



2025년 1월 17일

Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
(Philippe Hansen-Estruch, David Yan, Ching-Yao Chung, Orr Zohar, Jialiang Wang, Tingbo Hou, Tao Xu, Sriram Vishwanath, Peter Vajda, Xinlei Chen)

Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance. Our work aims to conduct an exploration of scaling in auto-encoders to fill in this blank. To facilitate this exploration, we replace the typical convolutional backbone with an enhanced Vision Transformer architecture for Tokenization (ViTok). We train ViTok on large-scale image and video datasets far exceeding ImageNet-1K, removing data constraints on tokenizer scaling. We first study how scaling the auto-encoder bottleneck affects both reconstruction and generation -- and find that while it is highly correlated with reconstruction, its relationship with generation is more complex. We next explored the effect of separately scaling the auto-encoders' encoder and decoder on reconstruction and generation performance. Crucially, we find that scaling the encoder yields minimal gains for either reconstruction or generation, while scaling the decoder boosts reconstruction but the benefits for generation are mixed. Building on our exploration, we design ViTok as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
이미지와 비디오 토크나이저의 인코더 및 디코더의 크기, 인코딩된 코드의 크기, Loss에 대한 분석. 전반적으로는 Reconstruction을 잘 하는 것이 더 나은 생성 모델로 이어지지는 않는다는 결론입니다. 중요한 문제는 코드의 크기가 커지면 생성 모델이 모델링하기 어려워하는 문제, 인코더가 커지면서 코드가 복잡해지는 효과, 디코더가 커지면서 코드에서는 정보가 빠지고 그 부분을 디코더가 커버해버리는 효과 등이 겹치는 것 같네요.
Analysis of the effects of encoder and decoder sizes, encoded code sizes, and loss functions for image and video tokenizers. The overall conclusion is that better reconstruction does not necessarily lead to better generation. Key issues appear to be larger code sizes make it difficult for generative models to predict effectively, scaling up the encoder results in more complex codes, and scaling up the decoder allows some information to be omitted from the code, which is then compensated for by the decoder's increased generative capacity.
#tokenizer #vae #image-generation #video-generation
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
(Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, Saining Xie)
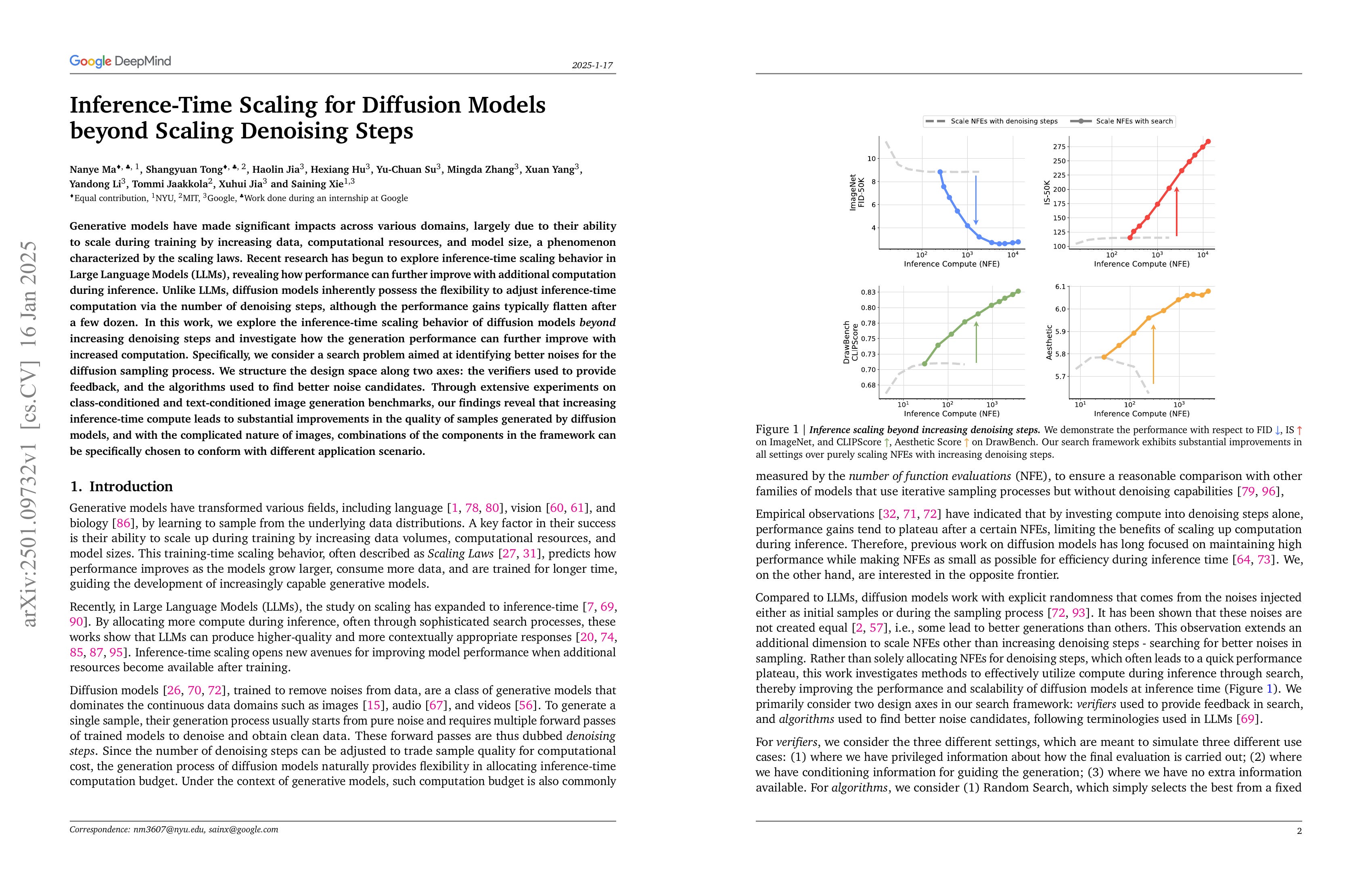
Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws. Recent research has begun to explore inference-time scaling behavior in Large Language Models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of denoising steps, although the performance gains typically flatten after a few dozen. In this work, we explore the inference-time scaling behavior of diffusion models beyond increasing denoising steps and investigate how the generation performance can further improve with increased computation. Specifically, we consider a search problem aimed at identifying better noises for the diffusion sampling process. We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better noise candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario.
디노이징 스텝 증가를 넘어서는 Diffusion에 대한 Inference Time Scaling. 이미지 평가를 위한 Verifier를 두고 탐색 알고리즘을 적용해서 노이즈를 찾는 형태입니다. 탐색 알고리즘을 몇 가지 고안했는데 알고리즘들이 초기 노이즈 지점에서 크게 벗어나기 힘들어서인지 오히려 랜덤 탐색이 강력한 모습이네요.
This paper explores inference-time scaling for diffusion models beyond increasing denoising steps. It employs verifiers for image evaluation and applies search algorithms to find optimal noise. The authors devised several search algorithms, but interestingly, random search proved quite powerful compared to more sophisticated algorithms, possibly because these algorithms struggle to deviate significantly from the initial noise points.
#inference-time-scaling #diffusion #search
Aligning Instruction Tuning with Pre-training
(Yiming Liang, Tianyu Zheng, Xinrun Du, Ge Zhang, Xingwei Qu, Xiang Yue, Chujie Zheng, Jiaheng Liu, Lei Ma, Wenhu Chen, Guoyin Wang, Zhaoxiang Zhang, Wenhao Huang, Jiajun Zhang)

