



2025년 3월 7일

Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
(Houyi Li, Wenzheng Zheng, Jingcheng Hu, Qiufeng Wang, Hanshan Zhang, Zili Wang, Yangshijie Xu, Shuigeng Zhou, Xiangyu Zhang, Daxin Jiang)
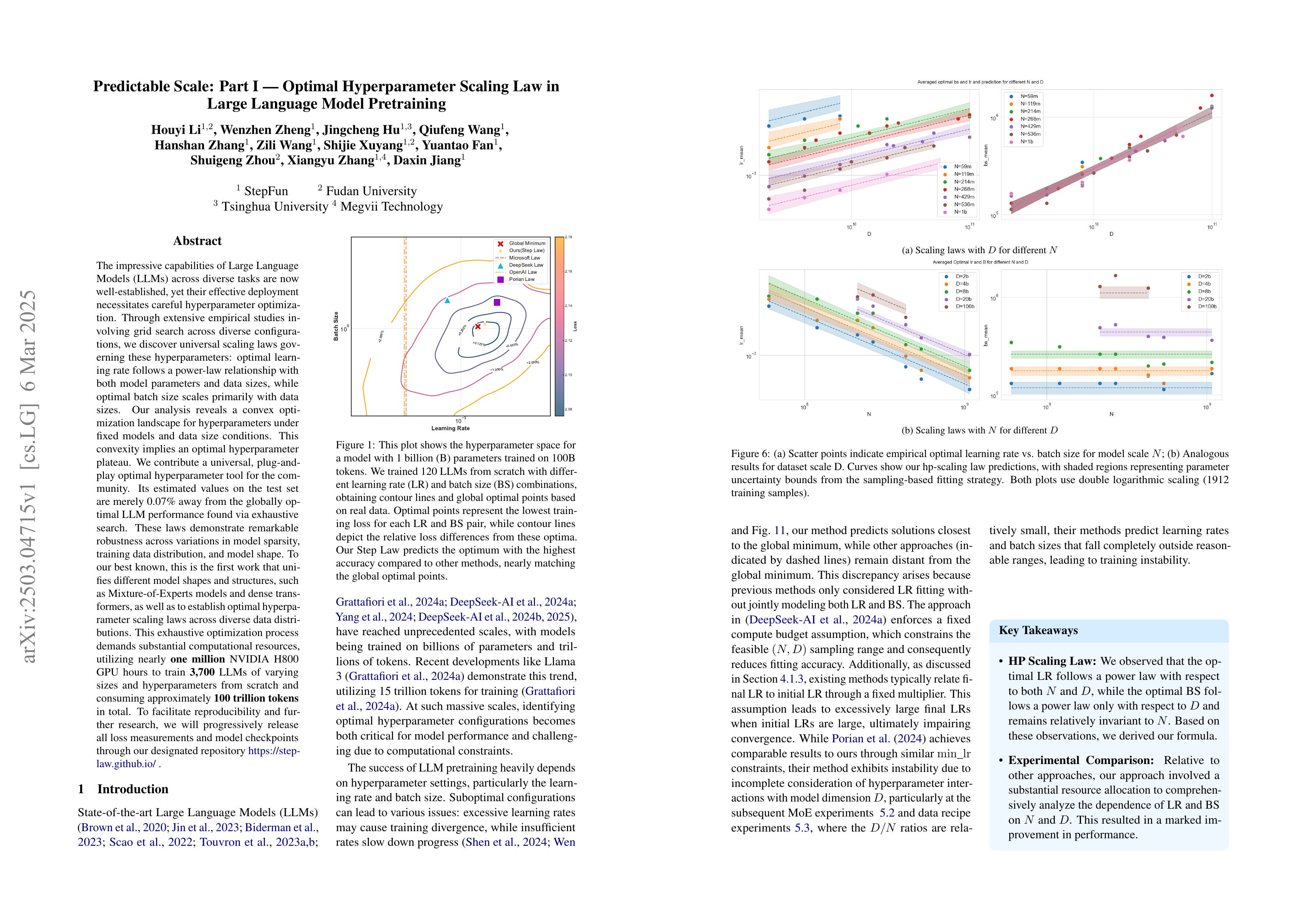
The impressive capabilities of Large Language Models (LLMs) across diverse tasks are now well-established, yet their effective deployment necessitates careful hyperparameter optimization. Through extensive empirical studies involving grid searches across diverse configurations, we discover universal scaling laws governing these hyperparameters: optimal learning rate follows a power-law relationship with both model parameters and data sizes, while optimal batch size scales primarily with data sizes. Our analysis reveals a convex optimization landscape for hyperparameters under fixed models and data size conditions. This convexity implies an optimal hyperparameter plateau. We contribute a universal, plug-and-play optimal hyperparameter tool for the community. Its estimated values on the test set are merely 0.07% away from the globally optimal LLM performance found via an exhaustive search. These laws demonstrate remarkable robustness across variations in model sparsity, training data distribution, and model shape. To our best known, this is the first work that unifies different model shapes and structures, such as Mixture-of-Experts models and dense transformers, as well as establishes optimal hyperparameter scaling