



2025년 2월 21일

Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
(Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, Heung-Yeung Shum)

We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity and accessibility. Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE (𝜆 = 1, 𝛾 = 1) and straightforward rule-based reward function, without any KL regularization, is sufficient to scale up both response length and benchmark performance on reasoning tasks, similar to the phenomenon observed in DeepSeek-R1-Zero. Notably, our implementation outperforms DeepSeek-R1-Zero-Qwen-32B on the GPQA Diamond benchmark, while only requiring 1/30 of the training steps. In the spirit of open source, we release our source code, parameter settings, training data, and model weights.
StepFun에서 RL CoT 실험 결과를 공개했군요. KL Penalty 없는 바닐라 PPO 사용.
StepFun has released their experimental results on RL CoT. They employed vanilla PPO without using a KL penalty.
#reasoning #rl
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
(M-A-P Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, Kang Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixing Deng, Shuyue Guo, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, Sirun Li, Yizhi Li, Yunwen Li, Dehua Ma, Yuansheng Ni, Haoran Que, Qiyao Wang, Zhoufutu Wen, Siwei Wu, Tianshun Xing, Ming Xu, Zhenzhu Yang, Zekun Moore Wang, Junting Zhou, Yuelin Bai, Xingyuan Bu, Chenglin Cai, Liang Chen, Yifan Chen, Chengtuo Cheng, Tianhao Cheng, Keyi Ding, Siming Huang, Yun Huang, Yaoru Li, Yizhe Li, Zhaoqun Li, Tianhao Liang, Chengdong Lin, Hongquan Lin, Yinghao Ma, Zhongyuan Peng, Zifan Peng, Qige Qi, Shi Qiu, Xingwei Qu, Yizhou Tan, Zili Wang, Chenqing Wang, Hao Wang, Yiya Wang, Yubo Wang, Jiajun Xu, Kexin Yang, Ruibin Yuan, Yuanhao Yue, Tianyang Zhan, Chun Zhang, Jingyang Zhang, Xiyue Zhang, Xingjian Zhang, Yue Zhang, Yongchi Zhao, Xiangyu Zheng, Chenghua Zhong, Yang Gao, Zhoujun Li, Dayiheng Liu, Qian Liu, Tianyu Liu, Shiwen Ni, Junran Peng, Yujia Qin, Wenbo Su, Guoyin Wang, Shi Wang, Jian Yang, Min Yang, Meng Cao, Xiang Yue, Zhaoxiang Zhang, Wangchunshu Zhou, Jiaheng Liu, Qunshu Lin, Wenhao Huang, Ge Zhang)
