

2025-12-02

DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
(DeepSeek-AI)
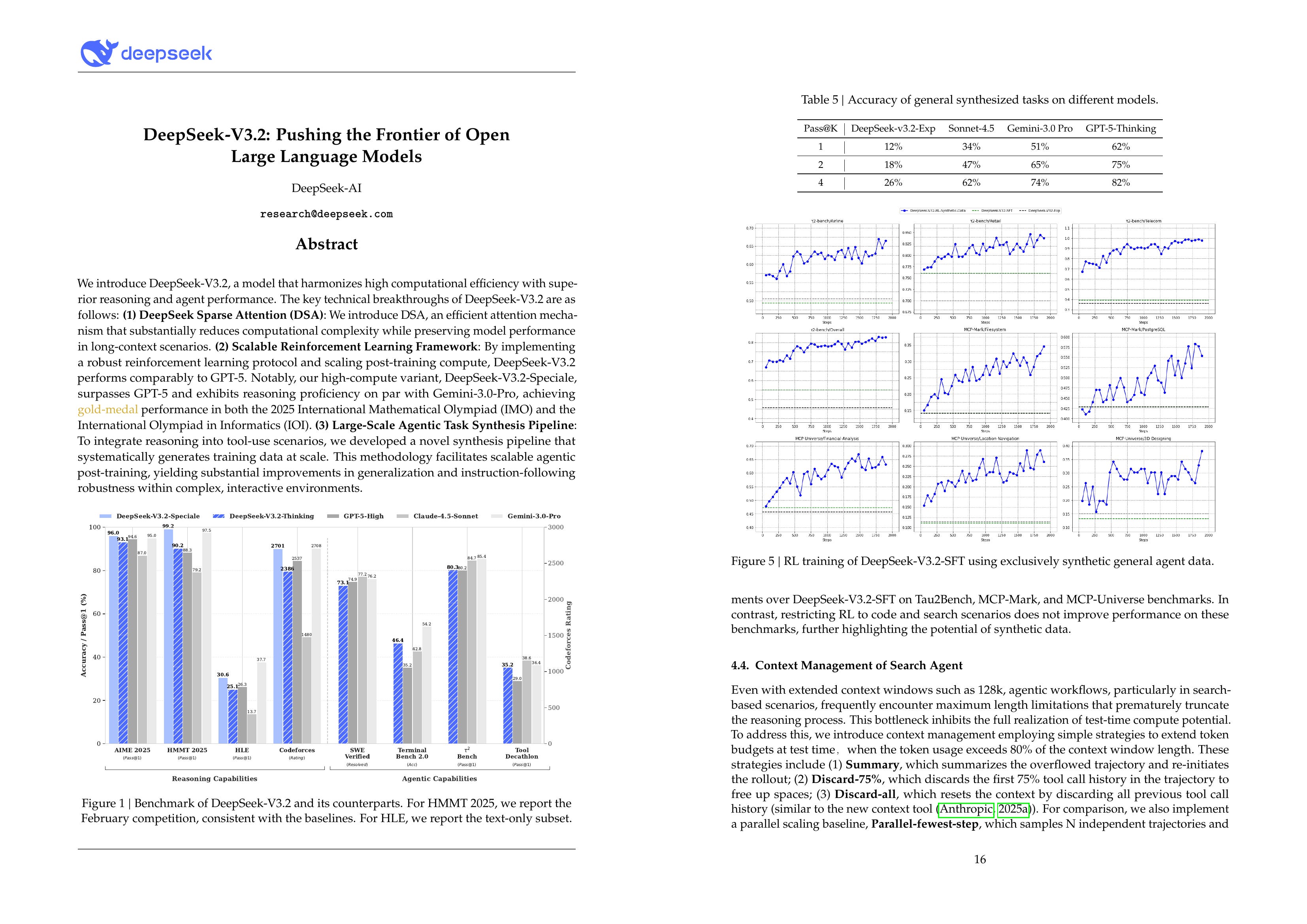
We introduce DeepSeek-V3.2, a model that harmonizes high computational efficiency with superior reasoning and agent performance. The key technical breakthroughs of DeepSeek-V3.2 are as follows: (1) DeepSeek Sparse Attention (DSA): We introduce DSA, an efficient attention mechanism that substantially reduces computational complexity while preserving model performance in long-context scenarios. (2) Scalable Reinforcement Learning Framework: By implementing a robust reinforcement learning protocol and scaling post-training compute, DeepSeek-V3.2 performs comparably to GPT-5. Notably, our high-compute variant, DeepSeek-V3.2-Speciale, surpasses GPT-5 and exhibits reasoning proficiency on par with Gemini-3.0-Pro, achieving gold-medal performance in both the 2025 International Mathematical Olympiad (IMO) and the International Olympiad in Informatics (IOI). (3) Large-Scale Agentic Task Synthesis Pipeline: To integrate reasoning into tool-use scenarios, we developed a novel synthesis pipeline that systematically generates training data at scale. This methodology facilitates scalable agentic post-training, yielding substantial improvements in generalization and instruction-following robustness within complex, interactive environments.
