



Distillation Scaling Laws
(Dan Busbridge, Amitis Shidani, Floris Weers, Jason Ramapuram, Etai Littwin, Russ Webb)

We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated with using distillation at scale; compute allocation for both the teacher and student models can now be done to maximize student performance. We provide compute optimal distillation recipes for when 1) a teacher exists, or 2) a teacher needs training. If many students are to be distilled, or a teacher already exists, distillation outperforms supervised pretraining until a compute level which grows predictably with student size. If one student is to be distilled and a teacher also needs training, supervised learning should be done instead. Additionally, we provide insights across our large scale study of distillation, which increase our understanding of distillation and inform experimental design.
Distillation에 대한 Scaling Law. 주요한 아이디어는 토큰 수가 충분하다면 Distillation이 아니라 일반적인 프리트레이닝이 더 낫다, 따라서 Distillation이 나은 조건과 (예를 들어 Teacher 모델이 이미 있는 경우) 데이터의 양을 결정해야 한다는 것이라고 할 수 있겠네요.
Scaling law for distillation. The main idea is that plain pretraining is better than distillation when the number of training tokens is sufficient. Therefore, we should determine under which conditions (for example, when we already have a teacher model) and with what amount of data distillation would work better than plain training.
#distillation #scaling-law
The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
(Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, Nicholas Thumiger, Aditya Desai, Ion Stoica, Ana Klimovic, Graham Neubig, Joseph E. Gonzalez)
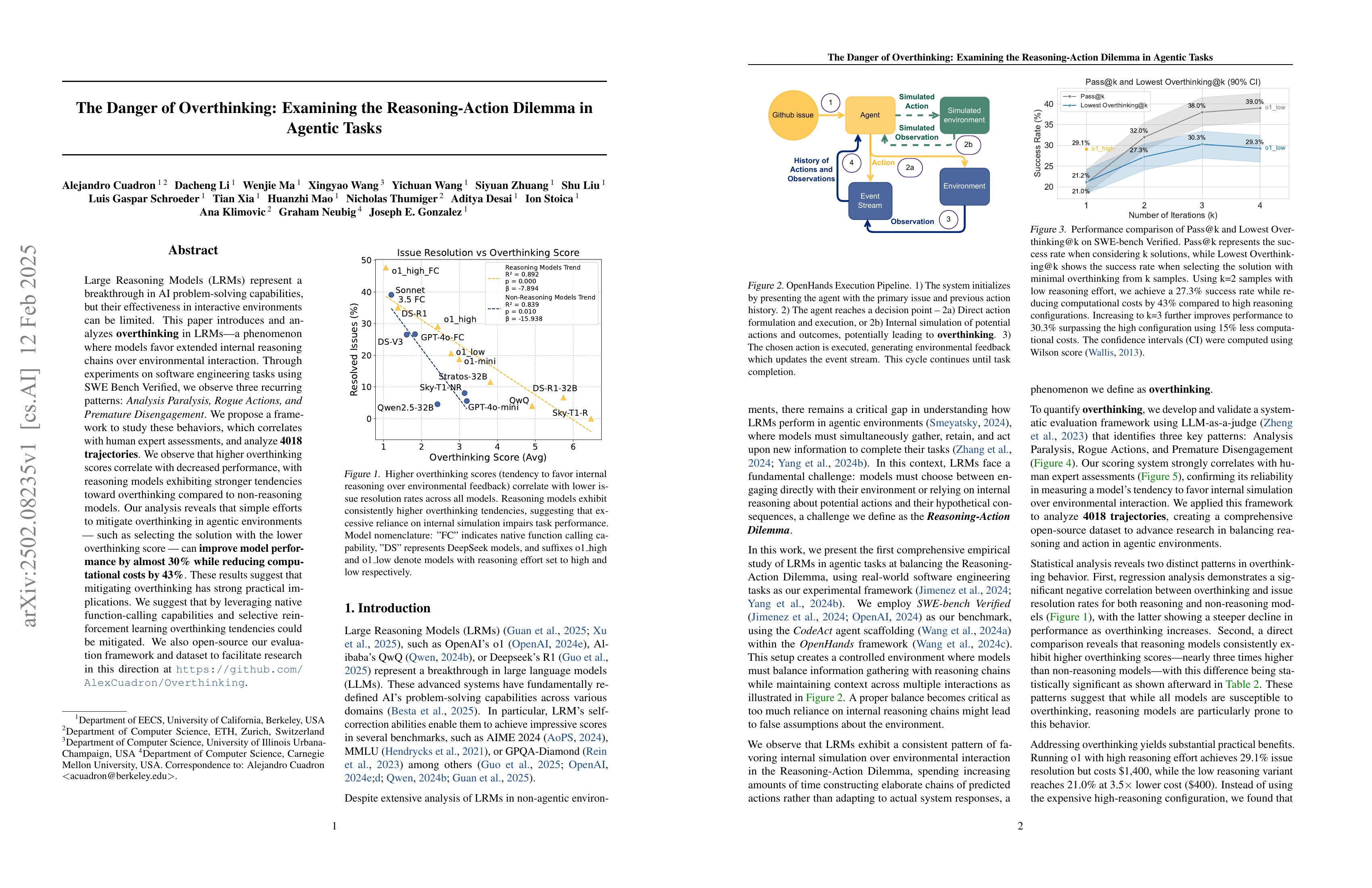
Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited. This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction. Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories. We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models. Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%. These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning overthinking tendencies could be mitigated. We also open-source our evaluation framework and dataset to facilitate research in this direction at https://github.com/AlexCuadron/Overthinking.
모델에 추론 능력이 생기면서 에이전트가 행동하는 대신 생각하는 시간만 지나치게 길어질 수 있다는 아이디어. 재미있는 문제의식이네요. 물론 사고의 길이와 오류율을 단순하게 연결시킬 수는 없겠죠.
이에 대한 대응으로 가장 쉽게 생각할 수 있는 것은 RL 과정에서 중간에 모델이 행동을 할 수 있게 허용하는 것이겠네요.
The idea that agents might spend excessive time thinking instead of taking action as models now have reasoning abilities. This is an intriguing problem to consider. Of course, we can't simply equate the length of thought processes with error rates.
A natural solution to this problem would be to allow the model to take actions at intermediate steps during the reinforcement learning process.
#reasoning #agent
Implicit Language Models are RNNs: Balancing Parallelization and Expressivity
(Mark Schöne, Babak Rahmani, Heiner Kremer, Fabian Falck, Hitesh Ballani, Jannes Gladrow)
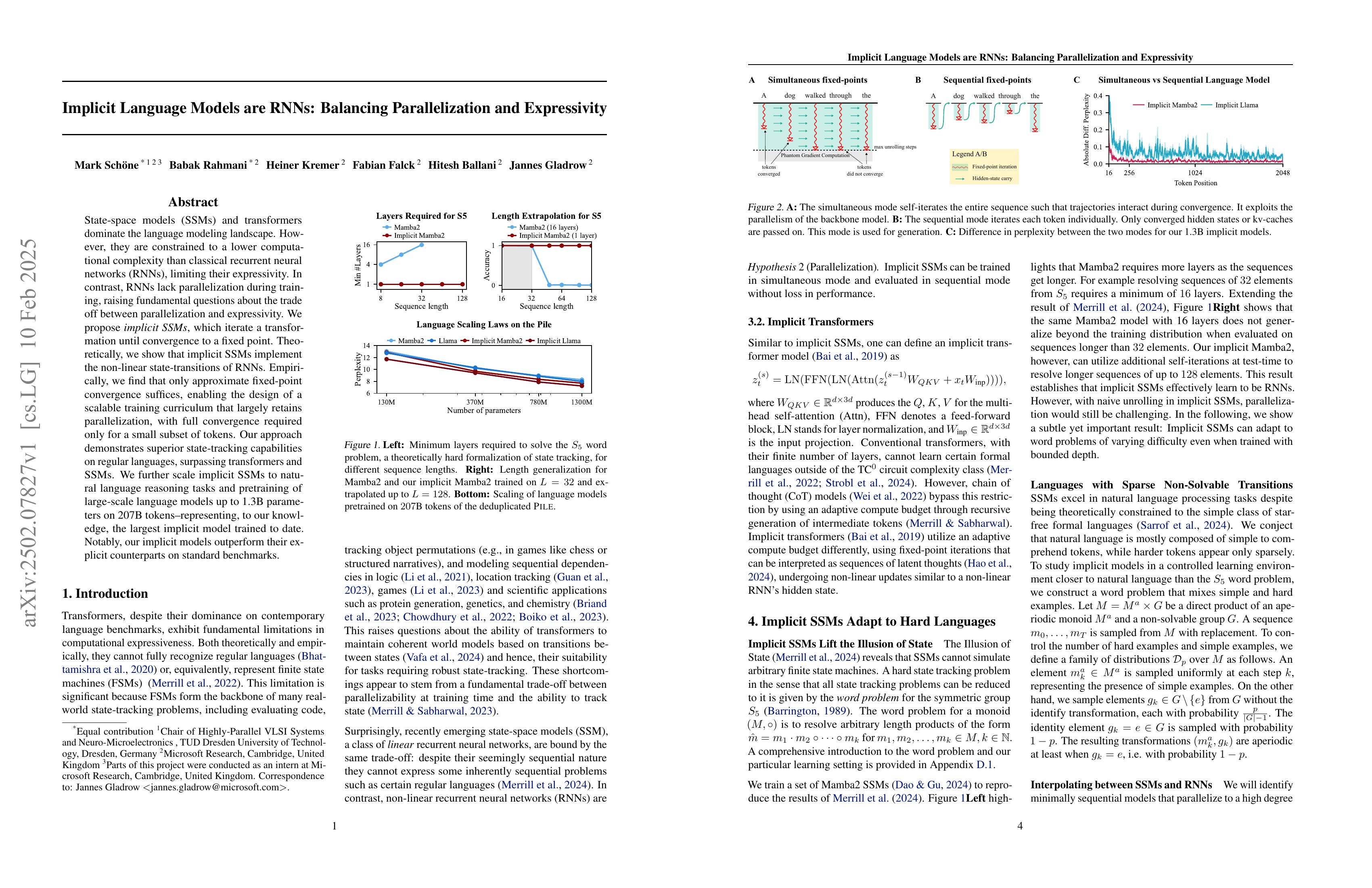
