



2025년 3월 21일

Bridging Continuous and Discrete Tokens for Autoregressive Visual Generation
(Yuqing Wang, Zhijie Lin, Yao Teng, Yuanzhi Zhu, Shuhuai Ren, Jiashi Feng, Xihui Liu)

Autoregressive visual generation models typically rely on tokenizers to compress images into tokens that can be predicted sequentially. A fundamental dilemma exists in token representation: discrete tokens enable straightforward modeling with standard cross-entropy loss, but suffer from information loss and tokenizer training instability; continuous tokens better preserve visual details, but require complex distribution modeling, complicating the generation pipeline. In this paper, we propose TokenBridge, which bridges this gap by maintaining the strong representation capacity of continuous tokens while preserving the modeling simplicity of discrete tokens. To achieve this, we decouple discretization from the tokenizer training process through post-training quantization that directly obtains discrete tokens from continuous representations. Specifically, we introduce a dimension-wise quantization strategy that independently discretizes each feature dimension, paired with a lightweight autoregressive prediction mechanism that efficiently model the resulting large token space. Extensive experiments show that our approach achieves reconstruction and generation quality on par with continuous methods while using standard categorical prediction. This work demonstrates that bridging discrete and continuous paradigms can effectively harness the strengths of both approaches, providing a promising direction for high-quality visual generation with simple autoregressive modeling. Project page: https://yuqingwang1029.github.io/TokenBridge.
VQ를 학습하는 대신 VAE를 학습하고 Feature를 Quantization해서 Discrete Token을 만드는 방법. 각 채널마다 각각 토큰이 할당되기 때문에 각 채널에 대해 Autoregressive 생성을 했습니다.
여담이지만 각 채널을 64개의 Vocabulary로 분할했는데 이건 실질적으로 VAE Feature가 각 채널 당 4bit 정도의 정보를 갖는다는 의미겠네요.
