



2025년 2월 27일

DualPipe
(Jiashi Li, Chengqi Deng, Wenfeng Liang)
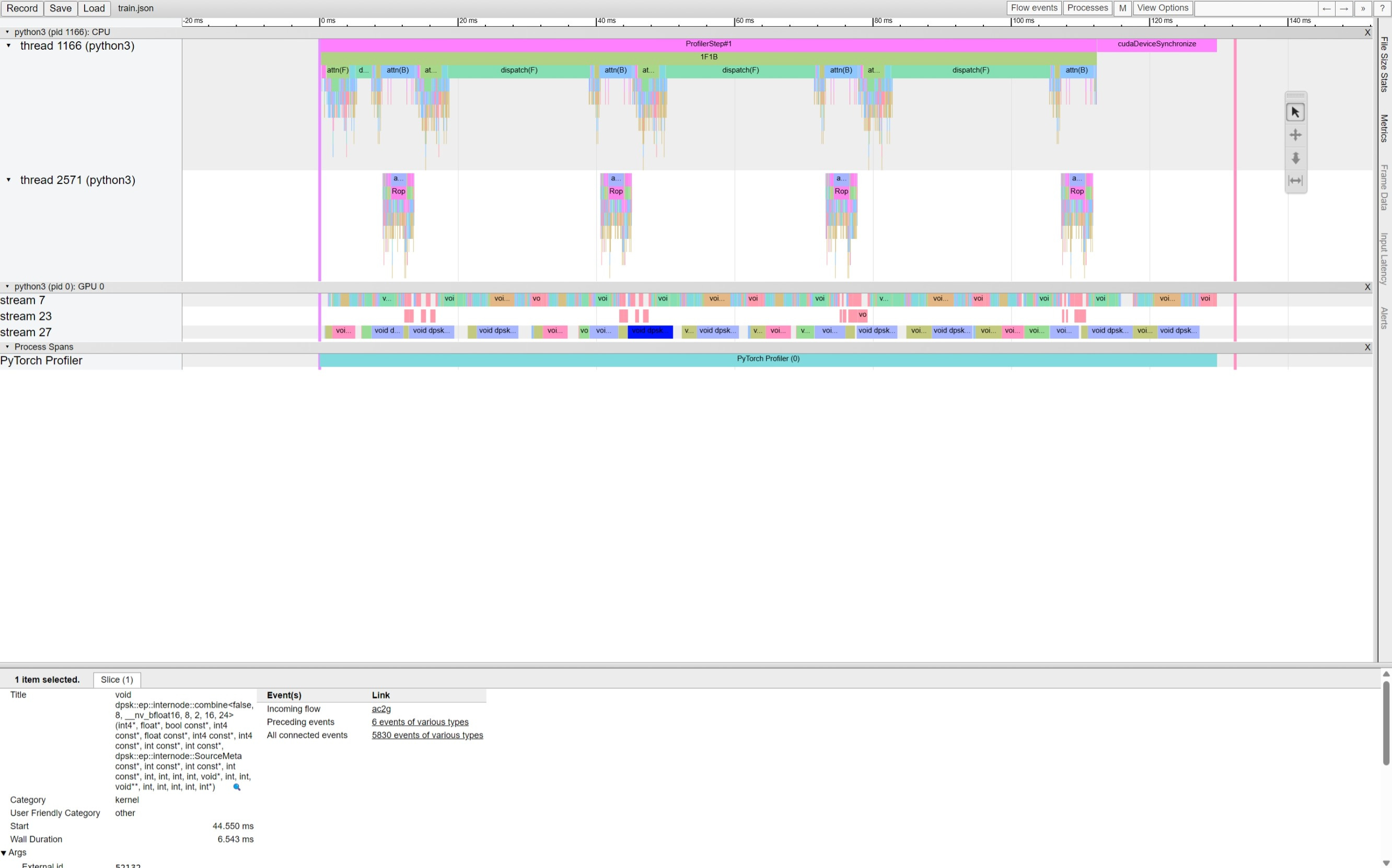
DeepSeek이 오늘은 DualPipe를 공개했네요. Megatron 등에 대한 의존성 없는 깨끗한 상태의 코드입니다. 여기에 배포를 위한 Expert Parallel Load Balancer와 학습과 추론 시점에 대한 프로파일링 결과도 공개했네요. (https://github.com/deepseek-ai/EPLB, https://github.com/deepseek-ai/profile-data)
대체 마지막 날엔 어떤 걸 공개할지 궁금해집니다.
Today, DeepSeek released DualPipe. It's a clean codebase without dependencies on Megatron. They also released an expert parallel load balancer for deployment and profiling results for both training and inference. (https://github.com/deepseek-ai/EPLB, https://github.com/deepseek-ai/profile-data)
I'm curious to see what they'll release on the final day.
#parallelism #efficiency
(Mis)Fitting: A Survey of Scaling Laws
(Margaret Li, Sneha Kudugunta, Luke Zettlemoyer)

