



2025년 3월 4일

Training LLMs with MXFP4
(Albert Tseng, Tao Yu, Youngsuk Park)

Low precision (LP) datatypes such as MXFP4 can accelerate matrix multiplications (GEMMs) and reduce training costs. However, directly using MXFP4 instead of BF16 during training significantly degrades model quality. In this work, we present the first near-lossless training recipe that uses MXFP4 GEMMs, which are 2× faster than FP8 on supported hardware. Our key insight is to compute unbiased gradient estimates with stochastic rounding (SR), resulting in more accurate model updates. However, directly applying SR to MXFP4 can result in high variance from block-level outliers, harming convergence. To overcome this, we use the random Hadamard tranform to theoretically bound the variance of SR. We train GPT models up to 6.7B parameters and find that our method induces minimal degradation over mixed-precision BF16 training. Our recipe computes 1/2 the training FLOPs in MXFP4, enabling an estimated speedup of 1.3× over FP8 and 1.7× over BF16 during backpropagation.
MXFP4를 통한 학습 연구가 나오기 시작하네요. (https://arxiv.org/abs/2502.20853) 학습용으로는 MXFP6도 관심이 높은 것 같습니다. 물론 지속적으로 MXFP4 학습에 도전한 사례가 나올 것 같지만요.
Research on training with MXFP4 is starting to emerge (https://arxiv.org/abs/2502.20853). For training purposes, MXFP6 is also gaining interest. However, we can expect to see continued attempts to tackle MXFP4 training.
#quantization #efficient-training
ByteScale: Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000 GPUs
(Hao Ge, Junda Feng, Qi Huang, Fangcheng Fu, Xiaonan Nie, Lei Zuo, Haibin Lin, Bin Cui, Xin Liu)
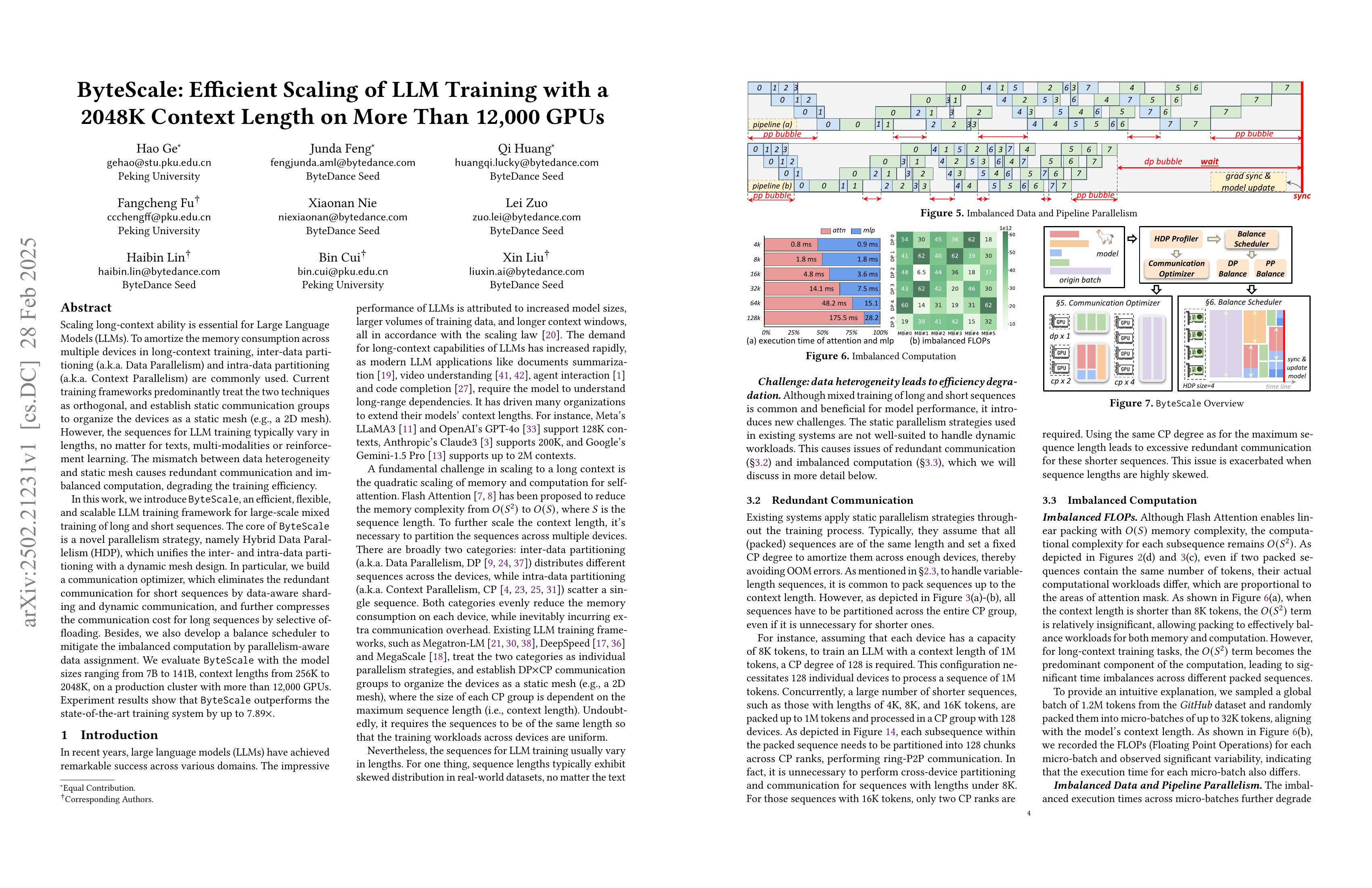
Scaling long-context ability is essential for Large Language Models (LLMs). To amortize the memory consumption across multiple devices in long-context training, inter-data partitioning (a.k.a. Data Parallelism) and intra-data partitioning (a.k.a. Context Parallelism) are commonly used. Current training frameworks predominantly treat the two techniques as orthogonal, and establish static communication groups to organize the devices as a static mesh (e.g., a 2D mesh). However, the sequences for LLM training typically vary in lengths, no matter for texts, multi-modalities or reinforcement learning. The mismatch between data heterogeneity and static mesh causes redundant communication and imbalanced computation, degrading the training efficiency. In this work, we introduce ByteScale, an efficient, flexible, and scalable LLM training framework for large-scale mixed training of long and short sequences. The core of ByteScale is a novel parallelism strategy, namely Hybrid Data Parallelism (HDP), which unifies the inter- and intra-data partitioning with a dynamic mesh design. In particular, we build a communication optimizer, which eliminates the redundant communication for short sequences by data-aware sharding and dynamic communication, and further compresses the communication cost for long sequences by selective offloading. Besides, we also develop a balance scheduler to mitigate the imbalanced computation by parallelism-aware data assignment. We evaluate ByteScale with the model sizes ranging from 7B to 141B, context lengths from 256K to 2048K, on a production cluster with more than 12,000 GPUs. Experiment results show that ByteScale outperforms the state-of-the-art training system by up to 7.89x.
짧은 시퀀스까지 Packing을 해서 긴 시퀀스와 같은 Context Parallel을 적용하는 대신 짧은 시퀀스에는 Data Parallel을 사용하고 긴 시퀀스에만 Context Parallel을 적용할 수 있다는 아이디어.
The main idea is to apply data parallelism to short sequences and context parallelism only to long sequences, instead of packing short sequences to apply the same context parallelism as used for long sequences.
#parallelism #efficiency
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
(Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, Noah D. Goodman)