State-space models (SSMs) and transformers dominate the language modeling landscape. However, they are constrained to a lower computational complexity than classical recurrent neural networks (RNNs), limiting their expressivity. In contrast, RNNs lack parallelization during training, raising fundamental questions about the trade off between parallelization and expressivity. We propose implicit SSMs, which iterate a transformation until convergence to a fixed point. Theoretically, we show that implicit SSMs implement the non-linear state-transitions of RNNs. Empirically, we find that only approximate fixed-point convergence suffices, enabling the design of a scalable training curriculum that largely retains parallelization, with full convergence required only for a small subset of tokens. Our approach demonstrates superior state-tracking capabilities on regular languages, surpassing transformers and SSMs. We further scale implicit SSMs to natural language reasoning tasks and pretraining of large-scale language models up to 1.3B parameters on 207B tokens - representing, to our knowledge, the largest implicit model trained to date. Notably, our implicit models outperform their explicit counterparts on standard benchmarks.
State Space Model의 표현력 제약을 Equilibrium Model로 해소. 얼마 전에도 Universal Transformer가 등장했었죠. (https://arxiv.org/abs/2502.05171) 이쪽 연구가 다시 나올지도 모르겠네요.
Addressing the expressivity limitations of state space models using equilibrium models. Recently universal transformers re-appeared as well (https://arxiv.org/abs/2502.05171). Maybe we will meet more research in this direction.
#state-space-model