



2025년 1월 29일

SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
(Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, Yi Ma)

Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain unclear. This paper studies the difference between SFT and RL on generalization and memorization, focusing on text-based rule variants and visual variants. We introduce GeneralPoints, an arithmetic reasoning card game, and adopt V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both textual and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes across both rule-based textual and visual variants. SFT, in contrast, tends to memorize training data and struggles to generalize out-of-distribution scenarios. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in the visual domain. Despite RL's superior generalization, we show that SFT remains essential for effective RL training; SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrates the capability of RL for acquiring generalizable knowledge in complex, multi-modal tasks.
Outcome Reward 기반 RL로 학습시켰을 때 SFT와는 달리 OOD에 대한 일반화가 일어난다는 연구. 이쪽의 RL 세팅은 Revision과 Verification이 포함된 형태라 아주 기본적인 세팅은 아닙니다.
Revision은 꽤 흥미로운 접근이라는 생각을 합니다. (https://arxiv.org/abs/2409.12917)
In contrast to SFT, RL is able to generalize to OOD when trained with outcome rewards. But it is not very "basic" RL as it includes revision and verification.
I think revision is quite interesting approach. (https://arxiv.org/abs/2409.12917)
#rl #generalization
Optimizing Large Language Model Training Using FP4 Quantization
(Ruizhe Wang, Yeyun Gong, Xiao Liu, Guoshuai Zhao, Ziyue Yang, Baining Guo, Zhengjun Zha, Peng Cheng)

The growing computational demands of training large language models (LLMs) necessitate more efficient methods. Quantized training presents a promising solution by enabling low-bit arithmetic operations to reduce these costs. While FP8 precision has demonstrated feasibility, leveraging FP4 remains a challenge due to significant quantization errors and limited representational capacity. This work introduces the first FP4 training framework for LLMs, addressing these challenges with two key innovations: a differentiable quantization estimator for precise weight updates and an outlier clamping and compensation strategy to prevent activation collapse. To ensure stability, the framework integrates a mixed-precision training scheme and vector-wise quantization. Experimental results demonstrate that our FP4 framework achieves accuracy comparable to BF16 and FP8, with minimal degradation, scaling effectively to 13B-parameter LLMs trained on up to 100B tokens. With the emergence of next-generation hardware supporting FP4, our framework sets a foundation for efficient ultra-low precision training.
FP4 학습에 대한 연구. Straight Through Estimator에서 도함수를 Identity 대신 Quantization을 근사하는 함수로 바꾼 것이 주요하군요.
FP8 학습도 그렇게 널리 사용되는 것 같지는 않습니다만 블랙웰이 등장했으니 FP4 혹은 FP6 학습에 대한 연구도 계속 등장할 것 같네요.
The study on FP4 training. The key change is replacing the identity function in the straight through estimator's derivative with a function that approximates quantization.
I think even FP8 training hasn't become very widespread yet. But with the introduction of Blackwell, I expect we'll continue to see more research on FP4 and FP6 training.
#quantization #efficient-training
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
(Hongzhi Huang, Defa Zhu, Banggu Wu, Yutao Zeng, Ya Wang, Qiyang Min, Xun Zhou)

Tokenization is a fundamental component of large language models (LLMs), yet its influence on model scaling and performance is not fully explored. In this paper, we introduce Over-Tokenized Transformers, a novel framework that decouples input and output vocabularies to improve language modeling performance. Specifically, our approach scales up input vocabularies to leverage multi-gram tokens. Through extensive experiments, we uncover a log-linear relationship between input vocabulary size and training loss, demonstrating that larger input vocabularies consistently enhance model performance, regardless of model size. Using a large input vocabulary, we achieve performance comparable to double-sized baselines with no additional cost. Our findings highlight the importance of tokenization in scaling laws and provide practical insight for tokenizer design, paving the way for more efficient and powerful LLMs.
n-gram 입력 임베딩과 Multi Token Prediction을 적용한 시도.
Language models with n-gram input embeddings and multi token prediction.
#lm #tokenizer
Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity
(Weixin Liang, Junhong Shen, Genghan Zhang, Ning Dong, Luke Zettlemoyer, Lili Yu)