Modern foundation models rely heavily on using scaling laws to guide crucial training decisions. Researchers often extrapolate the optimal architecture and hyper parameters settings from smaller training runs by describing the relationship between, loss, or task performance, and scale. All components of this process vary, from the specific equation being fit, to the training setup, to the optimization method. Each of these factors may affect the fitted law, and therefore, the conclusions of a given study. We discuss discrepancies in the conclusions that several prior works reach, on questions such as the optimal token to parameter ratio. We augment this discussion with our own analysis of the critical impact that changes in specific details may effect in a scaling study, and the resulting altered conclusions. Additionally, we survey over 50 papers that study scaling trends: while 45 of these papers quantify these trends using a power law, most under-report crucial details needed to reproduce their findings. To mitigate this, we we propose a checklist for authors to consider while contributing to scaling law research.
기존 Scaling Law 연구들에 대한 분석과 실험 결과. 주로 Chinchilla의 Parameteric Loss를 다룹니다. 결론적으로는 제대로 하기 어렵다는 이야기를 합니다.
여기서 제안하는 것 중에 파라미터의 수에 주의하라는 것이 중요한 포인트라고 생각합니다. 요즘 Scaling Law들은 상당히 많은 파라미터를 추정하는 경우가 있죠. 그러나 파라미터 다섯 개면 코끼리가 코를 흔들게 할 수 있다는 걸 기억해야 합니다.
This paper analyzes previous scaling law research and presents experimental results, primarily focusing on the parametric loss introduced by Chinchilla. The conclusion suggests that accurate estimation is challenging.
Among the points raised, I believe the emphasis on being cautious about the number of parameters in scaling laws is particularly important. Recent scaling studies often incorporate and estimate numerous parameters. However, we should always remember that we can wiggle the trunk of elephant with five parameters.
#scaling-law
BIG-Bench Extra Hard
(Mehran Kazemi, Bahare Fatemi, Hritik Bansal, John Palowitch, Chrysovalantis Anastasiou, Sanket Vaibhav Mehta, Lalit K. Jain, Virginia Aglietti, Disha Jindal, Peter Chen, Nishanth Dikkala, Gladys Tyen, Xin Liu, Uri Shalit, Silvia Chiappa, Kate Olszewska, Yi Tay, Vinh Q. Tran, Quoc V. Le, Orhan Firat)

Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8% for the best general-purpose model and 44.8% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
Big-Bench Hard의 23개 과제를 더 어려운 과제로 교체한 벤치마크. 살벌한 점수가 나오네요.
A benchmark that replaces the 23 tasks from Big-Bench Hard with more challenging ones. The resulting scores are brutal.
#benchmark
DataMan: Data Manager for Pre-training Large Language Models
(Ru Peng, Kexin Yang, Yawen Zeng, Junyang Lin, Dayiheng Liu, Junbo Zhao)