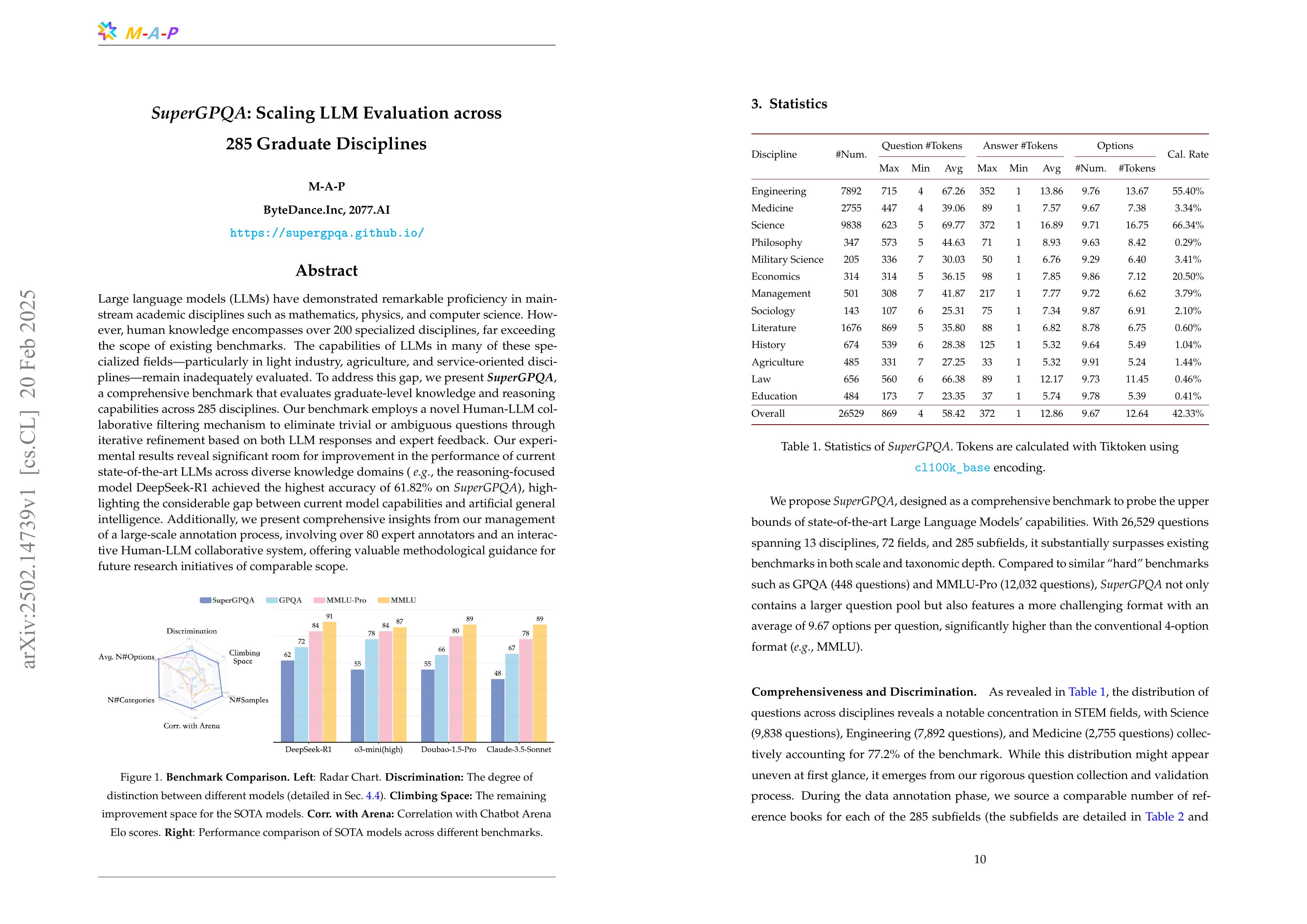
Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
GPQA의 확장판 형태의 벤치마크군요. 더 많은 문제, 더 다양한 도메인, 그리고 더 많은 선택지네요.
New benchmark that can be considered as an expanded version of GPQA. It features more questions, covers more diverse domains, and includes more answer choices per question.
#benchmark
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
(Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, Chong Luo)
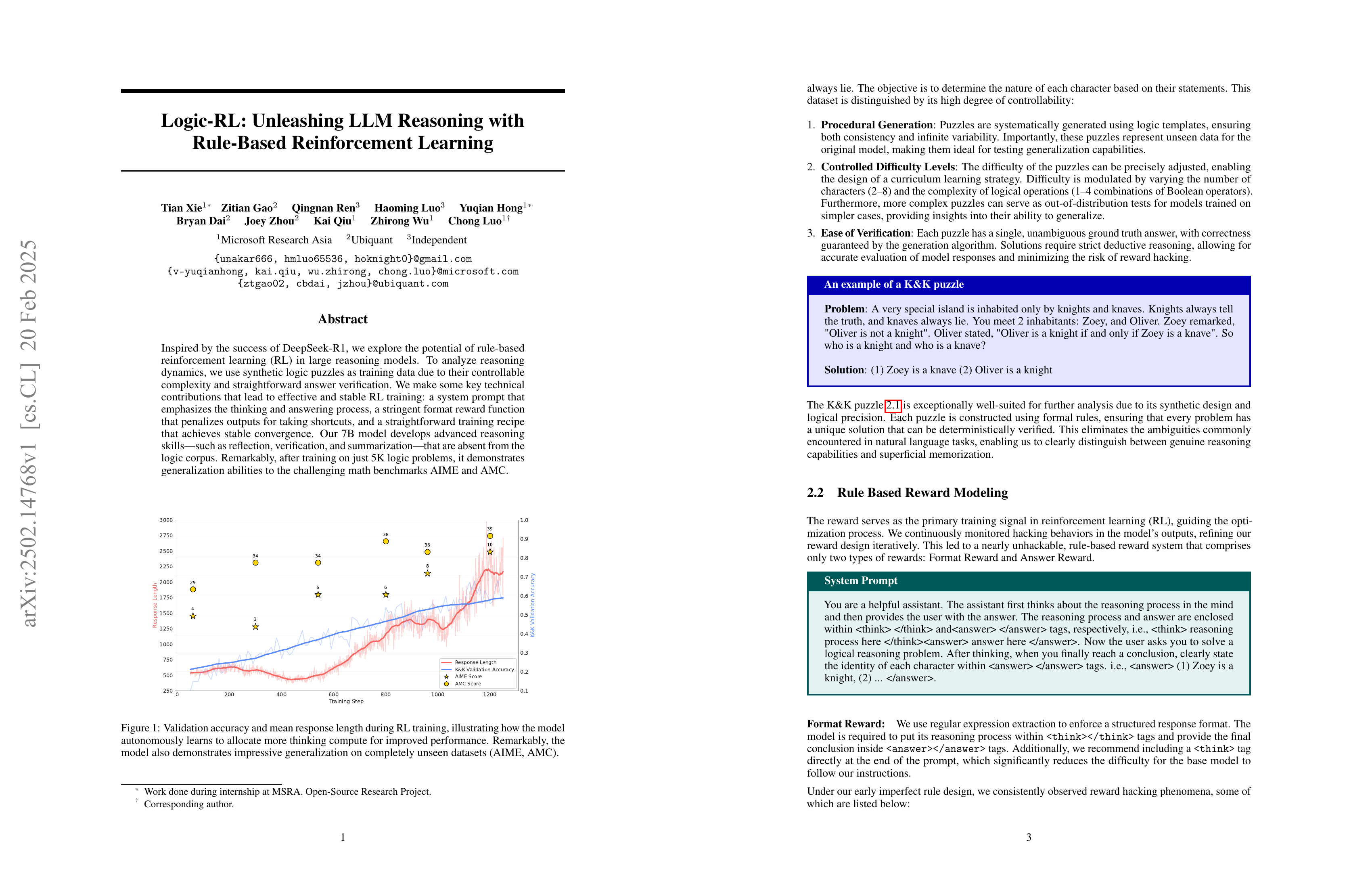
Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in large reasoning models. To analyze reasoning dynamics, we use synthetic logic puzzles as training data due to their controllable complexity and straightforward answer verification. We make some key technical contributions that lead to effective and stable RL training: a system prompt that emphasizes the thinking and answering process, a stringent format reward function that penalizes outputs for taking shortcuts, and a straightforward training recipe that achieves stable convergence. Our 7B model develops advanced reasoning skills-such as reflection, verification, and summarization-that are absent from the logic corpus. Remarkably, after training on just 5K logic problems, it demonstrates generalization abilities to the challenging math benchmarks AIME and AMC.
논리 퍼즐로 추론 RL을 학습시킨 결과가 나왔네요. 데이터는 전형적인 거짓말을 찾는 문제입니다. RL에서 일반화가 두드러진다는 것과 논리 퍼즐에 대해 학습시켰을 때 수학 문제에 대한 성능도 높아진다는 것을 발견했네요.
The results of training a reasoning model using RL on logic puzzles have been released. The data consists of typical "liar detection" problems (Knights and Knaves). They discovered that generalization is more pronounced in RL, and that training on logic puzzles also improves performance on mathematical problems.
#reasoning #rl
Improving the Diffusability of Autoencoders
(Ivan Skorokhodov, Sharath Girish, Benran Hu, Willi Menapace, Yanyu Li, Rameen Abdal, Sergey Tulyakov, Aliaksandr Siarohin)

