



2025년 2월 20일

The Ultra-Scale Playbook: Training LLMs on GPU Clusters
(Nouamane Tazi, Ferdinand Mom, Haojun Zhao, Phuc Nguyen, Mohamed Mekkouri, Leandro Werra, Thomas Wolf)
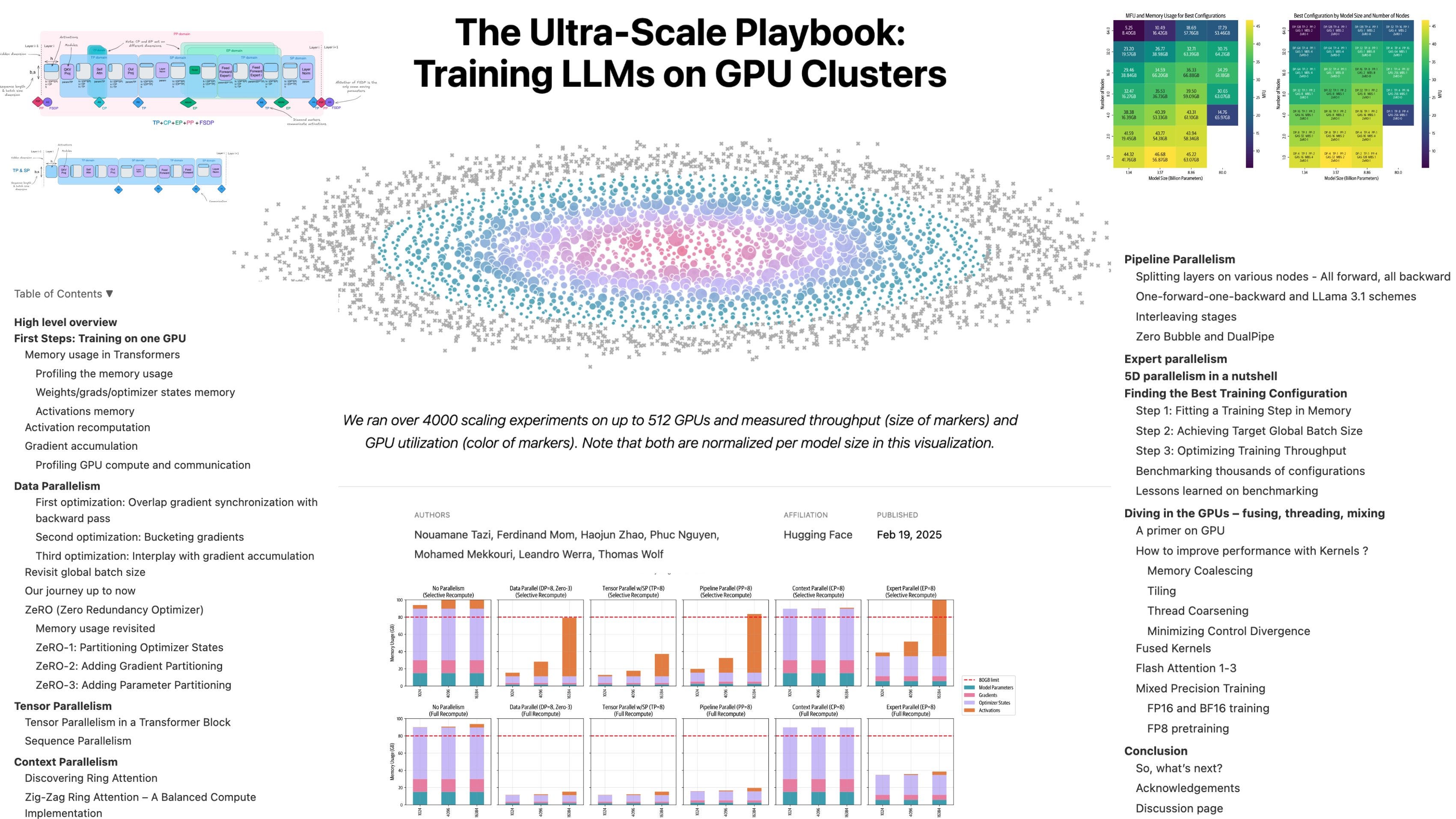
구글의 Scaling Book에 이어 HuggingFace에서도 Distributed Training과 관련된 자료를 만들었군요. (https://jax-ml.github.io/scaling-book/) Scaling Book도 좋은 자료이고 Computation-Communication Overlap에 대해 좀 더 깊게 다루고 있긴 한데 아무래도 (Pipeline Parallel에는 크게 관심이 없는 등) TPU를 위주로 설명하긴 했죠. 그 부분에서는 보완이 되겠군요.
https://uvadlc-notebooks.readthedocs.io/en/latest/index.html https://github.com/rwitten/HighPerfLLMs2024
이와 관련해서는 몇 가지 참조할만한 자료들이 더 있습니다.
Following Google's Scaling Book, HuggingFace has also created an article related to distributed training (https://jax-ml.github.io/scaling-book/). While the Scaling Book is a valuable resource and dives deeper into computation-communication overlap, it primarily focuses on TPUs (and shows little interest in pipeline parallelism). This new article may complement those areas.
https://uvadlc-notebooks.readthedocs.io/en/latest/index.html https://github.com/rwitten/HighPerfLLMs2024
There are several other reference materials related to this topic.
#distributed-training
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
(Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, Oğuzhan Fatih Kar, Elmira Amirloo, Alaaeldin El-Nouby, Amir Zamir, Afshin Dehghan)

Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid redundancies. However, these methods typically use a fixed number of tokens and thus cannot adapt to an image's inherent complexity. We introduce FlexTok, a tokenizer that projects 2D images into variable-length, ordered 1D token sequences. For example, a 256x256 image can be resampled into anywhere from 1 to 256 discrete tokens, hierarchically and semantically compressing its information. By training a rectified flow model as the decoder and using nested dropout, FlexTok produces plausible reconstructions regardless of the chosen token sequence length. We evaluate our approach in an autoregressive generation setting using a simple GPT-style Transformer. On ImageNet, this approach achieves an FID<2 across 8 to 128 tokens, outperforming TiTok and matching state-of-the-art methods with far fewer tokens. We further extend the model to support to text-conditioned image generation and examine how FlexTok relates to traditional 2D tokenization. A key finding is that FlexTok enables next-token prediction to describe images in a coarse-to-fine "visual vocabulary", and that the number of tokens to generate depends on the complexity of the generation task.
가변 길이 Semantic Tokenizer가 나왔네요. (https://arxiv.org/abs/2501.10064) 토크나이저의 디코더로는 Rectified Flow를 사용했군요.
개인적으로 Semantic Tokenizer는 Token Pruning이나 Resampling과 비슷한 접근이라는 생각이 있습니다. 고해상도 이미지로 넘어갔을 때, 그리고 인식에서도 Scalable한 방법일지 궁금하긴 하네요.
A variable-length semantic tokenizer (https://arxiv.org/abs/2501.10064). They used rectified flow as the decoder for the tokenizer.
I suspect semantic tokenizer is similar kind of idea to token pruning or resampling. I'm curious about how scalable this method would be for high resolution images and in image recognitions.
#vq #diffusion #autoregressive-model
Qwen2.5-VL Technical Report
(Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, Junyang Lin)

We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Qwen2.5-VL 리포트. 모델 자체는 공개된지 한참 되긴 했죠. 이번에는 리포트에서 사용한 데이터에 대해 평소보다 자세하다는 느낌이네요.
Technical report on Qwen2.5-VL. While the model itself was released quite a while ago, this report seems to provide more detailed information about the data they used than usual.
#vision-language #pretraining
Craw4LLM: Efficient Web Crawling for LLM Pretraining
(Shi Yu, Zhiyuan Liu, Chenyan Xiong)

Web crawl is a main source of large language models' (LLMs) pretraining data, but the majority of crawled web pages are discarded in pretraining due to low data quality. This paper presents Crawl4LLM, an efficient web crawling method that explores the web graph based on the preference of LLM pretraining. Specifically, it leverages the influence of a webpage in LLM pretraining as the priority score of the web crawler's scheduler, replacing the standard graph connectivity based priority. Our experiments on a web graph containing 900 million webpages from a commercial search engine's index demonstrate the efficiency of Crawl4LLM in obtaining high-quality pretraining data. With just 21% URLs crawled, LLMs pretrained on Crawl4LLM data reach the same downstream performances of previous crawls, significantly reducing the crawling waste and alleviating the burdens on websites. Our code is publicly available at https://github.com/cxcscmu/Crawl4LLM.
프리트레이닝 데이터 구축을 위한 웹 크롤러에서 크롤링 우선 순위를 문서 퀄리티 필터로 한다는 아이디어군요. 자체 크롤러까지 구축하는 쪽에서는 이런 고민도 있을지 모르겠네요.
This paper presents an idea of using document quality filters to set crawling priorities when building a web crawler for constructing pretraining corpora. Organizations that develop their own internal crawlers might encounter these kinds of considerations.
#dataset #corpus
TESS 2: A Large-Scale Generalist Diffusion Language Model
(Jaesung Tae, Hamish Ivison, Sachin Kumar, Arman Cohan)

We introduce TESS 2, a general instruction-following diffusion language model that outperforms contemporary instruction-tuned diffusion models, as well as matches and sometimes exceeds strong autoregressive (AR) models. We train TESS 2 by first adapting a strong AR model via continued pretraining with the usual cross-entropy as diffusion loss, and then performing further instruction tuning. We find that adaptation training as well as the choice of the base model is crucial for training good instruction-following diffusion models. We further propose reward guidance, a novel and modular inference-time guidance procedure to align model outputs without needing to train the underlying model. Finally, we show that TESS 2 further improves with increased inference-time compute, highlighting the utility of diffusion LMs in having fine-grained controllability over the amount of compute used at inference time. Code and models are available at https://github.com/hamishivi/tess-2.
Diffusion LM을 요즘 생각보다 많이 하네요. 규모가 커지면 방법의 차이는 중요하지 않다고 하는 격언이 있지만 (https://nonint.com/2023/06/10/the-it-in-ai-models-is-the-dataset/) 그래도 특성의 차이가 있을지 생각해보게 되죠.
요즘 Looped Transformer도 많이 나오더군요. (https://arxiv.org/abs/2502.13842, https://arxiv.org/abs/2502.13181) 대안적 아키텍처에 대한 관심은 늘 있는 것이긴 하지만요.
There are quite a many papers on diffusion LMs these days. There's a saying that the differences in methods become less important as the scale increases (https://nonint.com/2023/06/10/the-it-in-ai-models-is-the-dataset/), but it still makes me wonder if there are qualitative differences between them.
Recently, I've also noticed many papers on looped transformers (https://arxiv.org/abs/2502.13842, https://arxiv.org/abs/2502.13181). Of course, there's always interest in alternative architectures.
#diffusion #llm