DeepSeek-V3.2(-Speciale) 테크니컬 리포트. DSA와 함께 GRPO 안정화 테크닉 적용. (Unbiased KL 페널티, Loss 마스킹, 라우팅과 샘플링 리플레이). 그리고 합성 데이터베이스를 사용한 합성 에이전트 궤적. Length 페널티를 줄여 Speciale 버전을 구축.
DeepSeek-V3.2(-Speciale) technical report. DSA and GRPO stabilization techniques (unbiased KL penalty, loss masking, routing and sampling replay). And synthetic agentic trajectory using a synthetic database. They made the Speciale version using reduced length penalty.
#rl #reasoning #agent #synthetic-data
TUNA: Taming Unified Visual Representations for Native Unified Multimodal Models
(Zhiheng Liu, Weiming Ren, Haozhe Liu, Zijian Zhou, Shoufa Chen, Haonan Qiu, Xiaoke Huang, Zhaochong An, Fanny Yang, Aditya Patel, Viktar Atliha, Tony Ng, Xiao Han, Chuyan Zhu, Chenyang Zhang, Ding Liu, Juan-Manuel Perez-Rua, Sen He, Jürgen Schmidhuber, Wenhu Chen, Ping Luo, Wei Liu, Tao Xiang, Jonas Schult, Yuren Cong)

Unified multimodal models (UMMs) aim to jointly perform multimodal understanding and generation within a single framework. We present TUNA, a native UMM that builds a unified continuous visual representation by cascading a VAE encoder with a representation encoder. This unified representation space allows end-to-end processing of images and videos for both understanding and generation tasks. Compared to prior UMMs with decoupled representations, TUNA’s unified visual space avoids representation format mismatches introduced by separate encoders, outperforming decoupled alternatives in both understanding and generation. Moreover, we observe that stronger pretrained representation encoders consistently yield better performance across all multimodal tasks, highlighting the importance of the representation encoder. Finally, in this unified setting, jointly training on both understanding and generation data allows the two tasks to benefit from each other rather than interfere. Our extensive experiments on multimodal understanding and generation benchmarks show that TUNA achieves state-of-the-art results in image and video understanding, image and video generation, and image editing, demonstrating the effectiveness and scalability of its unified representation design.
VAE 위에 ViT를 올리고 이 Feature를 이미지 이해와 생성 모두에 사용. 생성은 Flow Matching. 깔끔한 접근. 만약 픽셀 Diffusion이 잘 작동한다면 더 단순해질 수 있음.
ViT on top of VAE, and using those features for understanding and generation. For generation flow matching is used. Simple! If pixel diffusion really works then it could become even simpler.