Latent diffusion models have emerged as the leading approach for generating high-quality images and videos, utilizing compressed latent representations to reduce the computational burden of the diffusion process. While recent advancements have primarily focused on scaling diffusion backbones and improving autoencoder reconstruction quality, the interaction between these components has received comparatively less attention. In this work, we perform a spectral analysis of modern autoencoders and identify inordinate high-frequency components in their latent spaces, which are especially pronounced in the autoencoders with a large bottleneck channel size. We hypothesize that this high-frequency component interferes with the coarse-to-fine nature of the diffusion synthesis process and hinders the generation quality. To mitigate the issue, we propose scale equivariance: a simple regularization strategy that aligns latent and RGB spaces across frequencies by enforcing scale equivariance in the decoder. It requires minimal code changes and only up to 20K autoencoder fine-tuning steps, yet significantly improves generation quality, reducing FID by 19% for image generation on ImageNet-1K 256x256 and FVD by at least 44% for video generation on Kinetics-700 17x256x256.
VAE 토크나이저의 Latent에 고주파수 성분이 많이 포함되어 있고 이것이 Diffusion 학습에 문제가 될 수 있다는 분석. GAN 시절의 분석들이 생각나는군요. (https://arxiv.org/abs/2106.12423)
An analysis shows that VAE tokenizers' latent spaces contain a relatively large amount of high-frequency components, which can potentially hinder diffusion training. This reminds me of analyses from the GAN era. (https://arxiv.org/abs/2106.12423)
#diffusion #tokenizer
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
(Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, Xiaohua Zhai)

We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
SigLIP에 추가적으로 Autoregressive 디코더를 사용한 (그라운딩 등을 포함한) 캡션 생성, 그리고 이미지에 대한 Self Supervision을 사용했네요. 그리고 가변 크기 이미지 지원을 추가했군요.
SigLIP 2 which includes additional losses of caption generation (including grounding) using an autoregressive decoder, self-supervision for images, and support for variable-sized image inputs.
#clip #self-supervision