



2025년 4월 24일

Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
(Chris, Yichen Wei, Yi Peng, Xiaokun Wang, Weijie Qiu, Wei Shen, Tianyidan Xie, Jiangbo Pei, Jianhao Zhang, Yunzhuo Hao, Xuchen Song, Yang Liu, Yahui Zhou)

We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Vision-Language 추론 모델. 롤아웃 그룹이 전부 정답이거나 오답인 경우에 대해 리플레이 버퍼를 쓰는 방법을 사용했군요.
A vision-language reasoning model. They employed a replay buffer for cases where groups of rollouts are either all correct or all incorrect.
#multimodal #rl #reasoning
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
(Fengze Liu, Weidong Zhou, Binbin Liu, Zhimiao Yu, Yifan Zhang, Haobin Lin, Yifeng Yu, Xiaohuan Zhou, Taifeng Wang, Yong Cao)

Quality and diversity are two critical metrics for the training data of large language models (LLMs), positively impacting performance. Existing studies often optimize these metrics separately, typically by first applying quality filtering and then adjusting data proportions. However, these approaches overlook the inherent trade-off between quality and diversity, necessitating their joint consideration. Given a fixed training quota, it is essential to evaluate both the quality of each data point and its complementary effect on the overall dataset. In this paper, we introduce a unified data selection framework called QuaDMix, which automatically optimizes the data distribution for LLM pretraining while balancing both quality and diversity. Specifically, we first propose multiple criteria to measure data quality and employ domain classification to distinguish data points, thereby measuring overall diversity. QuaDMix then employs a unified parameterized data sampling function that determines the sampling probability of each data point based on these quality and diversity related labels. To accelerate the search for the optimal parameters involved in the QuaDMix framework, we conduct simulated experiments on smaller models and use LightGBM for parameters searching, inspired by the RegMix method. Our experiments across diverse models and datasets demonstrate that QuaDMix achieves an average performance improvement of 7.2% across multiple benchmarks. These results outperform the independent strategies for quality and diversity, highlighting the necessity and ability to balance data quality and diversity.
프리트레이닝 코퍼스의 품질과 다양성을 확보하려는 시도. 코퍼스에서 도메인을 나누고 각 도메인에 대해 품질 지표와 샘플링 비율을 모델 학습 실험을 통해 결정.
An attempt to ensure both quality and diversity in the pretraining corpus. The corpus is divided into domains, and quality metrics and sampling ratios for each domain are determined through small-scale model training experiments.
#pretraining #corpus
SplitReason: Learning To Offload Reasoning
(Yash Akhauri, Anthony Fei, Chi-Chih Chang, Ahmed F. AbouElhamayed, Yueying Li, Mohamed S. Abdelfattah)

Reasoning in large language models (LLMs) tends to produce substantially longer token generation sequences than simpler language modeling tasks. This extended generation length reflects the multi-step, compositional nature of reasoning and is often correlated with higher solution accuracy. From an efficiency perspective, longer token generation exacerbates the inherently sequential and memory-bound decoding phase of LLMs. However, not all parts of this expensive reasoning process are equally difficult to generate. We leverage this observation by offloading only the most challenging parts of the reasoning process to a larger, more capable model, while performing most of the generation with a smaller, more efficient model; furthermore, we teach the smaller model to identify these difficult segments and independently trigger offloading when needed. To enable this behavior, we annotate difficult segments across 18k reasoning traces from the OpenR1-Math-220k chain-of-thought (CoT) dataset. We then apply supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to a 1.5B-parameter reasoning model, training it to learn to offload the most challenging parts of its own reasoning process to a larger model. This approach improves AIME24 reasoning accuracy by 24% and 28.3% while offloading 1.35% and 5% of the generated tokens respectively. We open-source our SplitReason model, data, code and logs.
추론 모델의 사고 과정을 외주 주는 방법. 작은 모델로 생성하다가 필요한 경우에 큰 모델의 추론 능력을 도구로 호출하게 만드는 형태군요.
A method for outsourcing the reasoning process of inference models. It's a system where generation is primarily done by small models, but when necessary, they can call upon the reasoning capabilities of larger models as a tool.
#reasoning #efficiency
Process Reward Models That Think
(Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, Lu Wang)

Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models will be released at https://github.com/mukhal/thinkprm.
Process Reward Model에서 CoT를 통해 각 단계에 대한 평가를 하게 하자는 아이디어. Reward Model에 추론이 결합되는 건 자연스러운 흐름이겠죠.
The idea or let process reward model evaluate each step using CoT. Combining reasoning with the reward model seems like a natural progression.
#reward-model #reasoning
A Post-trainer's Guide to Multilingual Training Data: Uncovering Cross-lingual Transfer Dynamics
(Luisa Shimabucoro, Ahmet Ustun, Marzieh Fadaee, Sebastian Ruder)
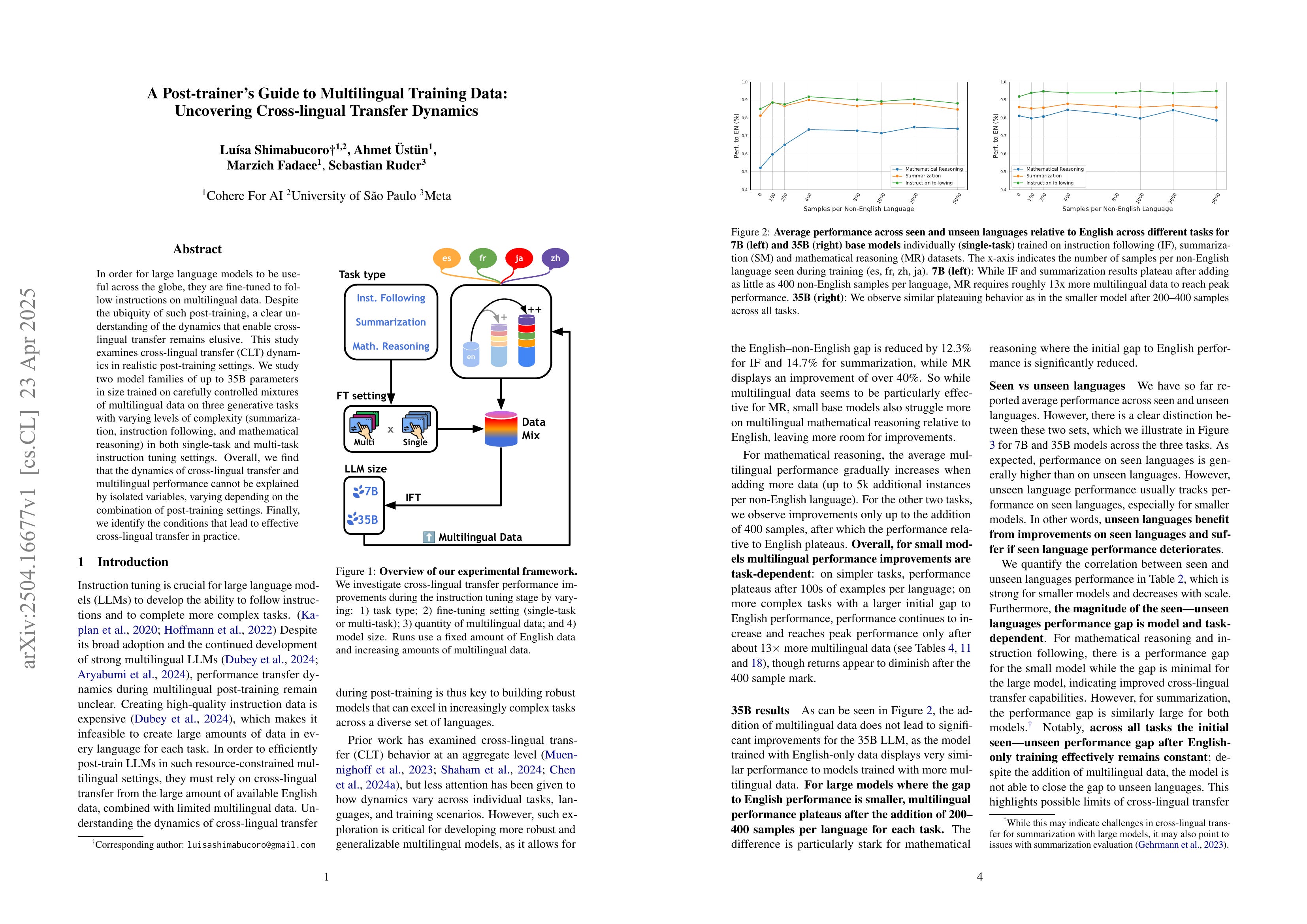
In order for large language models to be useful across the globe, they are fine-tuned to follow instructions on multilingual data. Despite the ubiquity of such post-training, a clear understanding of the dynamics that enable cross-lingual transfer remains elusive. This study examines cross-lingual transfer (CLT) dynamics in realistic post-training settings. We study two model families of up to 35B parameters in size trained on carefully controlled mixtures of multilingual data on three generative tasks with varying levels of complexity (summarization, instruction following, and mathematical reasoning) in both single-task and multi-task instruction tuning settings. Overall, we find that the dynamics of cross-lingual transfer and multilingual performance cannot be explained by isolated variables, varying depending on the combination of post-training settings. Finally, we identify the conditions that lead to effective cross-lingual transfer in practice.
과제, 언어, 모델 크기에 따른 다국어 성능 변화에 대한 분석. 이 요인들이 서로 상호작용합니다만 분명한 것은 모델이 커지면 특성이 상당히 달라진다는 것이네요.
Analysis of multilingual performance changes with respect to tasks, languages, and model sizes. Although these factors interact with each other, it's clear that the characteristics change significantly as the model size increases.
#multilingual