State Space Models (SSMs) have emerged as efficient alternatives to Transformers for sequential modeling, but their inability to leverage modality-specific features limits their performance in multi-modal pretraining. Here, we propose Mixture-of-Mamba, a novel SSM architecture that introduces modality-aware sparsity through modality-specific parameterization of the Mamba block. Building on Mixture-of-Transformers (W. Liang et al. arXiv:2411.04996; 2024), we extend the benefits of modality-aware sparsity to SSMs while preserving their computational efficiency. We evaluate Mixture-of-Mamba across three multi-modal pretraining settings: Transfusion (interleaved text and continuous image tokens with diffusion loss), Chameleon (interleaved text and discrete image tokens), and an extended three-modality framework incorporating speech. Mixture-of-Mamba consistently reaches the same loss values at earlier training steps with significantly reduced computational costs. In the Transfusion setting, Mixture-of-Mamba achieves equivalent image loss using only 34.76% of the training FLOPs at the 1.4B scale. In the Chameleon setting, Mixture-of-Mamba reaches similar image loss with just 42.50% of the FLOPs at the 1.4B scale, and similar text loss with just 65.40% of the FLOPs. In the three-modality setting, MoM matches speech loss at 24.80% of the FLOPs at the 1.4B scale. Our ablation study highlights the synergistic effects of decoupling projection components, where joint decoupling yields greater gains than individual modifications. These results establish modality-aware sparsity as a versatile and effective design principle, extending its impact from Transformers to SSMs and setting new benchmarks in multi-modal pretraining. Our code can be accessed at https://github.com/Weixin-Liang/Mixture-of-Mamba
Mamba 기반 멀티모달 (Transfusion, https://arxiv.org/abs/2408.11039) 모델에서 모달리티별로 다른 Weight를 사용한다는 아이디어. 모달리티에 따라 Weight를 분리하는 것은 종종 나오는 아이디어인데 이쪽은 Mamba에 대해서 했군요.
Mamba-based multimodal models like Transfusion (https://arxiv.org/abs/2408.11039) are using modality-specific weights. It's a common idea to separate weights for different modalities, but this paper does it with Mamba.
#multimodal #diffusion #image-generation #state-space-model
Visual Generation Without Guidance
(Huayu Chen, Kai Jiang, Kaiwen Zheng, Jianfei Chen, Hang Su, Jun Zhu)

