

2025-11-19

Back to Basics: Let Denoising Generative Models Denoise
(Tianhong Li, Kaiming He)

Today’s denoising diffusion models do not “denoise” in the classical sense, i.e., they do not directly predict clean images. Rather, the neural networks predict noise or a noised quantity. In this paper, we suggest that predicting clean data and predicting noised quantities are fundamentally different. According to the manifold assumption, natural data should lie on a low-dimensional manifold, whereas noised quantities do not. With this assumption, we advocate for models that directly predict clean data, which allows apparently under-capacity networks to operate effectively in very high-dimensional spaces. We show that simple, large-patch Transformers on pixels can be strong generative models: using no tokenizer, no pre-training, and no extra loss. Our approach is conceptually nothing more than “Just image Transformers”, or JiT, as we call it. We report competitive results using JiT with large patch sizes of 16 and 32 on ImageNet at resolutions of 256 and 512, where predicting high-dimensional noised quantities can fail catastrophically. With our networks mapping back to the basics of the manifold, our research goes back to basics and pursues a self-contained paradigm for Transformer-based diffusion on raw natural data.
다시 한 번 차원 문제로. x가 노이즈에 비해 훨씬 낮은 차원을 갖기 때문에 고차원의 입력에 대해서는 x 예측이 ε 혹은 v 예측에 비해 훨씬 잘 작동함. x 예측은 패치 크기 64의 픽셀 입력에 대해서도 작동함!
Dimension problem again. As x has much lower dimension compared to noise, x-prediction works better compared to ε or v prediction for large dimensional inputs. x-prediction even works on pixels with patch size 64!
#diffusion #tokenizer
ARC Is a Vision Problem!
(Keya Hu, Ali Cy, Linlu Qiu, Xiaoman Delores Ding, Runqian Wang, Yeyin Eva Zhu, Jacob Andreas, Kaiming He)

The Abstraction and Reasoning Corpus (ARC) is designed to promote research on abstract reasoning, a fundamental aspect of human intelligence. Common approaches to ARC treat it as a language-oriented problem, addressed by large language models (LLMs) or recurrent reasoning models. However, although the puzzle-like tasks in ARC are inherently visual, existing research has rarely approached the problem from a vision-centric perspective. In this work, we formulate ARC within a vision paradigm, framing it as an image-to-image translation problem. To incorporate visual priors, we represent the inputs on a “canvas” that can be processed like natural images. It is then natural for us to apply standard vision architectures, such as a vanilla Vision Transformer (ViT), to perform image-to-image mapping. Our model is trained from scratch solely on ARC data and generalizes to unseen tasks through test-time training. Our framework, termed Vision ARC (VARC), achieves 60.4% accuracy on the ARC-1 benchmark, substantially outperforming existing methods that are also trained from scratch. Our results are competitive with those of leading LLMs and close the gap to average human performance.
ViT를 From Scratch로 학습시켜서 ARC를 태클하는 것이 가능.
You can just train ViT from scratch to solve ARC.
#benchmark
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
(Ruoyu Qin, Weiran He, Weixiao Huang, Yangkun Zhang, Yikai Zhao, Bo Pang, Xinran Xu, Yingdi Shan, Yongwei Wu, Mingxing Zhang)

