



2025년 3월 12일

Inductive Moment Matching
(Linqi Zhou, Stefano Ermon, Jiaming Song)

Diffusion models and Flow Matching generate high-quality samples but are slow at inference, and distilling them into few-step models often leads to instability and extensive tuning. To resolve these trade-offs, we propose Inductive Moment Matching (IMM), a new class of generative models for one- or few-step sampling with a single-stage training procedure. Unlike distillation, IMM does not require pre-training initialization and optimization of two networks; and unlike Consistency Models, IMM guarantees distribution-level convergence and remains stable under various hyperparameters and standard model architectures. IMM surpasses diffusion models on ImageNet-256x256 with 1.99 FID using only 8 inference steps and achieves state-of-the-art 2-step FID of 1.98 on CIFAR-10 for a model trained from scratch.
1 or Few-step Single Stage 이미지 생성 모델. s < r < t 시점을 가정할 때 r 시점의 샘플에서 예측한 s 시점의 분포와 t 시점에서 예측한 분포를 MMD로 일치시키는 방법입니다. Consistency Model의 확장으로서 생각할 수 있을 것 같네요. 굉장히 흥미로운 결과입니다.
A single-stage image generation model capable of 1 or few-step sampling. Assuming time s < r < t, this method matches the distribution of time s generated from samples at time r with the distribution generated from time t using MMD. This can be considered an generalization of Consistency Models. The results are extremely intriguing.
#diffusion
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
(Yuxiao Qu, Matthew Y. R. Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhutdinov, Aviral Kumar)
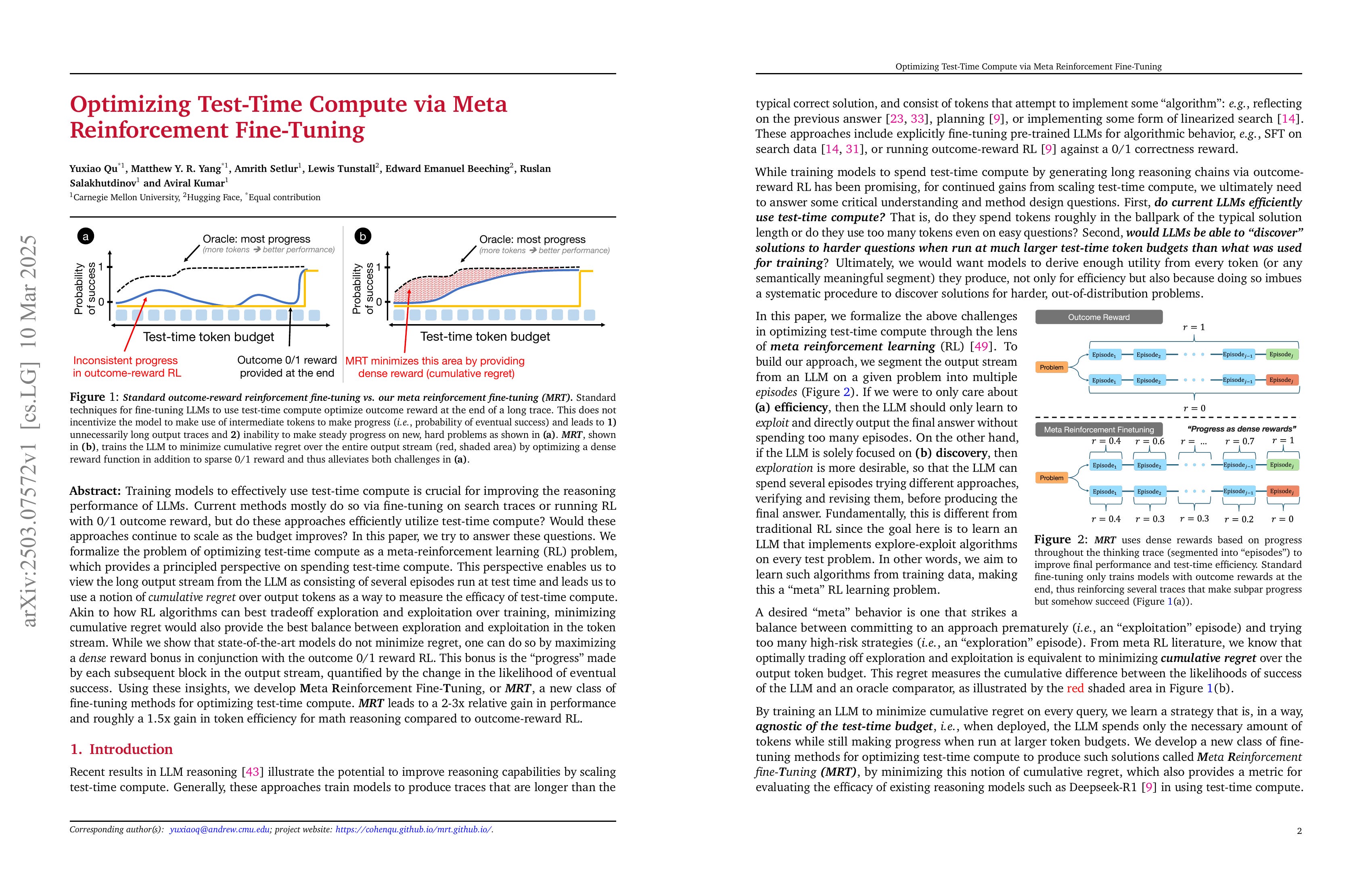
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ''progress'' made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.
Long CoT 모델의 생각의 단계들을 에피소드로 생각했을 때 에피소드들이 진행되는 것에 따라 정답 확률이 단조적으로 향상되지 않는다는 문제에 대한 지적. 이에 대해 에피소드들이 정답으로 진전되고 있는지를 보상으로 준다는 아이디어입니다.
Process Reward와 Outcome Reward는 계속해서 일종의 긴장 상태에 있네요.
This paper points out a problem with long CoT models of when considering each step of reasoning as an episode, the probability of reaching the correct answer does not increase monotonically as episodes progress. To address this, the authors propose the idea of rewarding episodes based on whether they are progressing towards the correct answer.
There are ongoing tension between process rewards and outcome rewards.
#rl #reasoning #reward
Hierarchical Balance Packing: Towards Efficient Supervised Fine-tuning for Long-Context LLM
(Yongqiang Yao, Jingru Tan, Kaihuan Liang, Feizhao Zhang, Yazhe Niu, Jiahao Hu, Ruihao Gong, Dahua Lin, Ningyi Xu)