#image-generation #diffusion #multimodal
From Atomic to Composite: Reinforcement Learning Enables Generalization in Complementary Reasoning
(Sitao Cheng, Xunjian Yin, Ruiwen Zhou, Yuxuan Li, Xinyi Wang, Liangming Pan, William Yang Wang, Victor Zhong)

The mechanism by which RL contributes to reasoning capabilities-whether it incentivizes the synthesis of new skills or merely amplifies existing behaviors-remains a subject of intense debate. In this work, we investigate this question through the lens of Complementary Reasoning, a complex task that requires integrating internal parametric knowledge with external contextual information. Using a controlled synthetic dataset of human biographies, we strictly decouple this ability into two atomic skills: Parametric Reasoning (relying on internal knowledge) and Contextual Reasoning (depending on external information). To rigorously assess capability boundaries, we evaluate generalization across three distinct levels of difficulty: I.I.D., Composition, and Zero-shot settings. We find that while SFT is sufficient for in-distribution performance, it struggles with O.O.D. generalization, particularly in Zero-shot settings where relational combinations are novel. Crucially, we identify the SFT Generalization Paradox: Models supervised solely on the composite task achieve near-perfect in-distribution accuracy but collapse on out-of-distribution generalization, indicating their reliance on rote memorization of path shortcuts. In contrast, we find that RL acts as a reasoning synthesizer rather than a probability amplifier. However, we uncover a strict atomic prerequisite: RL can only synthesize these complex strategies if the base model has first mastered the independent atomic skills (Parametric and Contextual) via SFT. These findings challenge the view of RL as a mere amplifier, suggesting that given sufficient atomic foundations, RL can actively synthesize complex reasoning strategies from learned primitives without explicit supervision on such complex strategies. This indicates that decoupled atomic training followed by RL offers a scalable path to generalization for complex reasoning tasks.
RL은 Atomic Skill의 결합을 통해 일반화를 달성. 단 Atomic Skill이 충분히 잘 학습되어야만 함. 어쩌면 미드트레이닝에서 중요한 것은 Atomic Skill을 함양하는 것일지도.