laws across diverse data distributions. This exhaustive optimization process demands substantial computational resources, utilizing nearly one million NVIDIA H800 GPU hours to train 3,700 LLMs of varying sizes and hyperparameters from scratch and consuming approximately 100 trillion tokens in total. To facilitate reproducibility and further research, we will progressively release all loss measurements and model checkpoints through our designated repository
https://step-law.github.io/
Hyperparameter Scaling Law. LR은 모델 크기와 학습 데이터의 양에, 배치 크기는 학습 데이터의 양에 의해 결정되는군요. 그리고 이 결과는 모델의 깊이나 너비 등의 차이, MoE에 대한 Sparsity, 그리고 데이터의 차이에 대해 큰 영향이 없었다고 합니다. 굉장한 결과네요.
그런데 파트 2는 뭘까요?
Hyperparameter scaling law. LR is determined by both model and training data sizes while batch size is primarily determined by the amount of training data. Remarkably, these results remain consistent across variations in model depth and width, sparsity in MoE models, and differences in training data composition. These are truly impressive findings.
By the way, I wonder what part 2 will cover?
#scaling-law #hyperparameter
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
(Zhijian Zhuo, Yutao Zeng, Ya Wang, Sijun Zhang, Jian Yang, Xiaoqing Li, Xun Zhou, Jinwen Ma)
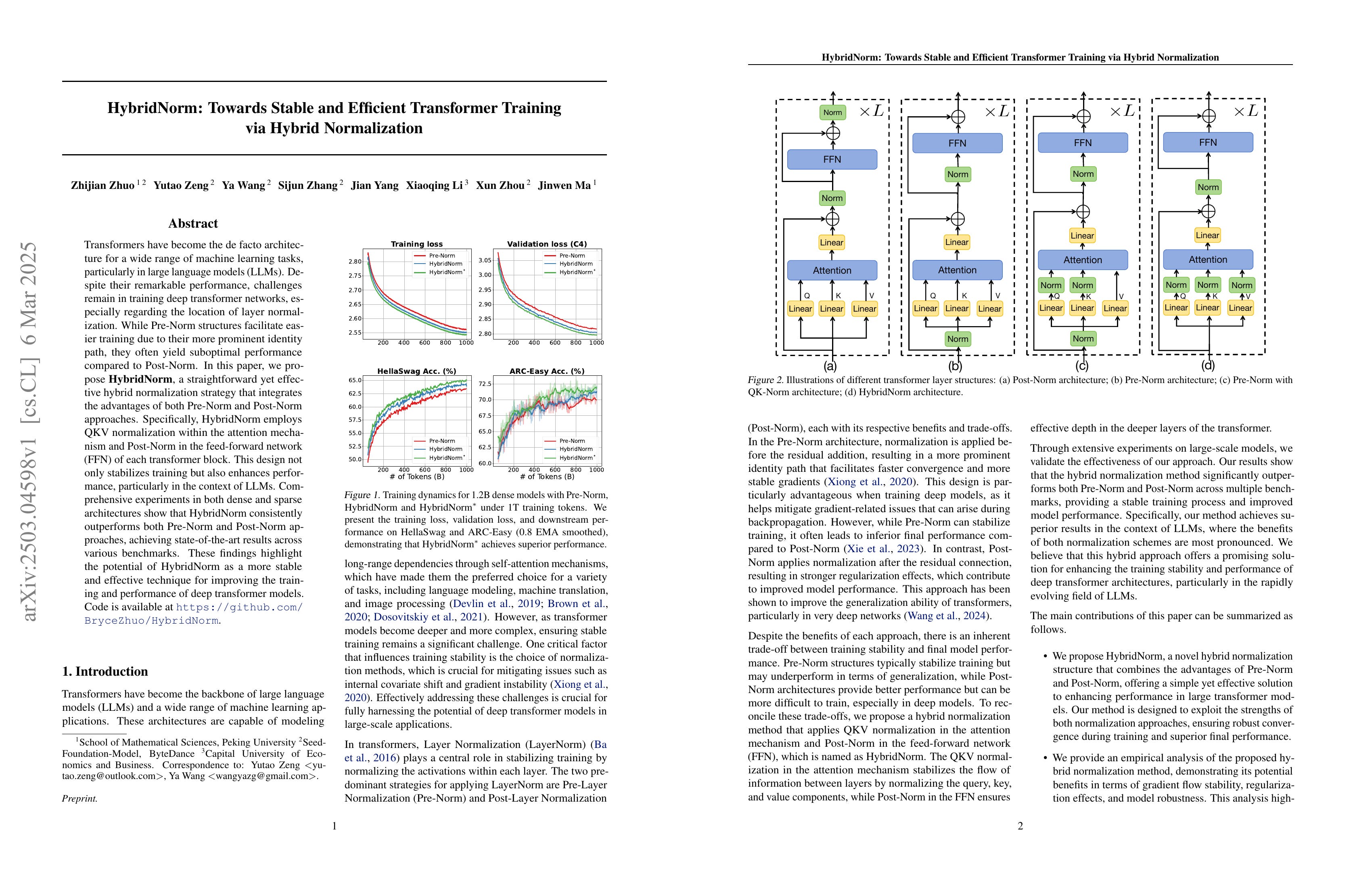