Training Long-Context Large Language Models (LLMs) is challenging, as hybrid training with long-context and short-context data often leads to workload imbalances. Existing works mainly use data packing to alleviate this issue but fail to consider imbalanced attention computation and wasted communication overhead. This paper proposes Hierarchical Balance Packing (HBP), which designs a novel batch-construction method and training recipe to address those inefficiencies. In particular, the HBP constructs multi-level data packing groups, each optimized with a distinct packing length. It assigns training samples to their optimal groups and configures each group with the most effective settings, including sequential parallelism degree and gradient checkpointing configuration. To effectively utilize multi-level groups of data, we design a dynamic training pipeline specifically tailored to HBP, including curriculum learning, adaptive sequential parallelism, and stable loss. Our extensive experiments demonstrate that our method significantly reduces training time over multiple datasets and open-source models while maintaining strong performance. For the largest DeepSeek-V2 (236B) MOE model, our method speeds up the training by 2.4× with competitive performance.
Long Context 학습이 중요해지니 Packing 과정에서 굳이 짧은 시퀀스를 이어붙여서 Context Parallel이 필요하게 만들지 말자는 아이디어가 나오는군요. (https://arxiv.org/abs/2502.21231)
As long context training becomes increasingly important, an idea has emerged suggesting that we shouldn't artificially create the need for context parallelism by concatenating short sequences during the packing process (https://arxiv.org/abs/2502.21231).
#long-context #parallelism #efficiency
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
(Lixue Gong, Xiaoxia Hou, Fanshi Li, Liang Li, Xiaochen Lian, Fei Liu, Liyang Liu, Wei Liu, Wei Lu, Yichun Shi, Shiqi Sun, Yu Tian, Zhi Tian, Peng Wang, Xun Wang, Ye Wang, Guofeng Wu, Jie Wu, Xin Xia, Xuefeng Xiao, Linjie Yang, Zhonghua Zhai, Xinyu Zhang, Qi Zhang, Yuwei Zhang, Shijia Zhao, Jianchao Yang, Weilin Huang)

Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
바이트댄스의 이미지 생성 모델. 이미지 생성 모델도 대규모의 데이터 전처리 작업과 RLHF를 포함한 포스트트레이닝이 동반되기 시작하니 복잡도가 점점 더 높아지네요.
ByteDance's image generation model. As image generation models start to involve large-scale data preprocessing and post-training including RLHF, their overall complexity is growing significantly.
#image-generation #diffusion
Gemma 3 Technical Report
(Gemma Team, Google DeepMind)

We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context – at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma34B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 3가 나왔네요. Softcapping 대신 QK Norm을 썼군요. Window와 Global Attention의 조합에서 Window Attention의 비율을 5:1로 늘리면서 128K Context Length로 확장. 그리고 이미지 인식 능력을 탑재했습니다. 포스트트레이닝에는 구글이 그동안 공개했던 방법들의 종합에 (https://arxiv.org/abs/2407.14622, https://arxiv.org/abs/2401.12187, https://arxiv.org/abs/2406.16768) Verifiable Reward를 추가했군요.
Gemma 3 has been released. They've replaced softcapping with QK normalization. In the combination of window and global attention, they've increased the ratio of window attention to 5:1, extending the context length to 128K. They've also incorporated image recognition capabilities. For post-training, they've used a combination of methods that Google has previously published (https://arxiv.org/abs/2407.14622, https://arxiv.org/abs/2401.12187, https://arxiv.org/abs/2406.16768) and added verifiable rewards.
#llm #vision-language