RL achieves generalization by synthesizing atomic skills - but only when atomic skills are sufficiently learned. Maybe for mid-training what is important is cultivating atomic skills.
#rl #generalization
Stabilizing Reinforcement Learning with LLMs: Formulation and Practices
(Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, An Yang, Jingren Zhou, Junyang Lin)
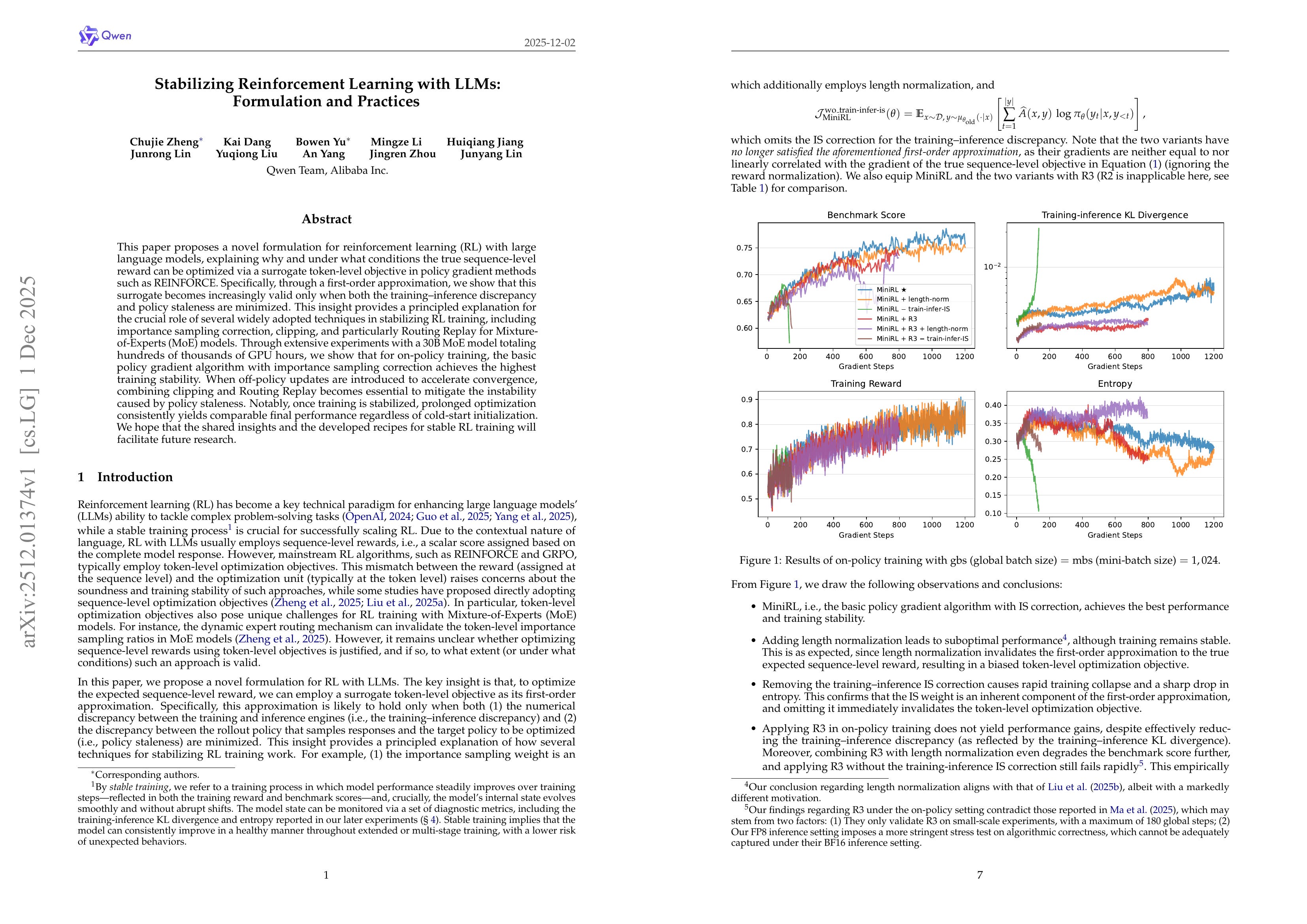
This paper proposes a novel formulation for reinforcement learning (RL) with large language models, explaining why and under what conditions the true sequence-level reward can be optimized via a surrogate token-level objective in policy gradient methods such as REINFORCE. Specifically, through a first-order approximation, we show that this surrogate becomes increasingly valid only when both the training-inference discrepancy and policy staleness are minimized. This insight provides a principled explanation for the crucial role of several widely adopted techniques in stabilizing RL training, including importance sampling correction, clipping, and particularly Routing Replay for Mixture-of-Experts (MoE) models. Through extensive experiments with a 30B MoE model totaling hundreds of thousands of GPU hours, we show that for on-policy training, the basic policy gradient algorithm with importance sampling correction achieves the highest training stability. When off-policy updates are introduced to accelerate convergence, combining clipping and Routing Replay becomes essential to mitigate the instability caused by policy staleness. Notably, once training is stabilized, prolonged optimization consistently yields comparable final performance regardless of cold-start initialization. We hope that the shared insights and the developed recipes for stable RL training will facilitate future research.
RL 안정화. 토큰 단위 Objective를 시퀀스 단위 Objective의 근사로 간주. 그러나 이 근사가 성립하기 위해서는 타겟 Policy와 롤아웃 Policy의 Importance Ratio가 작아야 함. 이 가정 위에서 Objective를 디자인하고 라우팅 리플레이 전략을 비교함. 어쩌면 아주 안정적인 RL 알고리즘이 곧 등장할지도?
Stabilizing RL. Consider token level objective as an approximation to sequence level objective. But for this approximation to hold the importance ratio between target policy and rollout policy should be small. They built the objective on top of this and compared routing replay strategies. Maybe we can get a super stable RL algorithm soon?