Transformers have become the de facto architecture for a wide range of machine learning tasks, particularly in large language models (LLMs). Despite their remarkable performance, challenges remain in training deep transformer networks, especially regarding the location of layer normalization. While Pre-Norm structures facilitate easier training due to their more prominent identity path, they often yield suboptimal performance compared to Post-Norm. In this paper, we propose HybridNorm, a straightforward yet effective hybrid normalization strategy that integrates the advantages of both Pre-Norm and Post-Norm approaches. Specifically, HybridNorm employs QKV normalization within the attention mechanism and Post-Norm in the feed-forward network (FFN) of each transformer block. This design not only stabilizes training but also enhances performance, particularly in the context of LLMs. Comprehensive experiments in both dense and sparse architectures show that HybridNorm consistently outperforms both Pre-Norm and Post-Norm approaches, achieving state-of-the-art results across various benchmarks. These findings highlight the potential of HybridNorm as a more stable and effective technique for improving the training and performance of deep transformer models. %Code will be made publicly available. Code is available at https://github.com/BryceZhuo/HybridNorm.
Layer Norm 잔혹사. QKV Norm에 Attention 레이어에만 Post Norm을 결합한 형태군요. 그런데 학습 커브의 차이가 꽤 크네요.
Another chapter in the cruel history of layer normalization. This approach combines QKV normalization with post norm, but only in the attention layers. Interestingly, the difference in learning curves is quite significant.
