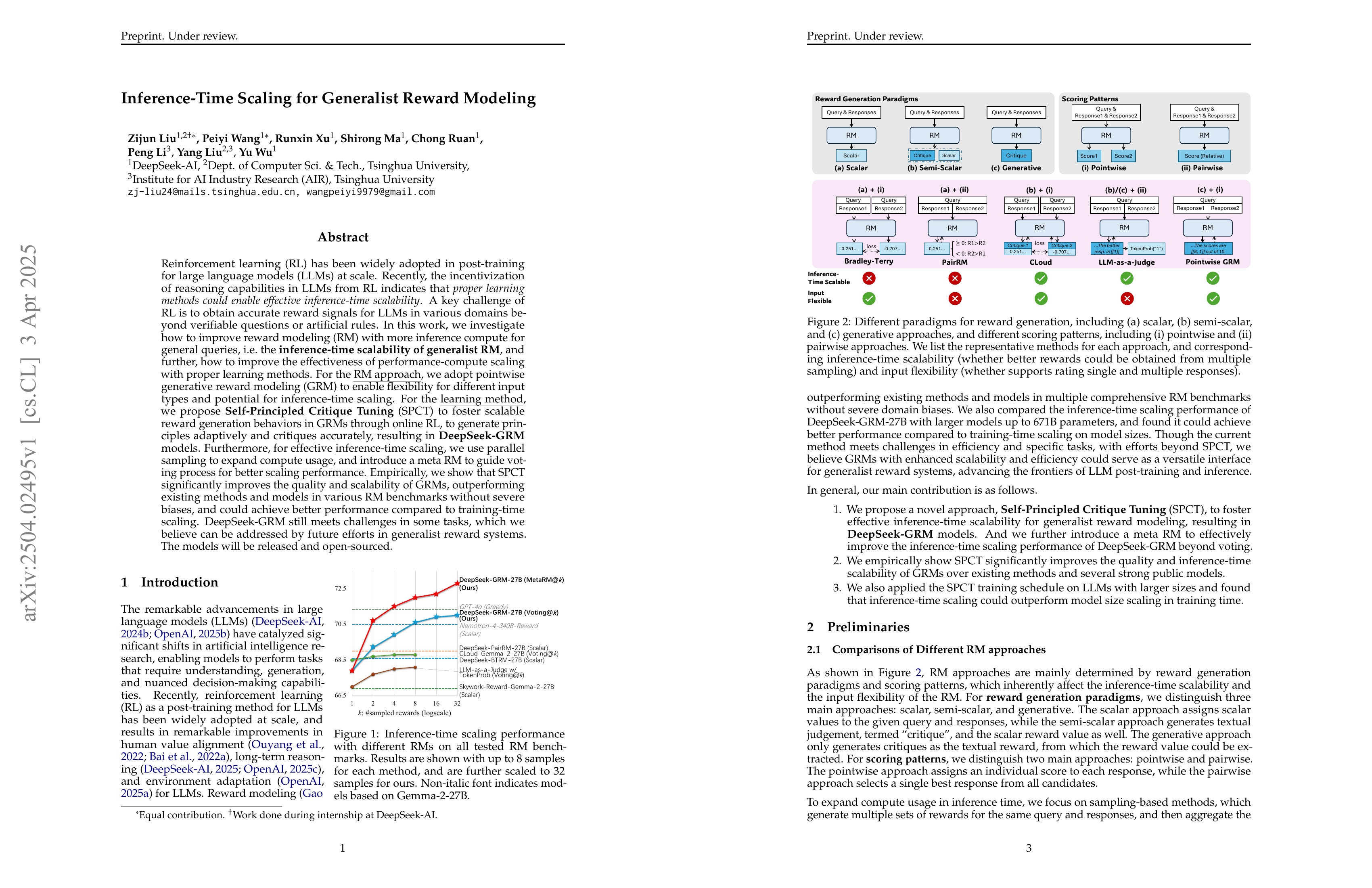
Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that proper learning methods could enable effective inference-time scalability. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the inference-time scalability of generalist RM, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in DeepSeek-GRM models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models will be released and open-sourced.
Generative, Pointwise (vs. Pairwise) Reward Model이군요. Principle을 사용하는데 Principle을 모델이 생성할 수 있도록 했습니다. 그리고 RL로 학습시켰군요. 이를 통해 Reward Model을 Inference Time Scaling 할 수 있도록 만들었네요. 새로운 세대의 Reward Model의 디자인이 점점 드러나고 있네요.
This is a generative, pointwise (as opposed to pairwise) reward model. It utilizes principles, but interestingly, the model is designed to generate these principles on its own. The model is then trained using RL. Through this approach, they've enabled the reward model to perform inference-time scaling. We can see the design of next-generation reward models gradually taking shape.
#inference-time-scaling #reward-model #rl
On Vanishing Variance in Transformer Length Generalization
(Ruining Li, Gabrijel Boduljak, Jensen (Jinghao)Zhou)

It is a widely known issue that Transformers, when trained on shorter sequences, fail to generalize robustly to longer ones at test time. This raises the question of whether Transformer models are real reasoning engines, despite their impressive abilities in mathematical problem solving and code synthesis. In this paper, we offer a vanishing variance perspective on this issue. To the best of our knowledge, we are the first to demonstrate that even for today's frontier models, a longer sequence length results in a decrease in variance in the output of the multi-head attention modules. On the argmax retrieval and dictionary lookup tasks, our experiments show that applying layer normalization after the attention outputs leads to significantly better length generalization. Our analyses attribute this improvement to a reduction-though not a complete elimination-of the distribution shift caused by vanishing variance.
Long Context 상황에서 Attention 출력의 분산이 낮아지는 것이 문제라는 지적. Attention Score의 엔트로피가 높아지는 것과 연결해서 생각할 수 있을 것 같네요. 완화하는 방법은 Attention 출력에 Layer Norm을 붙이는 것이라고. Post Norm이군요.
The paper points out that the reduction in variance of attention outputs in long context situations is problematic. I think this can be linked to the issue of increasing entropy in attention scores. They mitigated this problem by applying layer normalization after the attention outputs. It's post norm.
#transformer #long-context