



2025년 1월

The Lessons of Developing Process Reward Models in Mathematical Reasoning
(Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin)
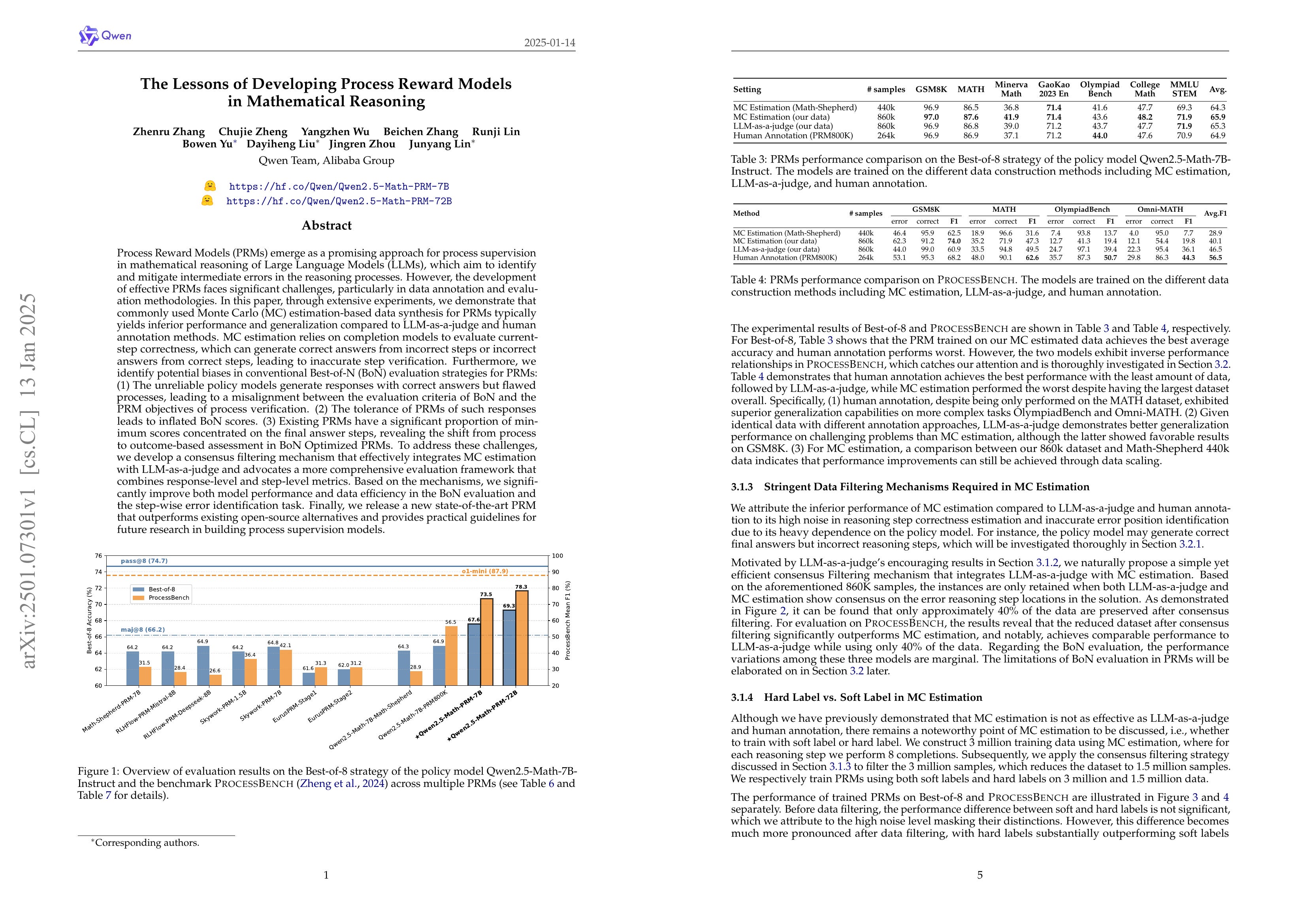
Process Reward Models (PRMs) emerge as a promising approach for process supervision in mathematical reasoning of Large Language Models (LLMs), which aim to identify and mitigate intermediate errors in the reasoning processes. However, the development of effective PRMs faces significant challenges, particularly in data annotation and evaluation methodologies. In this paper, through extensive experiments, we demonstrate that commonly used Monte Carlo (MC) estimation-based data synthesis for PRMs typically yields inferior performance and generalization compared to LLM-as-a-judge and human annotation methods. MC estimation relies on completion models to evaluate current-step correctness, leading to inaccurate step verification. Furthermore, we identify potential biases in conventional Best-of-N (BoN) evaluation strategies for PRMs: (1) The unreliable policy models generate responses with correct answers but flawed processes, leading to a misalignment between the evaluation criteria of BoN and the PRM objectives of process verification. (2) The tolerance of PRMs of such responses leads to inflated BoN scores. (3) Existing PRMs have a significant proportion of minimum scores concentrated on the final answer steps, revealing the shift from process to outcome-based assessment in BoN Optimized PRMs. To address these challenges, we develop a consensus filtering mechanism that effectively integrates MC estimation with LLM-as-a-judge and advocates a more comprehensive evaluation framework that combines response-level and step-level metrics. Based on the mechanisms, we significantly improve both model performance