

2025-12-19

Next-Embedding Prediction Makes Strong Vision Learners
(Sihan Xu, Ziqiao Ma, Wenhao Chai, Xuweiyi Chen, Weiyang Jin, Joyce Chai, Saining Xie, Stella X. Yu)

Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
다음 스텝 임베딩 예측을 사용한 간단한 이미지 프리트레이닝. 임베딩 자체도 같이 학습됨. 다만 Loss 타겟으로 사용할 때에는 Stop Grad를 적용.
Simple vision pretraining by predicting next step embedding. The embedding itself is trained along with this while stop grad is applied when it is used as a target.
#pretraining #self-supervision
Sigma-Moe-Tiny Technical Report
(Qingguo Hu, Zhenghao Lin, Ziyue Yang, Yucheng Ding, Xiao Liu, Yuting Jiang, Ruizhe Wang, Tianyu Chen, Zhongxin Guo, Yifan Xiong, Rui Gao, Lei Qu, Jinsong Su, Peng Cheng, Yeyun Gong)
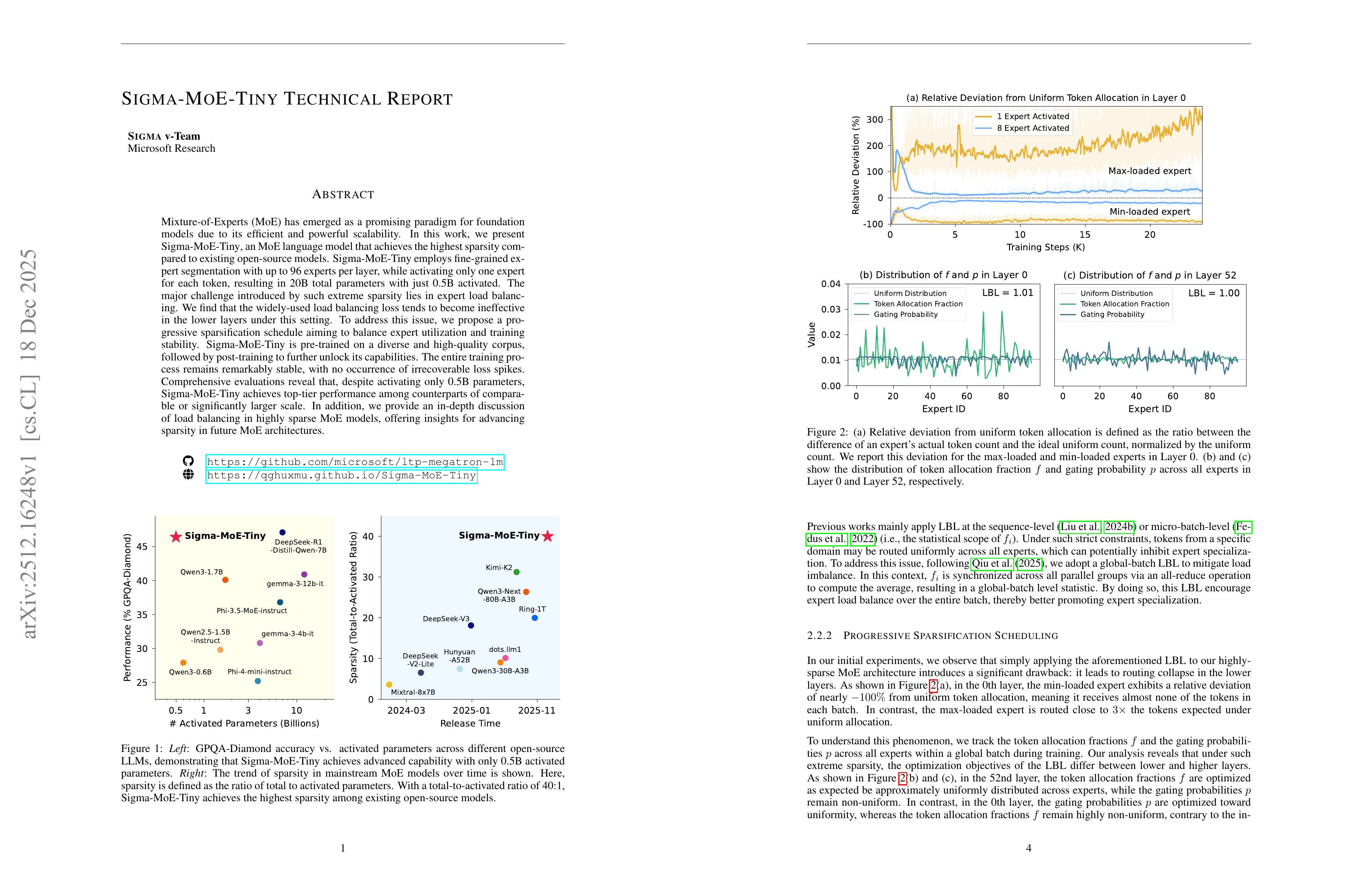
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
96개 Expert 중 top-1 라우팅. 일반적인 로드 밸런싱은 이 정도의 Sparsity에 대해서는, 특히 낮은 단계의 레이어에 대해서는 작동하지 않음. 따라서 학습 과정에서 더 큰 top-K를 사용했다가 후반에 top-1으로 바꾸는 방법을 사용. 다만 일반적인 세팅에 비해 더 나은 디자인이 맞을지?
Top-1 routing out of 96 experts. Typical load balancing does not work for this degree of sparsity, especially for lower layers. Thus they used a larger top-K and later turned to top-1. But would this be better compared to common settings?
#moe
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
(Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, Ning Ding, Zhiyuan Liu)

