



2025년 4월 3일

Scaling Language-Free Visual Representation Learning
(David Fan, Shengbang Tong, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Yann LeCun, Amir Bar, Saining Xie)

Visual Self-Supervised Learning (SSL) currently underperforms Contrastive Language-Image Pretraining (CLIP) in multimodal settings such as Visual Question Answering (VQA). This multimodal gap is often attributed to the semantics introduced by language supervision, even though visual SSL and CLIP models are often trained on different data. In this work, we ask the question: "Do visual self-supervised approaches lag behind CLIP due to the lack of language supervision, or differences in the training data?" We study this question by training both visual SSL and CLIP models on the same MetaCLIP data, and leveraging VQA as a diverse testbed for vision encoders. In this controlled setup, visual SSL models scale better than CLIP models in terms of data and model capacity, and visual SSL performance does not saturate even after scaling up to 7B parameters. Consequently, we observe visual SSL methods achieve CLIP-level performance on a wide range of VQA and classic vision benchmarks. These findings demonstrate that pure visual SSL can match language-supervised visual pretraining at scale, opening new opportunities for vision-centric representation learning.
이미지 SSL 방법이 CLIP에 대비해서 경쟁력 있거나 우수한 Scaling 특성이 나타난다는 연구.
저는 이미지에서는 텍스트로는 완전히 포착되지 않는 특징들을 추출하는 것이 의미있으리라고 생각합니다. 물론 여기서 다룬 건 VQA이긴 하지만요.
This research suggests that image-only SSL methods demonstrate competitive or even superior scaling characteristics compared to CLIP.
I believe it would be beneficial to extract features from images that cannot be fully captured by text alone. (Though this study primarily focused on VQA tasks.)
#clip #self-supervision #scaling-law
Critical Thinking: Which Kinds of Complexity Govern Optimal Reasoning Length?
(Celine Lee, Alexander M. Rush, Keyon Vafa)