#transformer #normalization
Generalized Interpolating Discrete Diffusion
(Dimitri von Rütte, Janis Fluri, Yuhui Ding, Antonio Orvieto, Bernhard Schölkopf, Thomas Hofmann)

While state-of-the-art language models achieve impressive results through next-token prediction, they have inherent limitations such as the inability to revise already generated tokens. This has prompted exploration of alternative approaches such as discrete diffusion. However, masked diffusion, which has emerged as a popular choice due to its simplicity and effectiveness, reintroduces this inability to revise words. To overcome this, we generalize masked diffusion and derive the theoretical backbone of a family of general interpolating discrete diffusion (GIDD) processes offering greater flexibility in the design of the noising processes. Leveraging a novel diffusion ELBO, we achieve compute-matched state-of-the-art performance in diffusion language modeling. Exploiting GIDD's flexibility, we explore a hybrid approach combining masking and uniform noise, leading to improved sample quality and unlocking the ability for the model to correct its own mistakes, an area where autoregressive models notoriously have struggled. Our code and models are open-source: https://github.com/dvruette/gidd/
Discrete Diffusion 연구들이 많이 나오는 동시에 예측 토큰을 수정하지 못한다는 같은 문제를 태클하고 있네요. Discrete Diffusion을 확장해서 Masking 노이즈 뿐만 아니라 모든 단어에 대한 Uniform Probability 노이즈를 추가하는 방식이네요.
Many recent studies on discrete diffusion are addressing the same issue of the inability to revise predicted tokens. This paper extends discrete diffusion by incorporating uniform probability noise across all vocabulary items in addition to masking noise.
#diffusion #llm
An Empirical Study on Eliciting and Improving R1-like Reasoning Models
(Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, Lei Fang, Zhongyuan Wang, Ji-Rong Wen)

In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
추론 RL에 어떻게 접근해야 하는지가 알려지니 모두들 실험하고 리포트를 작성하고 있네요. 그래서 방향을 제시하는 것, 그리고 그 방향으로 어떻게 나아가야 하는지를 알아내는 것이 무엇보다 더 영향력 있는 일인 것이겠죠.
Now that the approach to reasoning RL has been revealed, everyone is conducting experiments and writing reports. Therefore, suggesting directions and figuring out how to progress along those directions is the most influential work to do.
#reasoning #rl
L^2M: Mutual Information Scaling Law for Long-Context Language Modeling
(Zhuo Chen, Oriol Mayné i Comas, Zhuotao Jin, Di Luo, Marin Soljačić)

We rigorously establish a bipartite mutual information scaling law in natural language that governs long-range dependencies. This scaling law, which we show is distinct from and scales independently of the conventional two-point mutual information, is the key to understanding long-context language modeling. Using this scaling law, we formulate the Long-context Language Modeling (L^2M) condition, which relates a model's capacity for effective long context length modeling to the scaling of its latent state size for storing past information. Our results are validated through experiments on both transformers and state space models. This work establishes a theoretical foundation that guides the development of large language models toward longer context lengths.
텍스트 시퀀스를 둘로 나눴을 때 두 서브시퀀스 사이의 Mutual Information은 시퀀스의 길이에 대해 Power Law를 따른다는 결과에서 Long Context 모델의 상태 크기는 최소한 시퀀스 길이에 대해 Power Law Scaling을 해야 한다는 결론을 유도.
따라서 고정 크기 상태를 사용하는 방법으로는 한계가 있을 수밖에 없겠죠. 여러 레이어를 사용하는 경우에도 상태의 크기는 레이어의 수에 대해 선형적으로 증가하니 한계가 있겠군요. 늘 그렇지만 텍스트 전체의 의미를 벡터 하나에 밀어넣을 수는 없는 것이죠. Dynamic한 Sparse Attention에 대해서는 어떨까요?
The paper suggests that the mutual information between two subsequences in a text sequence follows a power law with respect to sequence length. From this result, they conclude that the state size of long-context models should scale with a power law respect to sequence length.
Therefore, methods using fixed size states are inherently limited. Even when using multiple layers, the state size would only increase linearly with the number of layers, which is still insufficient. As always, you cannot fit the entire text into a single vector. How would this result applied to dynamic sparse attention?
#long-context