Recent advances in reinforcement learning for large language models have converged on increasing complexity: multi-stage training pipelines, dynamic hyperparameter schedules, and curriculum learning strategies. This raises a fundamental question: Is this complexity necessary? We present JustRL, a minimal approach using single-stage training with fixed hyperparameters that achieves state-of-the-art performance on two 1.5B reasoning models (54.9% and 64.3% average accuracy across nine mathematical benchmarks) while using 2× less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training exhibits smooth, monotonic improvement over 4,000+ steps without the collapses or plateaus that typically motivate interventions. Critically, ablations reveal that adding “standard tricks” like explicit length penalties and robust verifiers may degrade performance by collapsing exploration. These results suggest that the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline. We release our models and code to establish a simple, validated baseline for the community.
어떤 경우에는 Clip Higher 정도만 사용한 단순한 베이스라인이 잘 작동함. 그러나 어떤 경우에 그게 가능한 것일지?
Sometimes a simple baseline with clip higher just works. But when?
#rl #reasoning
Meta-RL Induces Exploration in Language Agents
(Yulun Jiang, Liangze Jiang, Damien Teney, Michael Moor, Maria Brbic)

Reinforcement learning (RL) has enabled the training of large language model (LLM) agents to interact with the environment and to solve multi-turn long-horizon tasks. However, the RL-trained agents often struggle in tasks that require active exploration and fail to efficiently adapt from trial-and-error experiences. In this paper, we present LaMer, a general Meta-RL framework that enables LLM agents to actively explore and learn from the environment feedback at test time. LaMer consists of two key components: (i) a cross-episode training framework to encourage exploration and long-term rewards optimization; and (ii) in-context policy adaptation via reflection, allowing the agent to adapt their policy from task feedback signal without gradient update. Experiments across diverse environments show that LaMer significantly improves performance over RL baselines, with 11%, 14%, and 19% performance gains on Sokoban, MineSweeper and Webshop, respectively. Moreover, LaMer also demonstrates better generalization to more challenging or previously unseen tasks compared to the RL-trained agents. Overall, our results demonstrate that Meta-RL provides a principled approach to induce exploration in language agents, enabling more robust adaptation to novel environments through learned exploration strategies.
여러 에피소드를 결합하고 Policy를 In-context로 학습시키는 Meta RL.
Meta RL which connects multiple episodes and does in-context adaptation of the policy.
#rl
A Unification of Discrete, Gaussian, and Simplicial Diffusion
(Nuria Alina Chandra, Yucen Lily Li, Alan N. Amin, Alex Ali, Joshua Rollins, Sebastian W. Ober, Aniruddh Raghu, Andrew Gordon Wilson)

To model discrete sequences such as DNA, proteins, and language using diffusion, practitioners must choose between three major methods: diffusion in discrete space, Gaussian diffusion in Euclidean space, or diffusion on the simplex. Despite their shared goal, these models have disparate algorithms, theoretical structures, and tradeoffs: discrete diffusion has the most natural domain, Gaussian diffusion has more mature algorithms, and diffusion on the simplex in principle combines the strengths of the other two but in practice suffers from a numerically unstable stochastic processes. Ideally we could see each of these models as instances of the same underlying framework, and enable practitioners to switch between models for downstream applications. However previous theories have only considered connections in special cases. Here we build a theory unifying all three methods of discrete diffusion as different parameterizations of the same underlying process: the Wright-Fisher population genetics model. In particular, we find simplicial and Gaussian diffusion as two large-population limits. Our theory formally connects the likelihoods and hyperparameters of these models and leverages decades of mathematical genetics literature to unlock stable simplicial diffusion. Finally, we relieve the practitioner of balancing model trade-offs by demonstrating it is possible to train a single model that can perform diffusion in any of these three domains at test time. Our experiments show that Wright-Fisher simplicial diffusion is more stable and outperforms previous simplicial diffusion models on conditional DNA generation. We also show that we can train models on multiple domains at once that are competitive with models trained on any individual domain.
Discrete, Gaussian, Simplex Diffusion의 통합. 메인 아이디어는 Discrete Diffusion 단어를 N번 복사해서 N → ∞에 대해 CLT로 Gaussian Diffusion과 연결하는 것. 여기에서 Reproduction의 개념을 도입하면 Simplex Diffusion으로 연결됨.
Unifying discrete, gaussian, simplex diffusion. The main idea is copying a letter N times in discrete diffusion, and connecting it to gaussian diffusion using CLT when N → ∞. If we further introduce the concept of reproduction, then it is connected to simplex diffusion.
#diffusion