



2025년 4월 25일

OctoThinker: Revisiting Mid-Training In the Era of RL Scaling
(Zengzhi Wang, Fan Zhou, Xuefeng Li, Pengfei Liu)
미드트레이닝을 (Mid-Training) 사용해 Llama의 추론 RL 성능을 향상시킨 시도. 이전에도 Llama에서 추론 RL이 잘 되지 않는 이유를 분석하면서 비슷한 시도를 한 연구가 있었죠. (https://arxiv.org/abs/2503.01307) 고품질 데이터와 CoT QA, Instruction Following 데이터를 사용한 학습으로 성능이 높아진다는 결과입니다.
모델이 커졌을 때의 결과, R1에 DeepSeek V3의 데이터 큐레이션이 미친 영향 등이 궁금하긴 합니다.
This study attempts to improve Llama's reasoning RL performance using mid-training. Previously, there was a similar study that analyzed why reasoning RL doesn't work well on Llama (https://arxiv.org/abs/2503.01307) and tried similar method. The results show that performance improves when training with high-quality data, CoT QA, and instruction following data.
I'm curious about the results for larger models and how DeepSeek V3's data curation affected the R1 results.
#reasoning #rl
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
(Xu Ma, Peize Sun, Haoyu Ma, Hao Tang, Chih-Yao Ma, Jialiang Wang, Kunpeng Li, Xiaoliang Dai, Yujun Shi, Xuan Ju, Yushi Hu, Artsiom Sanakoyeu, Felix Juefei-Xu, Ji Hou, Junjiao Tian, Tao Xu, Tingbo Hou, Yen-Cheng Liu, Zecheng He, Zijian He, Matt Feiszli, Peizhao Zhang, Peter Vajda, Sam Tsai, Yun Fu)

Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
이미지 토큰들의 공간축을 임베딩 축으로 접어넣어 시퀀스의 길이를 줄이는 방법. Pixel Shuffle이군요.
This method reduces the sequence length by folding the spatial axis of image tokens into the embedding axis. It's essentially a pixel shuffle.
#autoregressive-model #image-generation #vq
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
(Piotr Nawrot, Robert Li, Renjie Huang, Sebastian Ruder, Kelly Marchisio, Edoardo M. Ponti)

Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its viability, its efficiency-accuracy trade-offs, and systematic scaling studies remain unexplored. To address this gap, we perform a careful comparison of training-free sparse attention methods at varying model scales, sequence lengths, and sparsity levels on a diverse collection of long-sequence tasks-including novel ones that rely on natural language while remaining controllable and easy to evaluate. Based on our experiments, we report a series of key findings: 1) an isoFLOPS analysis reveals that for very long sequences, larger and highly sparse models are preferable to smaller and dense ones. 2) The level of sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding than prefilling, and correlates with model size in the former. 3) There is no clear strategy that performs best across tasks and phases, with different units of sparsification or budget adaptivity needed for different scenarios. Even moderate sparsity levels often result in significant performance degradation on at least one task, highlighting that sparse attention is not a universal solution. 4) We introduce and validate novel scaling laws specifically tailored for sparse attention, providing evidence that our findings are likely to hold true beyond our range of experiments. Through these insights, we demonstrate that sparse attention is a key tool to enhance the capabilities of Transformer LLMs for processing longer sequences, but requires careful evaluation of trade-offs for performance-sensitive applications.
Sparse Attention에 대한 Scaling Law. 컨텍스트 길이가 길어지면 동일 FLOPS에서 우위가 발생하는군요. 학습 없이 Sparse Attention으로 전환한 결과이니 프리트레이닝 시점에서부터 Sparse Attention을 채택한 경우 특성이 좀 더 나아지겠죠.
Scaling law for sparse attention. As the context length increases, it shows advantages at similar FLOPS. Since these results are based on adopting sparse attention without additional training, we can expect even better characteristics if sparse attention is used from the pretraining stage.
#sparsity #attention #scaling-law
DeepDistill: Enhancing LLM Reasoning Capabilities via Large-Scale Difficulty-Graded Data Training
(Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Yunjie Ji, Han Zhao, Xiangang Li)
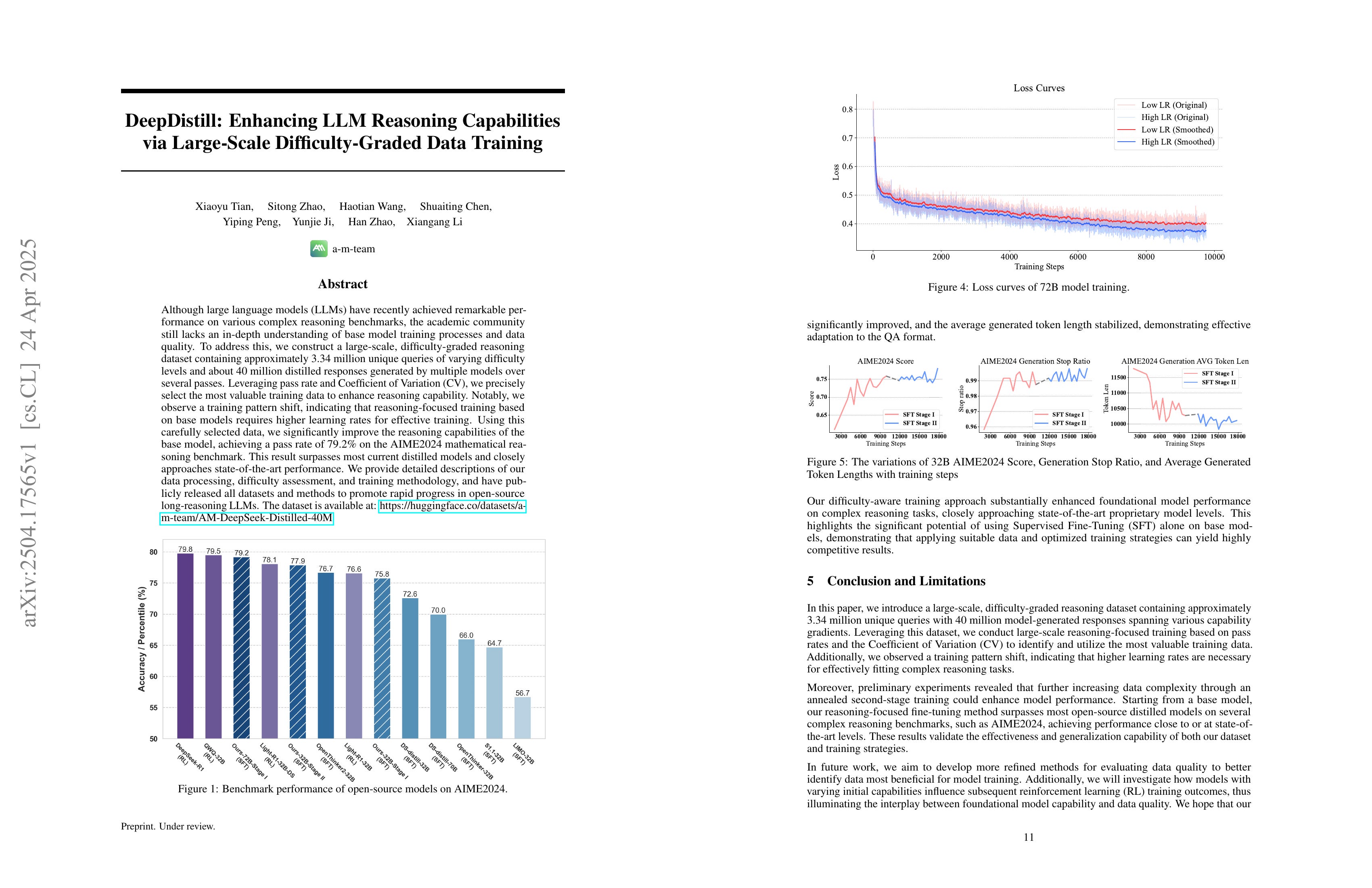
Although large language models (LLMs) have recently achieved remarkable performance on various complex reasoning benchmarks, the academic community still lacks an in-depth understanding of base model training processes and data quality. To address this, we construct a large-scale, difficulty-graded reasoning dataset containing approximately 3.34 million unique queries of varying difficulty levels and about 40 million distilled responses generated by multiple models over several passes. Leveraging pass rate and Coefficient of Variation (CV), we precisely select the most valuable training data to enhance reasoning capability. Notably, we observe a training pattern shift, indicating that reasoning-focused training based on base models requires higher learning rates for effective training. Using this carefully selected data, we significantly improve the reasoning capabilities of the base model, achieving a pass rate of 79.2% on the AIME2024 mathematical reasoning benchmark. This result surpasses most current distilled models and closely approaches state-of-the-art performance. We provide detailed descriptions of our data processing, difficulty assessment, and training methodology, and have publicly released all datasets and methods to promote rapid progress in open-source long-reasoning LLMs. The dataset is available at: https://huggingface.co/datasets/a-m-team/AM-DeepSeek-Distilled-40M
추론 데이터를 대규모로 생성해서 학습. 데이터 전처리 과정에서 점수의 평균 대비 표준편차를 지표로 사용해서 샘플링을 했네요.
Training with a large-scale distilled reasoning dataset. During data preprocessing, they sampled the data using the coefficient of variation (the ratio of standard deviation to mean) of scores as a metric.
#reasoning
When Does Metadata Conditioning (NOT) Work for Language Model Pre-Training? A Study with Context-Free Grammars
(Rei Higuchi, Ryotaro Kawata, Naoki Nishikawa, Kazusato Oko, Shoichiro Yamaguchi, Sosuke Kobayashi, Seiya Tokui, Kohei Hayashi, Daisuke Okanohara, Taiji Suzuki)