Classifier-Free Guidance (CFG) has been a default technique in various visual generative models, yet it requires inference from both conditional and unconditional models during sampling. We propose to build visual models that are free from guided sampling. The resulting algorithm, Guidance-Free Training (GFT), matches the performance of CFG while reducing sampling to a single model, halving the computational cost. Unlike previous distillation-based approaches that rely on pretrained CFG networks, GFT enables training directly from scratch. GFT is simple to implement. It retains the same maximum likelihood objective as CFG and differs mainly in the parameterization of conditional models. Implementing GFT requires only minimal modifications to existing codebases, as most design choices and hyperparameters are directly inherited from CFG. Our extensive experiments across five distinct visual models demonstrate the effectiveness and versatility of GFT. Across domains of diffusion, autoregressive, and masked-prediction modeling, GFT consistently achieves comparable or even lower FID scores, with similar diversity-fidelity trade-offs compared with CFG baselines, all while being guidance-free. Code will be available at https://github.com/thu-ml/GFT.
Classifier Free Guidance의 샘플링 함수를 직접 학습시키는 방법.
The method of directly train sampling function in classifier free guidance.
#diffusion #sampling #efficiency
Baichuan-Omni-1.5 Technical Report
(Yadong Li, Jun Liu, Tao Zhang, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, Chong Li, Yuanbo Fang, Dongdong Kuang, Mingrui Wang, Chenglin Zhu, Youwei Zhang, Hongyu Guo, Fengyu Zhang, Yuran Wang, Bowen Ding, Wei Song, Xu Li, Yuqi Huo, Zheng Liang, Shusen Zhang, Xin Wu, Shuai Zhao, Linchu Xiong, Yozhen Wu, Jiahui Ye, Wenhao Lu, Bowen Li, Yan Zhang, Yaqi Zhou, Xin Chen, Lei Su, Hongda Zhang, Fuzhong Chen, Xuezhen Dong, Na Nie, Zhiying Wu, Bin Xiao, Ting Li, Shunya Dang, Ping Zhang, Yijia Sun, Jincheng Wu, Jinjie Yang, Xionghai Lin, Zhi Ma, Kegeng Wu, Jia li, Aiyuan Yang, Hui Liu, Jianqiang Zhang, Xiaoxi Chen, Guangwei Ai, Wentao Zhang, Yicong Chen, Xiaoqin Huang, Kun Li, Wenjing Luo, Yifei Duan, Lingling Zhu, Ran Xiao, Zhe Su, Jiani Pu, Dian Wang, Xu Jia, Tianyu Zhang, Mengyu Ai, Mang Wang, Yujing Qiao, Lei Zhang, Yanjun Shen, Fan Yang, Miao Zhen, Yijie Zhou, Mingyang Chen, Fei Li, Chenzheng Zhu, Keer Lu, Yaqi Zhao, Hao Liang, Youquan Li, Yanzhao Qin, Linzhuang Sun, Jianhua Xu, Haoze Sun, Mingan Lin, Zenan Zhou, Weipeng Chen)
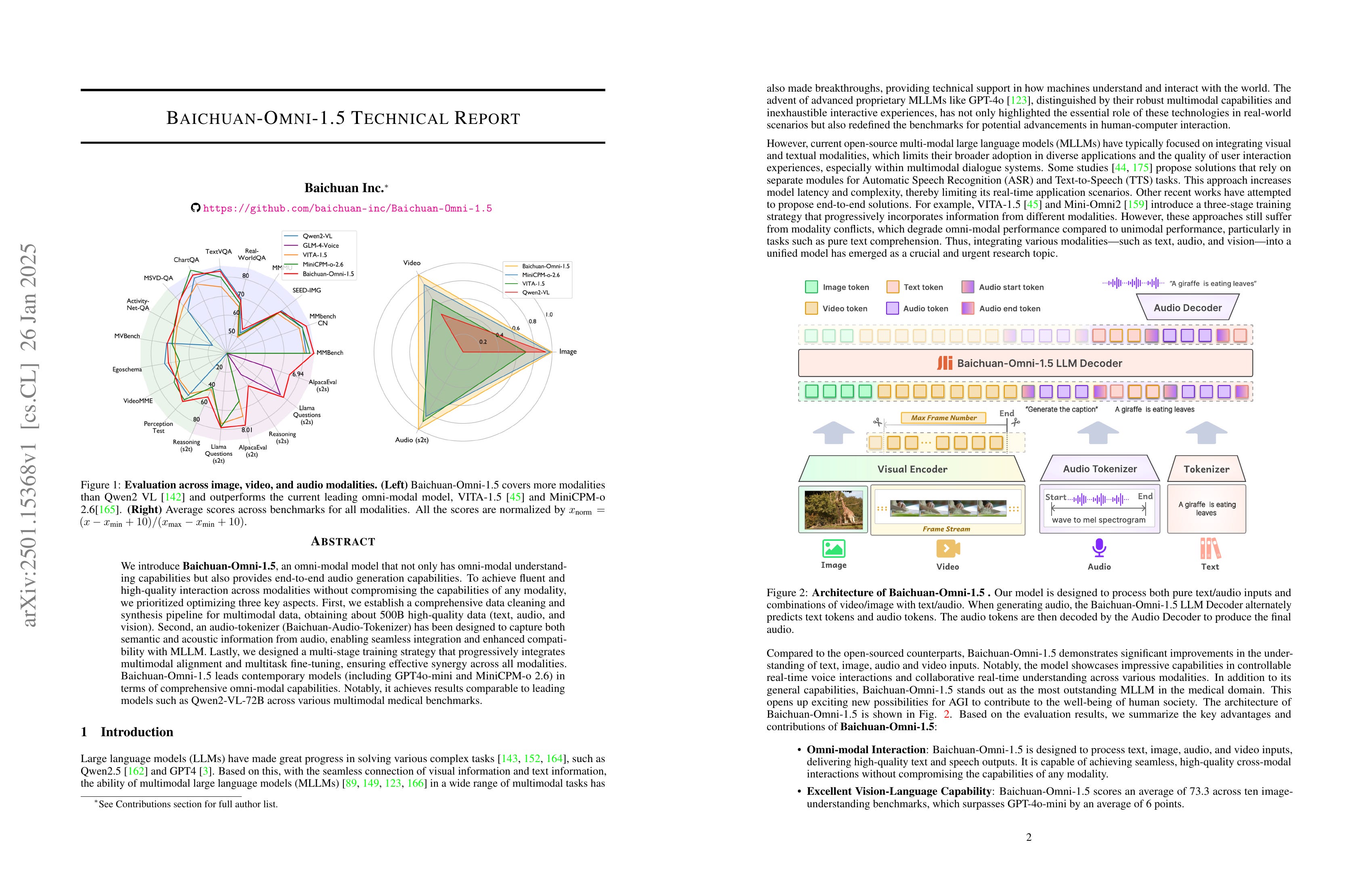
We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Baichuan은 옴니 모달 모델 개발을 하고 있었군요.
Omni-modal model from Baichuan.
#multimodal #audio-generation #video-language