



2025년 4월 14일

GigaTok: Scaling Visual Tokenizers to 3 Billion Parameters for Autoregressive Image Generation
(Tianwei Xiong, Jun Hao Liew, Zilong Huang, Jiashi Feng, Xihui Liu)

In autoregressive (AR) image generation, visual tokenizers compress images into compact discrete latent tokens, enabling efficient training of downstream autoregressive models for visual generation via next-token prediction. While scaling visual tokenizers improves image reconstruction quality, it often degrades downstream generation quality -- a challenge not adequately addressed in existing literature. To address this, we introduce GigaTok, the first approach to simultaneously improve image reconstruction, generation, and representation learning when scaling visual tokenizers. We identify the growing complexity of latent space as the key factor behind the reconstruction vs. generation dilemma. To mitigate this, we propose semantic regularization, which aligns tokenizer features with semantically consistent features from a pre-trained visual encoder. This constraint prevents excessive latent space complexity during scaling, yielding consistent improvements in both reconstruction and downstream autoregressive generation. Building on semantic regularization, we explore three key practices for scaling tokenizers:(1) using 1D tokenizers for better scalability, (2) prioritizing decoder scaling when expanding both encoder and decoder, and (3) employing entropy loss to stabilize training for billion-scale tokenizers. By scaling to 3 billion parameters, GigaTok achieves state-of-the-art performance in reconstruction, downstream AR generation, and downstream AR representation quality.
VQ 토크나이저 Scaling. DINOv2를 사용한 Semantic Regularization이 필수적이군요.
Scaling of VQ tokenizers. Semantic regularization using DINOv2 appears to be essential.
#vq #tokenizer
SWAN-GPT: An Efficient and Scalable Approach for Long-Context Language Modeling
(Krishna C. Puvvada, Faisal Ladhak, Santiago Akle Serrano, Cheng-Ping Hsieh, Shantanu Acharya, Somshubra Majumdar, Fei Jia, Samuel Kriman, Simeng Sun, Dima Rekesh, Boris Ginsburg)

We present a decoder-only Transformer architecture that robustly generalizes to sequence lengths substantially longer than those seen during training. Our model, SWAN-GPT, interleaves layers without positional encodings (NoPE) and sliding-window attention layers equipped with rotary positional encodings (SWA-RoPE). Experiments demonstrate strong performance on sequence lengths significantly longer than the training length without the need for additional long-context training. This robust length extrapolation is achieved through our novel architecture, enhanced by a straightforward dynamic scaling of attention scores during inference. In addition, SWAN-GPT is more computationally efficient than standard GPT architectures, resulting in cheaper training and higher throughput. Further, we demonstrate that existing pre-trained decoder-only models can be efficiently converted to the SWAN architecture with minimal continued training, enabling longer contexts. Overall, our work presents an effective approach for scaling language models to longer contexts in a robust and efficient manner.
Window Attention + RoPE와 Global Attention + NoPE, 그리고 Attention Logit Scaling을 사용한 Length Generalization. Llama 4의 세팅이죠. 이 세팅이 얼마나 효과적인지는 Llama 4를 통해서 확인할 수 있겠죠.
This paper presents a length generalization method using window attention + RoPE and global attention + NoPE, along with attention logit scaling. These are exactly the settings used in Llama 4. We should be able to confirm the effectiveness of these settings through the performance of Llama 4.
#long-context #positional-encoding
Scaling Laws for Native Multimodal Models
(Mustafa Shukor, Enrico Fini, Victor Guilherme Turrisi da Costa, Matthieu Cord, Joshua Susskind, Alaaeldin El-Nouby)

Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training. While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior. In this work, we revisit the architectural design of native multimodal models (NMMs)--those trained from the ground up on all modalities--and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures. Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy. Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows for models that learn modality-specific weights, significantly enhancing performance.
From Scratch 학습한 Multimodal 모델에 대한 Scaling Law. ViT 없는 Early Fusion과 Late Fusion에서는 큰 차이가 나지 않고, (최적 Paramter vs Data 할당 비율은 다릅니다.) 모달리티를 구분하지 않는 MoE가 구분하는 쪽보다 낫군요.
Scaling laws for multimodal models trained from scratch. There's no significant difference between early fusion without ViT and late fusion (though the optimal parameter vs. data allocation ratio differs). Also, modality-agnostic MoE performs better than modality-aware routing.
#scaling-law #multimodal
Seed-Thinking-v1.5: Advancing Superb Reasoning Models with Reinforcement Learning
(ByteDance Seed)
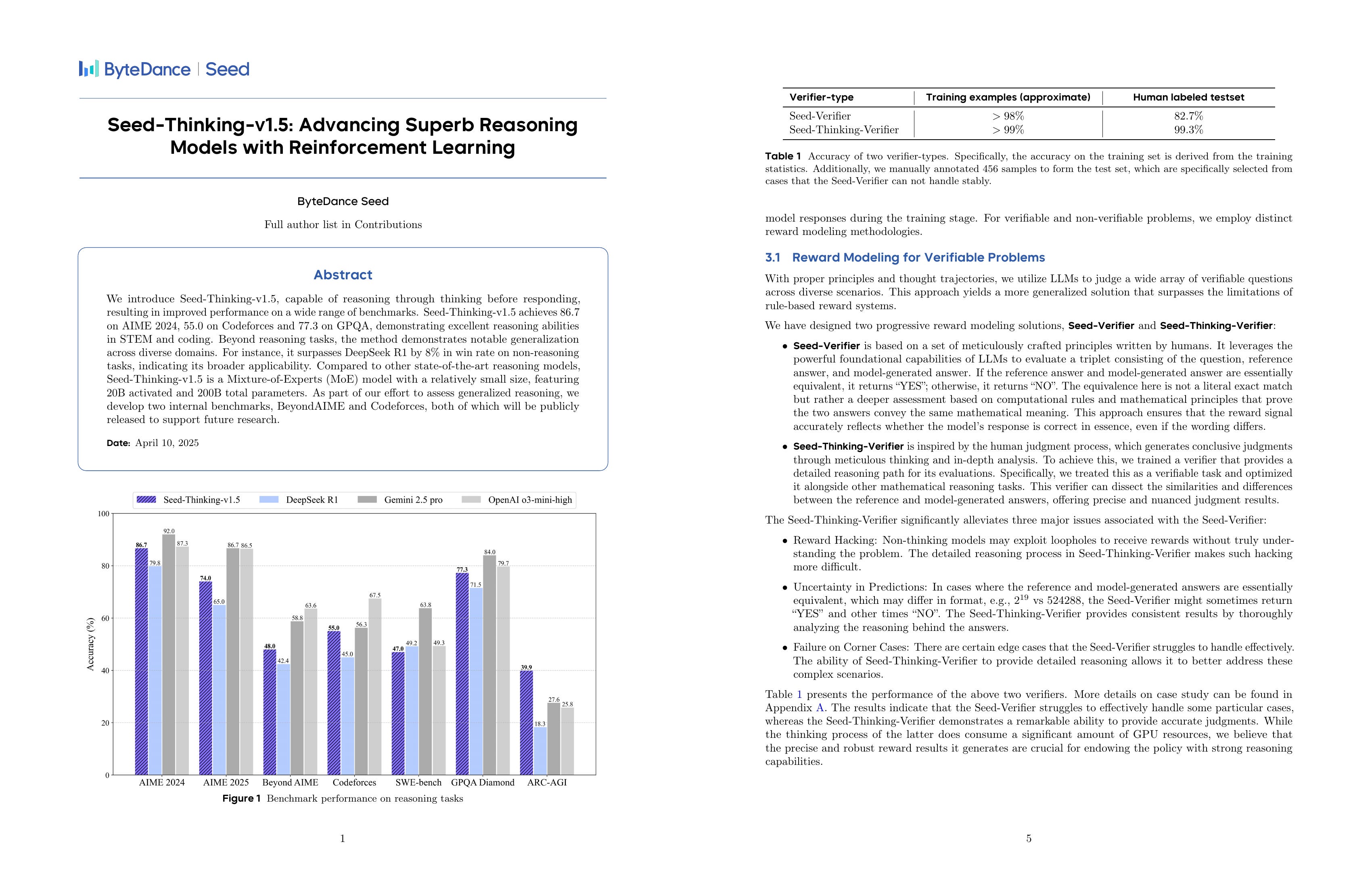
We introduce Seed-Thinking-v1.5, capable of reasoning through thinking before responding, resulting in improved performance on a wide range of benchmarks. Seed-Thinking-v1.5 achieves 86.7 on AIME 2024, 55.0 on Codeforces and 77.3 on GPQA, demonstrating excellent reasoning abilities in STEM and coding. Beyond reasoning tasks, the method demonstrates notable generalization across diverse domains. For instance, it surpasses DeepSeek R1 by 8% in win rate on non-reasoning tasks, indicating its broader applicability. Compared to other state-of-the-art reasoning models, Seed-Thinking-v1.5 is a Mixture-of-Experts (MoE) model with a relatively small size, featuring 20B activated and 200B total parameters. As part of our effort to assess generalized reasoning, we develop two internal benchmarks, BeyondAIME and Codeforces, both of which will be publicly released to support future research.
ByteDance의 추론 모델. 규칙 및 휴리스틱 기반이 아니라 Reference Answer를 입력으로 받아 추론을 통해 검증하는 검증 모델을 사용했네요. 그리고 VAPO를 썼군요 (https://arxiv.org/abs/2504.05118).
ByteDance's reasoning model. Instead of using a rule and heuristic based verifier, they employed a verifier model that takes a reference answer as input and performs verification through reasoning. They also used VAPO (https://arxiv.org/abs/2504.05118).
#reasoning #rl #rlhf