The performance emergence of large language models (LLMs) driven by data scaling laws makes the selection of pre-training data increasingly important. However, existing methods rely on limited heuristics and human intuition, lacking comprehensive and clear guidelines. To address this, we are inspired by ``reverse thinking'' -- prompting LLMs to self-identify which criteria benefit its performance. As its pre-training capabilities are related to perplexity (PPL), we derive 14 quality criteria from the causes of text perplexity anomalies and introduce 15 common application domains to support domain mixing. In this paper, we train a Data Manager (DataMan) to learn quality ratings and domain recognition from pointwise rating, and use it to annotate a 447B token pre-training corpus with 14 quality ratings and domain type. Our experiments validate our approach, using DataMan to select 30B tokens to train a 1.3B-parameter language model, demonstrating significant improvements in in-context learning (ICL), perplexity, and instruction-following ability over the state-of-the-art baseline. The best-performing model, based on the Overall Score l=5 surpasses a model trained with 50% more data using uniform sampling. We continue pre-training with high-rated, domain-specific data annotated by DataMan to enhance domain-specific ICL performance and thus verify DataMan's domain mixing ability. Our findings emphasize the importance of quality ranking, the complementary nature of quality criteria, and their low correlation with perplexity, analyzing misalignment between PPL and ICL performance. We also thoroughly analyzed our pre-training dataset, examining its composition, the distribution of quality ratings, and the original document sources.
LLM을 사용한 퀄리티 필터링. Perplexity가 높거나 낮은 샘플들을 가져와 LLM에게 왜 그런지를 묻는 방식으로 14개의 기준을 정하고 15개의 도메인을 구분했네요.
Quality filtering using LLMs. They established 14 criteria and identified 15 domains by selecting samples with high or low perplexity and asking LLMs to explain the reasons behind these perplexity scores.
#dataset #pretraining
Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation
(Shiven Sinha, Shashwat Goel, Ponnurangam Kumaraguru, Jonas Geiping, Matthias Bethge, Ameya Prabhu)

There is growing excitement about the potential of Language Models (LMs) to accelerate scientific discovery. Falsifying hypotheses is key to scientific progress, as it allows claims to be iteratively refined over time. This process requires significant researcher effort, reasoning, and ingenuity. Yet current benchmarks for LMs predominantly assess their ability to generate solutions rather than challenge them. We advocate for developing benchmarks that evaluate this inverse capability - creating counterexamples for subtly incorrect solutions. To demonstrate this approach, we start with the domain of algorithmic problem solving, where counterexamples can be evaluated automatically using code execution. Specifically, we introduce REFUTE, a dynamically updating benchmark that includes recent problems and incorrect submissions from programming competitions, where human experts successfully identified counterexamples. Our analysis finds that the best reasoning agents, even OpenAI o3-mini (high) with code execution feedback, can create counterexamples for only <9% of incorrect solutions in REFUTE, even though ratings indicate its ability to solve up to 48% of these problems from scratch. We hope our work spurs progress in evaluating and enhancing LMs' ability to falsify incorrect solutions - a capability that is crucial for both accelerating research and making models self-improve through reliable reflective reasoning.
문제와 오류가 있는 코드를 주고 모델이 코드가 작동하지 않는 반례를 찾아낼 수 있는가를 평가하는 벤치마크. 역설적이지만 문제를 풀 수 있는 문제에 대해서도 반례를 찾지는 못하는군요.
A benchmark that evaluates whether a model can find counterexamples that demonstrate why incorrect code doesn't work when given problems and incorrect code. Ironically, the models can't find counterexamples even for problems they are capable of solving from scratch.
#benchmark #reasoning
Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization
(Taishi Nakamura, Takuya Akiba, Kazuki Fujii, Yusuke Oda, Rio Yokota, Jun Suzuki)

