



2025년 4월 21일

Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
(Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang)

Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning capabilities of LLMs, particularly in mathematics and programming tasks. It is widely believed that RLVR enables LLMs to continuously self-improve, thus acquiring novel reasoning abilities that exceed corresponding base models' capacity. In this study, however, we critically re-examines this assumption by measuring the pass@k metric with large values of k to explore the reasoning capability boundary of the models across a wide range of model families and benchmarks. Surprisingly, the RL does not, in fact, elicit fundamentally new reasoning patterns. While RL-trained models outperform their base models at smaller values of k (e.g., k=1), base models can achieve a comparable or even higher pass@k score compared to their RL counterparts at large k values. The reasoning paths generated by RL-trained models are already included in the base models' sampling distribution, suggesting that most reasoning abilities manifested in RL-trained models are already obtained by base models. Further analysis shows that RL training boosts the performance by biasing the model's output distribution toward paths that are more likely to yield rewards, therefore sampling correct responses more efficiently. But this also results in a narrower reasoning capability boundary compared to base models. Similar results are observed in visual reasoning tasks trained with RLVR. Moreover, we find that distillation can genuinely introduce new knowledge into the model, different from RLVR. These findings underscore a critical limitation of RLVR in advancing LLM reasoning abilities which requires us to fundamentally rethink the impact of RL training in reasoning LLMs and the need of a better paradigm. Project Page:
https://limit-of-RLVR.github.io
지금 가장 흥미로운 문제 중 하나인 RL이 베이스 모델의 성능을 확장하는 것인가, 혹은 베이스 모델에 잠재되어 있는 능력을 끌어내는 것인가에 대한 분석. 여기서는 베이스 모델에서도 나올 수 있는 샘플의 확률을 RL이 높여주는 것이고, 반대로 풀 수 있는 문제들의 범위는 줄어든다는 분석을 합니다. 오히려 Distillation이 문제의 범위를 확장시킬 수 있다고 주장하네요.
더 많은 규모의 연산을 투입하고 KL 페널티를 제거했을 때의 패턴까지도 고려해야 하긴 하겠지만, 여하간 프리트레이닝이 여전히 많은 것을 결정한다는 것은 사실 아닐까 싶네요.
This paper analyzes one of the most interesting problem these days, that is, whether RL expands the capabilities of base models or simply unlocks potential abilities already present within them. The authors suggest that RL increases the probability of sampling outputs that are already possible from base models, while actually decreasing the range of solvable problems. Interestingly, they argue that distillation, in contrast, can expand the set of solvable problems.
While we should consider cases where more computations are used and the KL penalty is removed, it seems plausible that pre-training still largely determines many of the model's capabilities.
#rl #reasoning
Dense Backpropagation Improves Training for Sparse Mixture-of-Experts
(Ashwinee Panda, Vatsal Baherwani, Zain Sarwar, Benjamin Therien, Supriyo Chakraborty, Tom Goldstein)