#rl
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
(Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, Song Han)
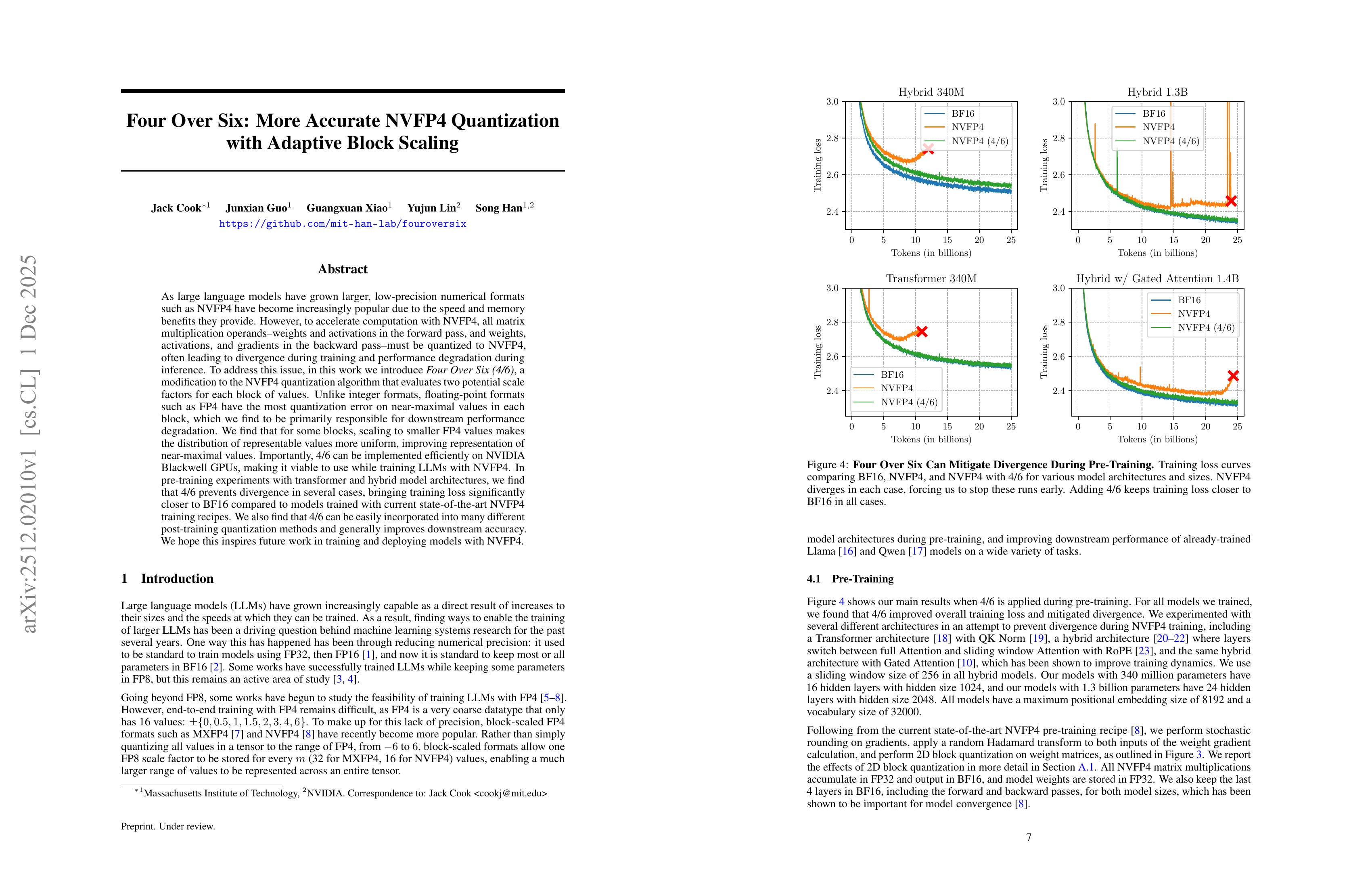
As large language models have grown larger, low-precision numerical formats such as NVFP4 have become increasingly popular due to the speed and memory benefits they provide. However, to accelerate computation with NVFP4, all matrix multiplication operands--weights and activations in the forward pass, and weights, activations, and gradients in the backward pass--must be quantized to NVFP4, often leading to divergence during training and performance degradation during inference. NVFP4 by evaluating multiple potential scale factors for each block of values. To address this issue, in this work we introduce Four Over Six (4/6), a modification to the NVFP4 quantization algorithm that evaluates two potential scale factors for each block of values. Unlike integer formats, floating-point formats such as FP4 have the most quantization error on near-maximal values in each block, which we find to be primarily responsible for downstream performance degradation. We find that for some blocks, scaling to smaller FP4 values makes the distribution of representable values more uniform, improving representation of near-maximal values. Importantly, 4/6 can be implemented efficiently on NVIDIA Blackwell GPUs, making it viable to use while training LLMs with NVFP4. In pre-training experiments with transformer and hybrid model architectures, we find that 4/6 prevents divergence in several cases, bringing training loss significantly closer to BF16 compared to models trained with current state-of-the-art NVFP4 training recipes. We also find that 4/6 can be easily incorporated into many different post-training quantization methods and generally improves downstream accuracy. We hope this inspires future work in training and deploying models with NVFP4.
NVFP4 양자화에 대해서는 값의 범위를 (-6, 6)이 아니라 (-4, 4)로 설정하는 것이 나을 수 있음. 그런데 왜 NVFP4 학습 베이스라인이 모두 발산하는 것일지?
It could be better to scale value ranges to (-4, 4) instead of (-6, 6) for NVFP4 quantization. But why do all NVFP4 training baselines diverge?
#quantization