The Mixture of Experts (MoE) architecture reduces the training and inference cost significantly compared to a dense model of equivalent capacity. Upcycling is an approach that initializes and trains an MoE model using a pre-trained dense model. While upcycling leads to initial performance gains, the training progresses slower than when trained from scratch, leading to suboptimal performance in the long term. We propose Drop-Upcycling - a method that effectively addresses this problem. Drop-Upcycling combines two seemingly contradictory approaches: utilizing the knowledge of pre-trained dense models while statistically re-initializing some parts of the weights. This approach strategically promotes expert specialization, significantly enhancing the MoE model's efficiency in knowledge acquisition. Extensive large-scale experiments demonstrate that Drop-Upcycling significantly outperforms previous MoE construction methods in the long term, specifically when training on hundreds of billions of tokens or more. As a result, our MoE model with 5.9B active parameters achieves comparable performance to a 13B dense model in the same model family, while requiring approximately 1/4 of the training FLOPs. All experimental resources, including source code, training data, model checkpoints and logs, are publicly available to promote reproducibility and future research on MoE.
Sparse Upcycling에서 FFN을 그대로 복제하는 대신 Perturbation을 줘서 다양성을 높인 방법. From Scratch 학습에 비교해서 성능 향상이 감소한다는 결과에서 생각할 수 있는 방향이죠. 물론 성능 역전이 발생하는 지점을 옮기는 정도일 수도 있겠습니다만.
This method enhances sparse upcycling by perturbing experts to diversify it instead of directly replicating. It's an approach that we can consider when we observe diminishing returns in upcycling compared to training from scratch. Of course, it might just be shifting the point where loss curves intersect.
#moe
Reward Shaping to Mitigate Reward Hacking in RLHF
(Jiayi Fu, Xuandong Zhao, Chengyuan Yao, Heng Wang, Qi Han, Yanghua Xiao)

Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. However, RLHF is susceptible to reward hacking, where the agent exploits flaws in the reward function rather than learning the intended behavior, thus degrading alignment. While reward shaping helps stabilize RLHF and partially mitigate reward hacking, a systematic investigation into shaping techniques and their underlying principles remains lacking. To bridge this gap, we present a comprehensive study of the prevalent reward shaping methods. Our analysis suggests three key design principles: (1) RL reward is ideally bounded, (2) RL benefits from rapid initial growth followed by gradual convergence, and (3) RL reward is best formulated as a function of centered reward. Guided by these insights, we propose Preference As Reward (PAR), a novel approach that leverages the latent preferences embedded within the reward model itself as the signal for reinforcement learning. We evaluated PAR on two base models, Gemma2-2B and Llama3-8B, using two datasets, Ultrafeedback-Binarized and HH-RLHF. Experimental results demonstrate PAR's superior performance over other reward shaping methods. On the AlpacaEval 2.0 benchmark, PAR achieves a win rate at least 5 percentage points higher than competing approaches. Furthermore, PAR exhibits remarkable data efficiency, requiring only a single reference reward for optimal performance, and maintains robustness against reward hacking even after two full epochs of training. Code is available at https://github.com/PorUna-byte/PAR.
Bradley-Terry 모델에 따른 Preference Score를 Reward로 쓰자는 아이디어.
The idea of using the preference score from the bradley-terry model as a reward.
#reward-model #alignment
The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
(Jinbo Wang, Mingze Wang, Zhanpeng Zhou, Junchi Yan, Weinan E, Lei Wu)

Transformers consist of diverse building blocks, such as embedding layers, normalization layers, self-attention mechanisms, and point-wise feedforward networks. Thus, understanding the differences and interactions among these blocks is important. In this paper, we uncover a clear Sharpness Disparity across these blocks, which emerges early in training and intriguingly persists throughout the training process. Motivated by this finding, we propose Blockwise Learning Rate (LR), a strategy that tailors the LR to each block's sharpness, accelerating large language model (LLM) pre-training. By integrating Blockwise LR into AdamW, we consistently achieve lower terminal loss and nearly 2× speedup compared to vanilla AdamW. We demonstrate this acceleration across GPT-2 and LLaMA, with model sizes ranging from 0.12B to 1.1B and datasets of OpenWebText and MiniPile. Finally, we incorporate Blockwise LR into Adam-mini (Zhang et al., 2024), a recently proposed memory-efficient variant of Adam, achieving a combined 2× speedup and 2× memory saving. These results underscore the potential of exploiting the sharpness disparity to improve LLM training.
그래디언트의 제곱합의 규모가 블럭마다 다르다는 분석을 기반으로 각 블럭의 LR을 조정해본 시도네요.
This research is an attempt to adjust the LR for each block based on the analysis that the scale of the squared sum of gradients differs across type of blocks.
#optimizer #transformer