Instruction tuning enhances large language models (LLMs) to follow human instructions across diverse tasks, relying on high-quality datasets to guide behavior. However, these datasets, whether manually curated or synthetically generated, are often narrowly focused and misaligned with the broad distributions captured during pre-training, limiting LLM generalization and effective use of pre-trained knowledge. We propose Aligning Instruction Tuning with Pre-training (AITP), a method that bridges this gap by identifying coverage shortfalls in instruction-tuning datasets and rewriting underrepresented pre-training data into high-quality instruction-response pairs. This approach enriches dataset diversity while preserving task-specific objectives. Evaluations on three fully open LLMs across eight benchmarks demonstrate consistent performance improvements with AITP. Ablations highlight the benefits of adaptive data selection, controlled rewriting, and balanced integration, emphasizing the importance of aligning instruction tuning with pre-training distributions to unlock the full potential of LLMs.
프리트레이닝 데이터셋 중 SFT 데이터셋이 커버하지 못하는 영역을 발굴해서 그 데이터셋들을 QA 데이터로 전환한다는 아이디어. QA라는 단일 과제를 넘어서 과제들을 확장하는 방향으로 나아가면 더 재미있을 듯 하네요.
This paper presents an interesting idea of identifying areas in pre-training datasets that are not covered by SFT datasets and transforming them into QA data. It would be even more intriguing if this approach could be extended beyond the single task of QA to encompass a wider range of tasks not covered by existing datasets.
#instruction-tuning
Beyond Reward Hacking: Causal Rewards for Large Language Model Alignment
(Chaoqi Wang, Zhuokai Zhao, Yibo Jiang, Zhaorun Chen, Chen Zhu, Yuxin Chen, Jiayi Liu, Lizhu Zhang, Xiangjun Fan, Hao Ma, Sinong Wang)