Instead of training a VQ model, this method trains a VAE and creates discrete tokens by quantizing the features. Since tokens are assigned to each channel, autoregressive generation was performed over each channels.
By the way they divided each channel into 64 vocabulary items, which means that essentially VAE features contain about 4 bits of information per channel.
#vq #quantization #tokenizer
Expert Race: A Flexible Routing Strategy for Scaling Diffusion Transformer with Mixture of Experts
(Yike Yuan, Ziyu Wang, Zihao Huang, Defa Zhu, Xun Zhou, Jingyi Yu, Qiyang Min)
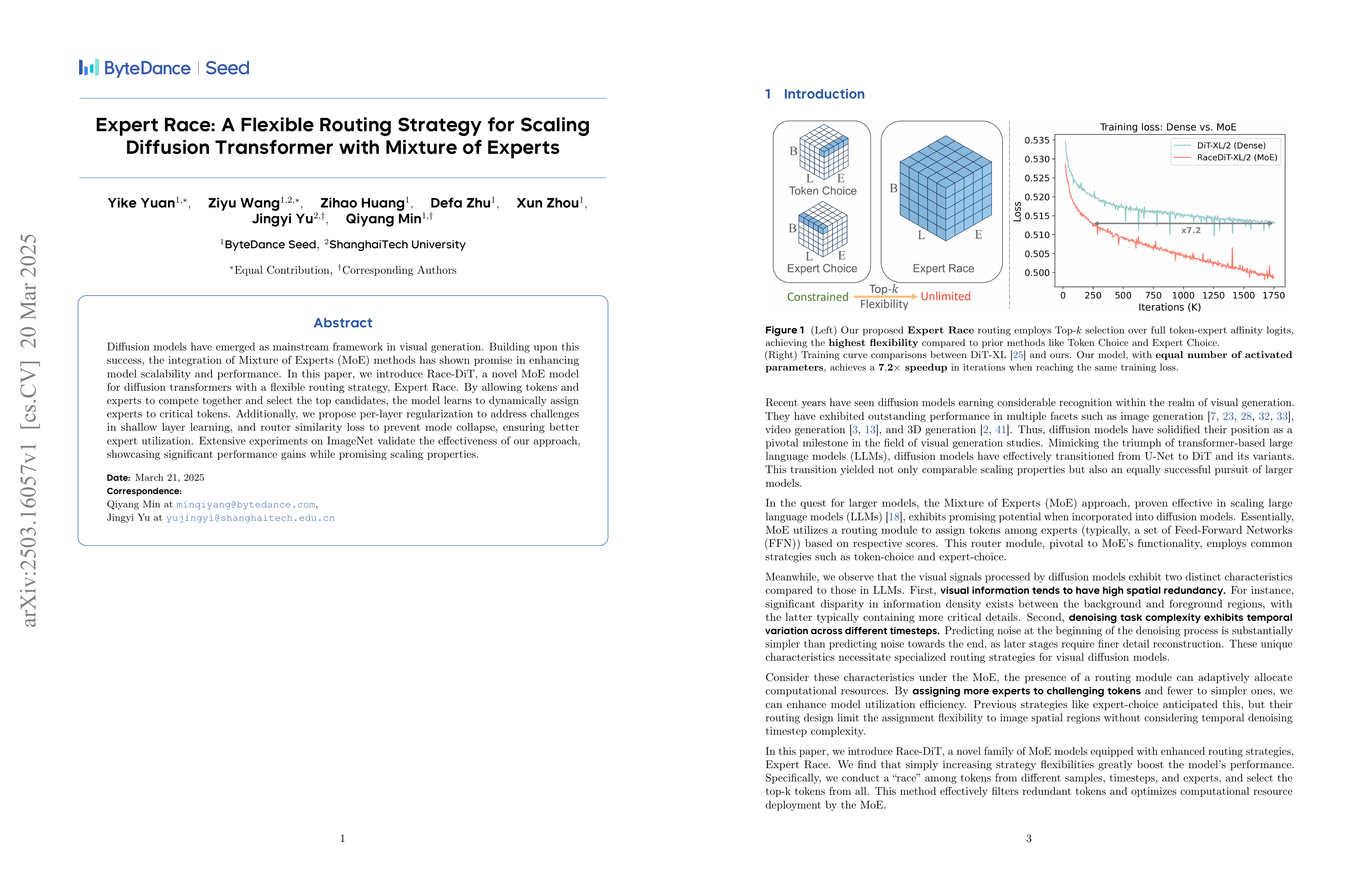
Diffusion models have emerged as mainstream framework in visual generation. Building upon this success, the integration of Mixture of Experts (MoE) methods has shown promise in enhancing model scalability and performance. In this paper, we introduce Race-DiT, a novel MoE model for diffusion transformers with a flexible routing strategy, Expert Race. By allowing tokens and experts to compete together and select the top candidates, the model learns to dynamically assign experts to critical tokens. Additionally, we propose per-layer regularization to address challenges in shallow layer learning, and router similarity loss to prevent mode collapse, ensuring better expert utilization. Extensive experiments on ImageNet validate the effectiveness of our approach, showcasing significant performance gains while promising scaling properties.
각 토큰 당 k개 Expert라는 제약을 풀고 배치 전체에 대해 Expert를 할당하는 방법이네요. 이런 방법은 학습과 추론 시점에 차이가 발생한다는 것이 문제이긴 하죠. (이쪽도 그에 대해 대응하려고 시도했습니다.) 그렇지만 동일한 k개 Expert 사용이라는 제약을 푸는 것은 흥미로운 방향이네요. 최적화가 더 까다로워지겠습니다만.
This method relaxes the constraint of assigning k experts per token by allocating experts across the entire batch. A common issue with such approaches is the discrepancy between training and inference (this paper also attempts to address this). However, I find the idea of lifting the restriction of using a uniform number of experts quite interesting. Although it would likely make optimization more challenging.