Mixture of Experts (MoE) pretraining is more scalable than dense Transformer pretraining, because MoEs learn to route inputs to a sparse set of their feedforward parameters. However, this means that MoEs only receive a sparse backward update, leading to training instability and suboptimal performance. We present a lightweight approximation method that gives the MoE router a dense gradient update while continuing to sparsely activate its parameters. Our method, which we refer to as Default MoE, substitutes missing expert activations with default outputs consisting of an exponential moving average of expert outputs previously seen over the course of training. This allows the router to receive signals from every expert for each token, leading to significant improvements in training performance. Our Default MoE outperforms standard TopK routing in a variety of settings without requiring significant computational overhead. Code: https://github.com/vatsal0/default-moe.
MoE Router에 대한 Sparse Gradient를 Expert들의 평균 출력을 사용해 Dense Gradient로 전환한다는 아이디어. Sparse Mixer가 생각나네요. (https://arxiv.org/abs/2310.00811) 모델이 커질 때에도 차이가 얼마나 유지될지가 문제겠군요.
The idea of converting the sparse gradient of the MoE router into a dense gradient by using the average outputs of experts. This reminds me of the Sparse Mixer (https://arxiv.org/abs/2310.00811). The key question is whether the performance difference compared to the baseline will be maintained as the model size increases.
#moe
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
(Yixuan Even Xu, Yash Savani, Fei Fang, Zico Kolter)
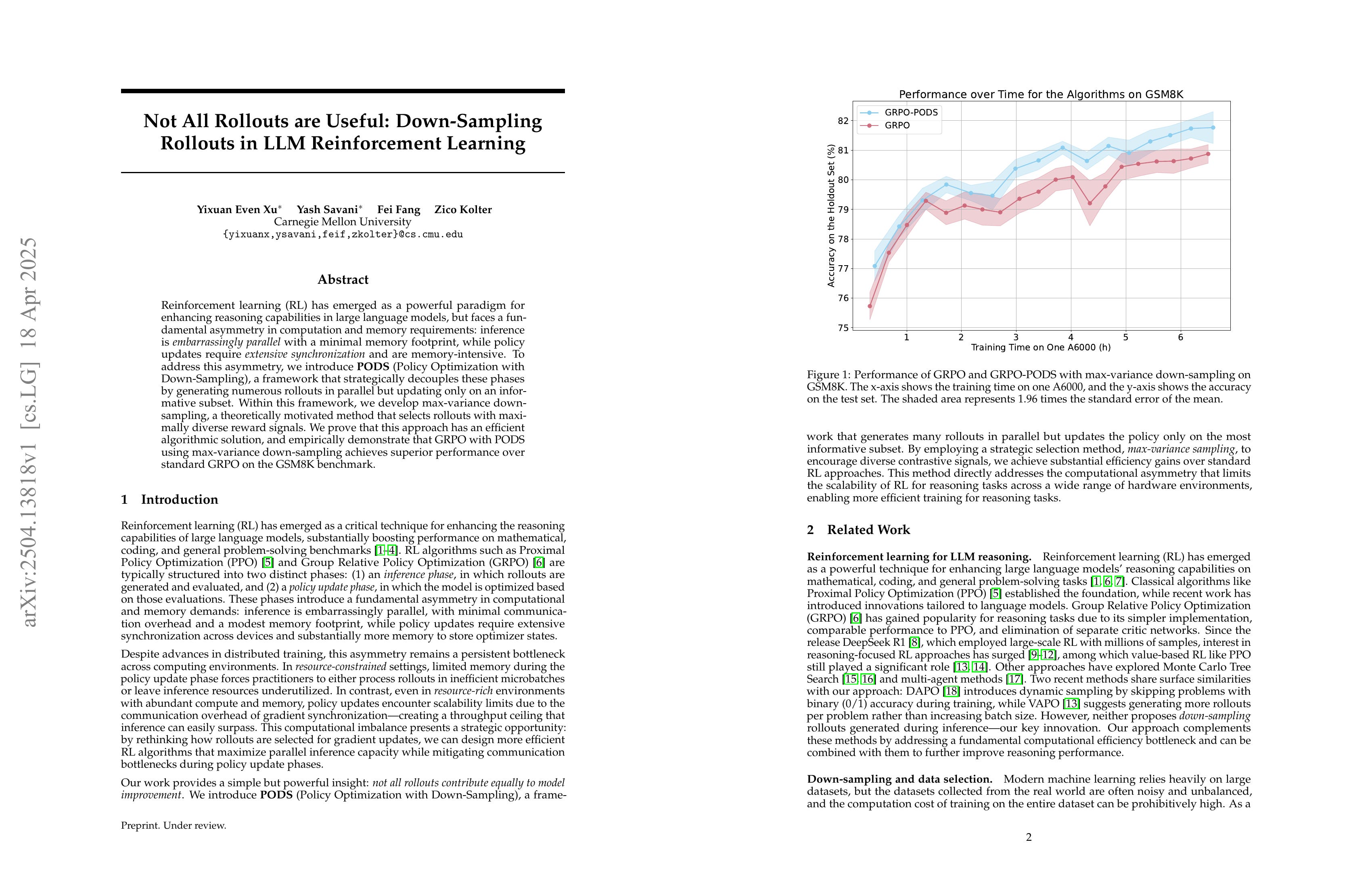
Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing reasoning capabilities in large language models, but faces a fundamental asymmetry in computation and memory requirements: inference is embarrassingly parallel with a minimal memory footprint, while policy updates require extensive synchronization and are memory-intensive. To address this asymmetry, we introduce PODS (Policy Optimization with Down-Sampling), a framework that strategically decouples these phases by generating numerous rollouts in parallel but updating only on an informative subset. Within this framework, we develop max-variance down-sampling, a theoretically motivated method that selects rollouts with maximally diverse reward signals. We prove that this approach has an efficient algorithmic solution, and empirically demonstrate that GRPO with PODS using max-variance down-sampling achieves superior performance over standard GRPO on the GSM8K benchmark.
RL 과정의 샘플링의 규모를 늘리고 그 중에서 Reward의 분산을 최대화 하는 샘플들을 선택한다는 아이디어.
The idea of increasing the number of samples during the RL process and then downsample by selecting samples that maximize the variance of rewards.
#rl