The ability to acquire latent semantics is one of the key properties that determines the performance of language models. One convenient approach to invoke this ability is to prepend metadata (e.g. URLs, domains, and styles) at the beginning of texts in the pre-training data, making it easier for the model to access latent semantics before observing the entire text. Previous studies have reported that this technique actually improves the performance of trained models in downstream tasks; however, this improvement has been observed only in specific downstream tasks, without consistent enhancement in average next-token prediction loss. To understand this phenomenon, we closely investigate how prepending metadata during pre-training affects model performance by examining its behavior using artificial data. Interestingly, we found that this approach produces both positive and negative effects on the downstream tasks. We demonstrate that the effectiveness of the approach depends on whether latent semantics can be inferred from the downstream task's prompt. Specifically, through investigations using data generated by probabilistic context-free grammars, we show that training with metadata helps improve model's performance when the given context is long enough to infer the latent semantics. In contrast, the technique negatively impacts performance when the context lacks the necessary information to make an accurate posterior inference.
프리트레이닝에 문서 메타데이터를 사용하는 것에 대한 분석. (https://arxiv.org/abs/2501.01956) 인공적인 세팅이긴 합니다. 메타데이터를 사용하면 메타데이터와 관련된 정보를 추출하는 능력은 약해지겠죠. 프리트레이닝의 문제는 어렵다는 것이 아니라 쉽다는 것에 있지 않나 싶네요.
An analysis of using document metadata for pretraining (https://arxiv.org/abs/2501.01956). Although it's an artificial setting, using metadata will naturally reduce the model's ability to extract metadata-related information. I think the challenge with pretraining lies not in its hardness but rather in its easiness.
#pretraining
Safety Pretraining: Toward the Next Generation of Safe AI
(Pratyush Maini, Sachin Goyal, Dylan Sam, Alex Robey, Yash Savani, Yiding Jiang, Andy Zou, Zacharcy C. Lipton, J. Zico Kolter)

As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
프리트레이닝 데이터에서 안전 문제가 있는 텍스트를 재작성해 오히려 윤리를 가르치는 텍스트로 바꿔 학습시킨 시도. 텍스트를 버리는 것보다는 이쪽이 낫지 않을까 싶습니다. 물론 저는 나쁜 것도 아는 것이 모르는 것보다는 낫지 않나 하는 생각을 합니다만.
This paper attempts to train LLMs by rewriting unsafe data into moral education content, rather than filtering it out completely. I think this approach is better than simply removing the problematic texts. Actually, I personally suspect that it's better to be aware of negative aspects rather than being completely not aware of them.
#safety #pretraining