Recent advances in large language models (LLMs) have demonstrated significant progress in performing complex tasks. While Reinforcement Learning from Human Feedback (RLHF) has been effective in aligning LLMs with human preferences, it is susceptible to spurious correlations in reward modeling. Consequently, it often introduces biases-such as length bias, sycophancy, conceptual bias, and discrimination that hinder the model's ability to capture true causal relationships. To address this, we propose a novel causal reward modeling approach that integrates causal inference to mitigate these spurious correlations. Our method enforces counterfactual invariance, ensuring reward predictions remain consistent when irrelevant variables are altered. Through experiments on both synthetic and real-world datasets, we show that our approach mitigates various types of spurious correlations effectively, resulting in more reliable and fair alignment of LLMs with human preferences. As a drop-in enhancement to the existing RLHF workflow, our causal reward modeling provides a practical way to improve the trustworthiness and fairness of LLM finetuning.
길이 같은 변수에 의해서 Spurious Correlation이 Reward Model에 미치는 영향을 억제하려는 시도. 결과적으로 이 변수에 의해서 Reward Score의 분포가 변화하는 것을 억제하는 Regularization을 적용하는 형태입니다.
인과 추정의 문제가 늘 그렇듯 Confounding Factor들을 어떻게 파악할 것인가가 문제가 되죠. (https://arxiv.org/abs/2409.13156)
This study attempts to suppress the effect of spurious correlations on reward models caused by variables such as length. The resulting method applies regularization that inhibits changes in the distribution of reward scores due to these variables.
As with common causal inference problems, the main challenge lies in how to identify and specify the confounding factors. (https://arxiv.org/abs/2409.13156)
#reward-model #alignment #rlhf
RLHS: Mitigating Misalignment in RLHF with Hindsight Simulation
(Kaiqu Liang, Haimin Hu, Ryan Liu, Thomas L. Griffiths, Jaime Fernández Fisac)

Generative AI systems like foundation models (FMs) must align well with human values to ensure their behavior is helpful and trustworthy. While Reinforcement Learning from Human Feedback (RLHF) has shown promise for optimizing model performance using human judgments, existing RLHF pipelines predominantly rely on immediate feedback, which can fail to accurately reflect the downstream impact of an interaction on users' utility. We demonstrate that feedback based on evaluators' foresight estimates of downstream consequences systematically induces Goodhart's Law dynamics, incentivizing misaligned behaviors like sycophancy and deception and ultimately degrading user outcomes. To alleviate this, we propose decoupling evaluation from prediction by refocusing RLHF on hindsight feedback. Our theoretical analysis reveals that conditioning evaluator feedback on downstream observations mitigates misalignment and improves expected human utility, even when these observations are simulated by the AI system itself. To leverage this insight in a practical alignment algorithm, we introduce Reinforcement Learning from Hindsight Simulation (RLHS), which first simulates plausible consequences and then elicits feedback to assess what behaviors were genuinely beneficial in hindsight. We apply RLHS to two widely-employed online and offline preference optimization methods -- Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) -- and show empirically that misalignment is significantly reduced with both methods. Through an online human user study, we show that RLHS consistently outperforms RLHF in helping users achieve their goals and earns higher satisfaction ratings, despite being trained solely with simulated hindsight feedback. These results underscore the importance of focusing on long-term consequences, even simulated ones, to mitigate misalignment in RLHF.
재미있는 문제의식이네요. 모델의 응답을 평가할 때 응답이 생성된 직후에 한다면 그 시점에 사람이 생각하는 응답의 유용성을 기반으로 평가하는 것이죠. 그러나 실제 응답의 가치는 그 응답에 따라 의사결정을 했을 때의 결과에 있죠.
그러나 의사결정을 했을 때의 결과를 알기는 어려우니 시뮬레이션 등을 통해 결과에 대해 좀 더 나은 판단을 할 수 있도록 한다면 어떨까 하는 아이디어입니다.
This paper raises an interesting issue. When evaluating a model's responses, if we do so immediately after generation, we base our assessment on how useful we think the response will be at that moment. However, the true value of a response lies in the outcome of decisions made based on it.
Since it's difficult to know the actual results of decision-making, this paper proposes the idea of enabling better judgment of outcomes through methods like simulation.
#alignment