Test-time inference has emerged as a powerful paradigm for enabling language models to “think” longer and more carefully about complex challenges, much like skilled human experts. While reinforcement learning (RL) can drive self-improvement in language models on verifiable tasks, some models exhibit substantial gains while others quickly plateau. For instance, we find that Qwen-2.5-3B far exceeds Llama-3.2-3B under identical RL training for the game of Countdown. This discrepancy raises a critical question: what intrinsic properties enable effective self-improvement? We introduce a framework to investigate this question by analyzing four key cognitive behaviors -- verification, backtracking, subgoal setting, and backward chaining -- that both expert human problem solvers and successful language models employ. Our study reveals that Qwen naturally exhibits these reasoning behaviors, whereas Llama initially lacks them. In systematic experimentation with controlled behavioral datasets, we find that priming Llama with examples containing these reasoning behaviors enables substantial improvements during RL, matching or exceeding Qwen's performance. Importantly, the presence of reasoning behaviors, rather than correctness of answers, proves to be the critical factor -- models primed with incorrect solutions containing proper reasoning patterns achieve comparable performance to those trained on correct solutions. Finally, leveraging continued pretraining with OpenWebMath data, filtered to amplify reasoning behaviors, enables the Llama model to match Qwen's self-improvement trajectory. Our findings establish a fundamental relationship between initial reasoning behaviors and the capacity for improvement, explaining why some language models effectively utilize additional computation while others plateau.
추론 RL이 Qwen 2.5에서는 작은 규모에서도 잘 되지만 (3B) Llama 3에서는 잘 되지 않는 이유에 대한 분석. 백트래킹과 같은 추론 관련 능력이 Llama 3에서는 잘 나타나지 않았다고 하네요. SFT나 프리트레이닝을 통해 이 패턴을 주입하면 Llama 3에서도 잘 되기 시작했다고. 아마 Qwen에서 사용된 합성 데이터의 영향이지 않을까 싶네요.
An analysis of why reasoning RL works well with Qwen 2.5 even at a small scale (3B) but not with Llama 3. The study found that reasoning-related abilities, such as backtracking, are not well-represented in Llama 3. However, when these patterns were introduced through SFT or pretraining, Llama 3 began to perform well. The synthetic data used in Qwen's pretraining may have contributed to this.
#reasoning #rl
PipeOffload: Improving Scalability of Pipeline Parallelism with Memory Optimization
(Xinyi Wan, Penghui Qi, Guangxing Huang, Jialin Li, Min Lin)