and data efficiency in the BoN evaluation and the step-wise error identification task. Finally, we release a new state-of-the-art PRM that outperforms existing open-source alternatives and provides practical guidelines for future research in building process supervision models.
Process Reward Model에 대한 분석. 정답 여부로 과정에 대한 평가를 학습한 모델들은 (MC) PRM에 대한 벤치마크 점수에 비해 (https://arxiv.org/abs/2412.06559) BoN 평가의 점수가 부풀려지는 경향이 있다고. 이는 과정에 대한 평가가 정확하지 않기 때문입니다.
이에 대해서는 LLM Critic이 오히려 정확했다고 하네요. 그래서 LLM Critic으로 추가 필터링 하는 시도를 했습니다.
Analysis of process reward model. Models trained to evaluate processes based on final answer correctness (MC) tend to have inflated scores in BoN evaluations compared to PRM benchmarks (https://arxiv.org/abs/2412.06559). This is due to inaccuracies in process evaluation.
Interestingly, LLM critics were found to be more accurate in this regard. As a result, the researchers attempted to further filter samples using LLM critics.
#reward-model
SPAM: Spike-Aware Adam with Momentum Reset for Stable LLM Training
(Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, Shiwei Liu)
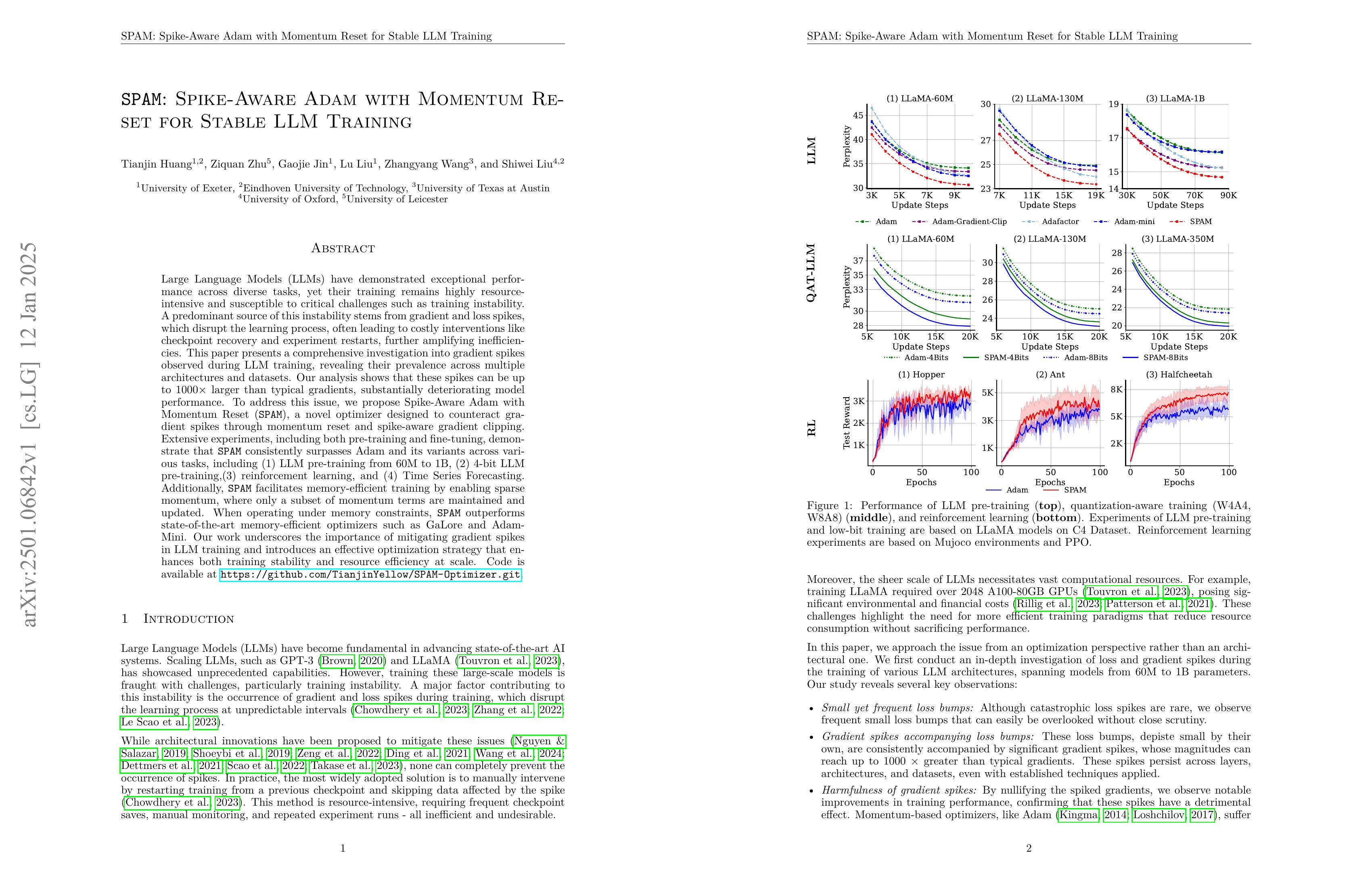
Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks, yet their training remains highly resource-intensive and susceptible to critical challenges such as training instability. A predominant source of this instability stems from gradient and loss spikes, which disrupt the learning process, often leading to costly interventions like checkpoint recovery and experiment restarts, further amplifying inefficiencies. This paper presents a comprehensive investigation into gradient spikes observed during LLM training, revealing their prevalence across multiple architectures and datasets. Our analysis shows that these spikes can be up to 1000× larger than typical