Reinforcement Learning (RL) has become critical for advancing modern Large Language Models (LLMs), yet existing synchronous RL systems face severe performance bottlenecks. The rollout phase, which dominates end-to-end iteration time, suffers from substantial long-tail latency and poor resource utilization due to inherent workload imbalance. We present Seer, a novel online context learning system that addresses these challenges by exploiting previously overlooked similarities in output lengths and generation patterns among requests sharing the same prompt. Seer introduces three key techniques: divided rollout for dynamic load balancing, context-aware scheduling, and adaptive grouped speculative decoding. Together, these mechanisms substantially reduce long-tail latency and improve resource efficiency during rollout. Evaluations on production-grade RL workloads demonstrate that Seer improves end-to-end rollout throughput by 74% to 97% and reduces long-tail latency by 75% to 93% compared to state-of-the-art synchronous RL systems, significantly accelerating RL training iterations.
Synchronous RL을 위한 추론 스케줄러. 1. 추론 리퀘스트를 더 작은 청크 단위로 쪼갬 2. 그룹 내에 존재하는 샘플링 길이의 상관관계를 사용해 샘플 길이를 추정하고 이를 사용해 리퀘스트를 스케줄링 3. 최대 드래프트의 길이를 조절하는 Adaptive Speculative Decoding을 사용.
Inference scheduler for synchronous RL. 1. Split each request into smaller chunks 2. Estimate length of responses in groups using intra-group correlation of lengths and schedule requests using this 3. Adaptive speculative decoding that adjusts maximum draft length.
#efficiency #rl
Beat the long tail: Distribution-Aware Speculative Decoding for RL Training
(Zelei Shao, Vikranth Srivatsa, Sanjana Srivastava, Qingyang Wu, Alpay Ariyak, Xiaoxia Wu, Ameen Patel, Jue Wang, Percy Liang, Tri Dao, Ce Zhang, Yiying Zhang, Ben Athiwaratkun, Chenfeng Xu, Junxiong Wang)
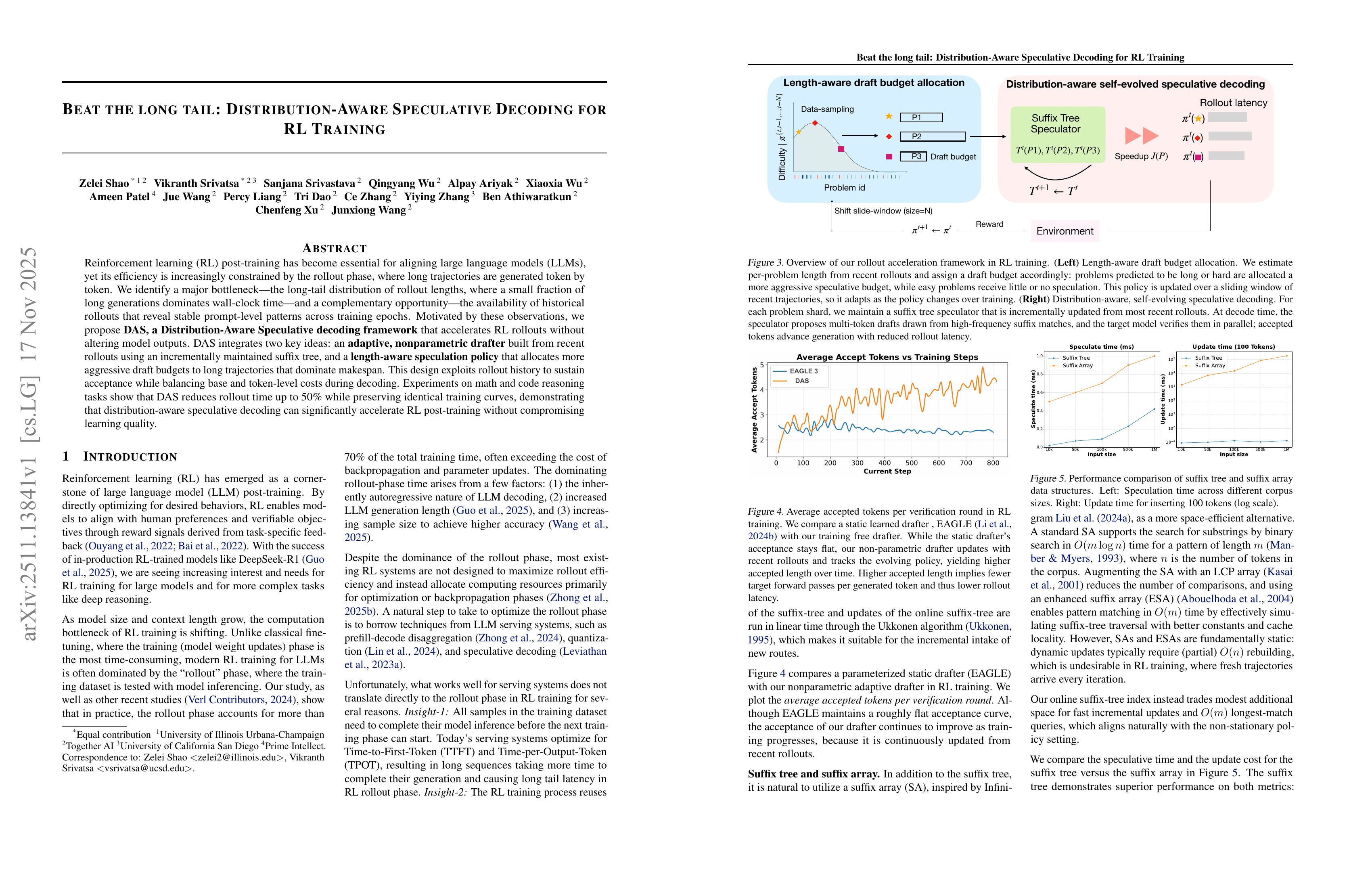
Reinforcement learning(RL) post-training has become essential for aligning large language models (LLMs), yet its efficiency is increasingly constrained by the rollout phase, where long trajectories are generated token by token. We identify a major bottleneck:the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall clock time and a complementary opportunity; the availability of historical rollouts that reveal stable prompt level patterns across training epochs. Motivated by these observations, we propose DAS, a Distribution Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs. DAS integrates two key ideas: an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree, and a length aware speculation policy that allocates more aggressive draft budgets to long trajectories that dominate makespan. This design exploits rollout history to sustain acceptance while balancing base and token level costs during decoding. Experiments on math and code reasoning tasks show that DAS reduces rollout time up to 50% while preserving identical training curves, demonstrating that distribution-aware speculative decoding can significantly accelerate RL post training without compromising learning quality.
RL을 위한 Speculative Decoding. 드래프트 모델을 사용하는 대신 과거 롤아웃에 대한 Suffix Tree를 구축하고 매치된 경로를 사용해 드래프트를 작성. 또한 길이 예측을 사용해 적절한 드래프트의 길이를 지정.
Speculative decoding for RL. Instead of a drafter model they used a suffix tree over past rollouts and proposed drafts using the matched path. And adaptively decided the length of drafts using length prediction.
#rl #efficiency