#moe
ATTENTION2D: Communication Efficient Distributed Self-Attention Mechanism
(Venmugil Elango)
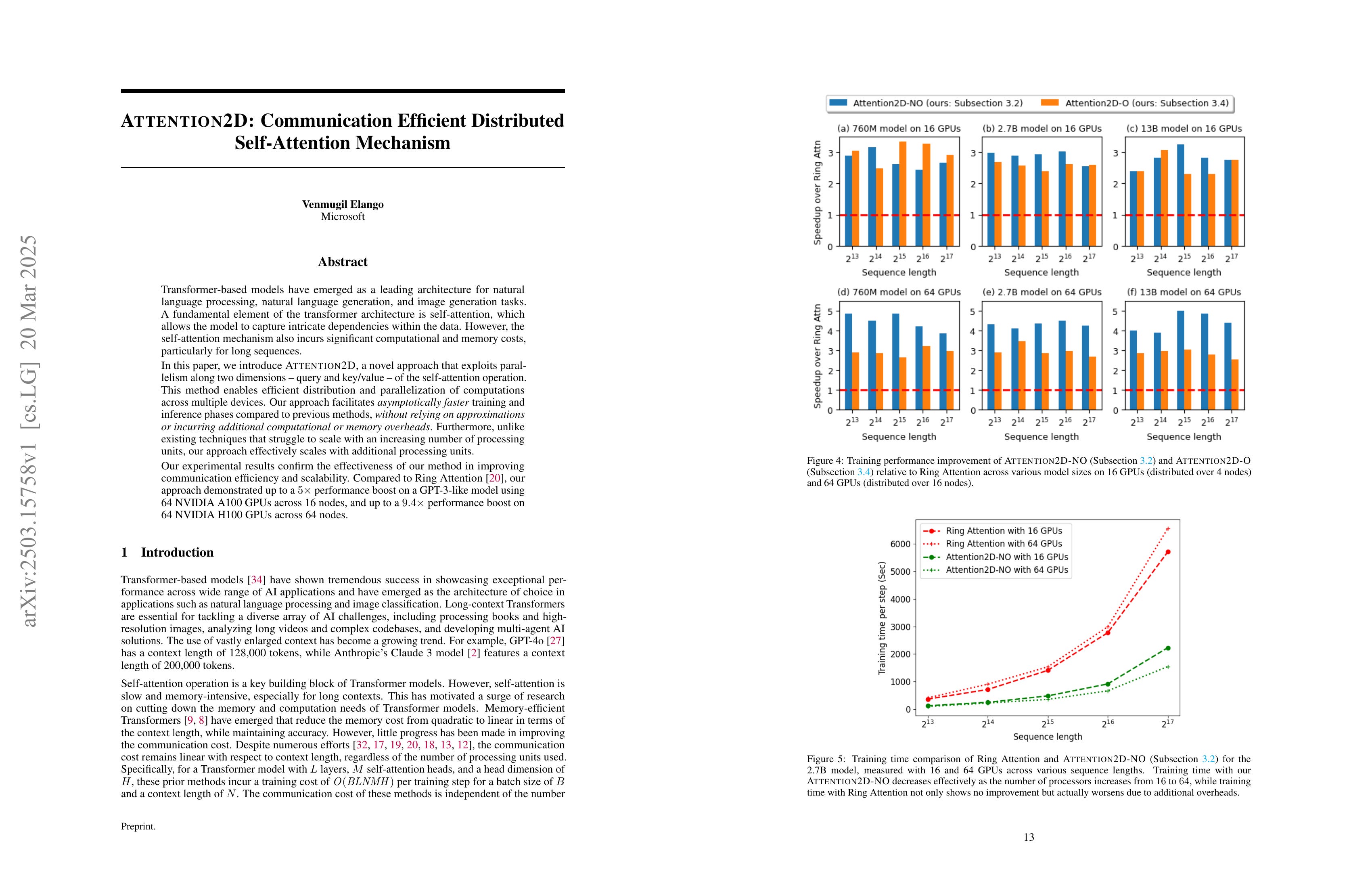
Transformer-based models have emerged as a leading architecture for natural language processing, natural language generation, and image generation tasks. A fundamental element of the transformer architecture is self-attention, which allows the model to capture intricate dependencies within the data. However, the self-attention mechanism also incurs significant computational and memory costs, particularly for long sequences. In this paper, we introduce ATTENTION2D, a novel approach that exploits parallelism along two dimensions - query and key/value - of the self-attention operation. This method enables efficient distribution and parallelization of computations across multiple devices. Our approach facilitates asymptotically faster training and inference phases compared to previous methods, without relying on approximations or incurring additional computational or memory overheads. Furthermore, unlike existing techniques that struggle to scale with an increasing number of processing units, our approach effectively scales with additional processing units. Our experimental results confirm the effectiveness of our method in improving communication efficiency and scalability. Compared to Ring Attention, our approach demonstrated up to a 5x performance boost on a GPT-3-like model using 64 NVIDIA A100 GPUs across 16 nodes, and up to a 9.4x performance boost on 64 NVIDIA H100 GPUs across 64 nodes.
Query 뿐만 아니라 Key-Value 축에 대해서도 병렬적으로 연산이 가능하도록 해서 분산 처리.
Distributed processing of attention by enabling parallelization along both the query and key-value axes.
#long-context #efficiency