Large language models (LLMs) often benefit from verbalized reasoning at inference time, but it remains unclear which aspects of task difficulty these extra reasoning tokens address. To investigate this question, we formalize a framework using deterministic finite automata (DFAs). DFAs offer a formalism through which we can characterize task complexity through measurable properties such as run length (number of reasoning steps required) and state-space size (decision complexity). We first show that across different tasks and models of different sizes and training paradigms, there exists an optimal amount of reasoning tokens such that the probability of producing a correct solution is maximized. We then investigate which properties of complexity govern this critical length: we find that task instances with longer corresponding underlying DFA runs (i.e. demand greater latent state-tracking requirements) correlate with longer reasoning lengths, but, surprisingly, that DFA size (i.e. state-space complexity) does not. We then demonstrate an implication of these findings: being able to predict the optimal number of reasoning tokens for new problems and filtering out non-optimal length answers results in consistent accuracy improvements.
DFA로 표현할 수 있는 과제에서 최적 추론 길이가 어떻게 변화하는지에 대한 분석. DFA의 상태의 수에는 큰 상관이 없고 실행 시간에 영향을 받는다고 하는군요.
An analysis of how the optimal reasoning length changes for tasks that can be represented by DFAs. The study suggests that it is largely unrelated to the number of states in the DFA, but is affected by the run length.
#reasoning
Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
(Zhijun Wang, Jiahuan Li, Hao Zhou, Rongxiang Weng, Jingang Wang, Xin Huang, Xue Han, Junlan Feng, Chao Deng, Shujian Huang)
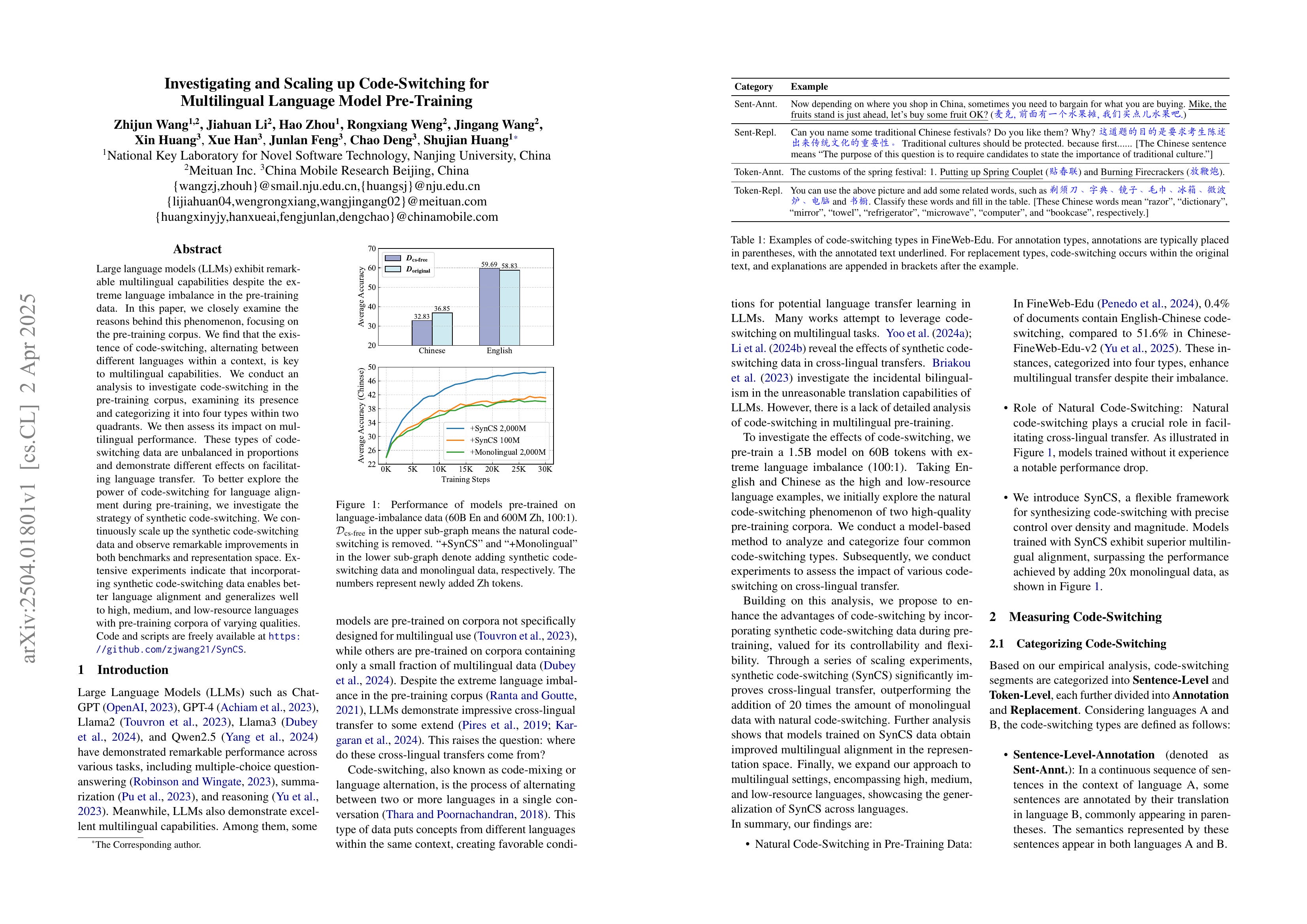
Large language models (LLMs) exhibit remarkable multilingual capabilities despite the extreme language imbalance in the pre-training data. In this paper, we closely examine the reasons behind this phenomenon, focusing on the pre-training corpus. We find that the existence of code-switching, alternating between different languages within a context, is key to multilingual capabilities. We conduct an analysis to investigate code-switching in the pre-training corpus, examining its presence and categorizing it into four types within two quadrants. We then assess its impact on multilingual performance. These types of code-switching data are unbalanced in proportions and demonstrate different effects on facilitating language transfer. To better explore the power of code-switching for language alignment during pre-training, we investigate the strategy of synthetic code-switching. We continuously scale up the synthetic code-switching data and observe remarkable improvements in both benchmarks and representation space. Extensive experiments indicate that incorporating synthetic code-switching data enables better language alignment and generalizes well to high, medium, and low-resource languages with pre-training corpora of varying qualities.
여러 패턴의 Code Switching 데이터를 사용한 Multilingual 성능의 향상 분석. 흥미롭게도 원문과 번역문을 같이 학습시키는 것보다는 아예 번역문으로 대체해버리는 것이 더 효과가 좋았다고 하는군요. 대체의 단위를 어떻게 해야 하는가에는 각 언어의 비율이 영향을 미치는 것 같군요.
Analysis of multilingual performance improvement using various patterns of code-switching data. Interestingly, they found that completely replacing the original text with translated text was more effective than training on both original and translated texts together. It appears that the proportion of each language influences how the unit of replacement should be determined.
#multilingual #synthetic-data #pretraining