Pipeline parallelism (PP) is widely used for training large language models (LLMs), yet its scalability is often constrained by high activation memory consumption as the number of in-flight microbatches grows with the degree of PP. In this paper, we focus on addressing this challenge by leveraging the under-explored memory offload strategy in PP. With empirical study, we discover that in the majority of standard configurations, at least half, and potentially all, of the activations can be offloaded with negligible overhead. In the cases where full overload is not possible, we introduce a novel selective offload strategy that decreases peak activation memory in a better-than-linear manner. Furthermore, we integrate memory offload with other techniques to jointly consider overall throughput and memory limitation. Our experiments proves that the per-device activation memory effectively reduces with the total number of stages, making PP a stronger alternative than TP, offering up to a 19% acceleration with even lower memory consumption. The implementation is open-sourced at this url.
Pipeline Parallel과 Activation Offload 결합. GPU도 TPU도 CPU 메모리를 활용할 수 있는 방안을 지원하려고 하는 것 같더군요.
Combination of pipeline parallelism and activation offload. Recently both GPUs and TPUs seem to be trying to support a method to utilize CPU memory.
#parallelism #efficiency
SampleMix: A Sample-wise Pre-training Data Mixing Strategey by Coordinating Data Quality and Diversity
(Xiangyu Xi, Deyang Kong, Jian Yang, Jiawei Yang, Zhengyu Chen, Wei Wang, Jingang Wang, Xunliang Cai, Shikun Zhang, Wei Ye)

Existing pretraining data mixing methods for large language models (LLMs) typically follow a domain-wise methodology, a top-down process that first determines domain weights and then performs uniform data sampling across each domain. However, these approaches neglect significant inter-domain overlaps and commonalities, failing to control the global diversity of the constructed training dataset. Further, uniform sampling within domains ignores fine-grained sample-specific features, potentially leading to suboptimal data distribution. To address these shortcomings, we propose a novel sample-wise data mixture approach based on a bottom-up paradigm. This method performs global cross-domain sampling by systematically evaluating the quality and diversity of each sample, thereby dynamically determining the optimal domain distribution. Comprehensive experiments across multiple downstream tasks and perplexity assessments demonstrate that SampleMix surpasses existing domain-based methods. Meanwhile, SampleMix requires 1.4x to 2.1x training steps to achieves the baselines' performance, highlighting the substantial potential of SampleMix to optimize pre-training data.
LLM으로 측정한 문서 퀄리티에 클러스터링을 사용한 다양성을 고려한 샘플링 전략. 요즘 나오는 Deduplication 이후에 Duplication 횟수를 사용해 다시 가중치를 주는 시도와 비슷한 것 같네요.
A sampling strategy that combines document quality measured by LLMs with diversity achieved through clustering. This seems similar to recent attempts to reweight samples using the number of duplicates after deduplication.
#pretraining #corpus
Remasking Discrete Diffusion Models with Inference-Time Scaling
(Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, Volodymyr Kuleshov)

Part of the success of diffusion models stems from their ability to perform iterative refinement, i.e., repeatedly correcting outputs during generation. However, modern masked discrete diffusion lacks this capability: when a token is generated, it cannot be updated again, even when it introduces an error. Here, we address this limitation by introducing the remasking diffusion model (ReMDM) sampler, a method that can be applied to pretrained masked diffusion models in a principled way and that is derived from a discrete diffusion model with a custom remasking backward process. Most interestingly, ReMDM endows discrete diffusion with a form of inference-time compute scaling. By increasing the number of sampling steps, ReMDM generates natural language outputs that approach the quality of autoregressive models, whereas when the computation budget is limited, ReMDM better maintains quality. ReMDM also improves sample quality of masked diffusion models for discretized images, and in scientific domains such as molecule design, ReMDM facilitates diffusion guidance and pushes the Pareto frontier of controllability relative to classical masking and uniform noise diffusion. We provide the code along with a blog post on the project page:
https://remdm.github.io
.
요즘 Diffusion LM이 다시 등장하고 있네요. (https://www.inceptionlabs.ai/) Diffusion LM의 샘플링 과정에서 예측된 토큰을 다시 마스킹할 수는 없다는 문제를 해소하려 시도했습니다. LLaDA에서도 (https://arxiv.org/abs/2502.09992) Remasking 전략을 사용했었죠.
Diffusion LMs are making a comeback recently (https://www.inceptionlabs.ai/). This paper attempts to address a limitation of predicted tokens cannot be remasked during the sampling process. LLaDA (https://arxiv.org/abs/2502.09992) also employed a remasking strategy.
#diffusion #llm