gradients, substantially deteriorating model performance. To address this issue, we propose Spike-Aware Adam with Momentum Reset SPAM, a novel optimizer designed to counteract gradient spikes through momentum reset and spike-aware gradient clipping. Extensive experiments, including both pre-training and fine-tuning, demonstrate that SPAM consistently surpasses Adam and its variants across various tasks, including (1) LLM pre-training from 60M to 1B, (2) 4-bit LLM pre-training,(3) reinforcement learning, and (4) Time Series Forecasting. Additionally, SPAM facilitates memory-efficient training by enabling sparse momentum, where only a subset of momentum terms are maintained and updated. When operating under memory constraints, SPAM outperforms state-of-the-art memory-efficient optimizers such as GaLore and Adam-Mini. Our work underscores the importance of mitigating gradient spikes in LLM training and introduces an effective optimization strategy that enhances both training stability and resource efficiency at scale. Code is available at https://github.com/TianjinYellow/SPAM-Optimizer.git
그래디언트 스파이크의 영향을 감소시키기 위해 Adam의 모멘텀을 주기적으로 리셋하고 그래디언트를 클리핑하는 방법.
A method to mitigate the impact of gradient spikes by periodically resetting momentums in Adam and applying gradient clipping.
#optimizer
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
(Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vulić, Furu Wei)

Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex spatial reasoning tasks. Nonetheless, human cognition extends beyond language alone, enabling the remarkable capability to think in both words and images. Inspired by this mechanism, we propose a new reasoning paradigm, Multimodal Visualization-of-Thought (MVoT). It enables visual thinking in MLLMs by generating image visualizations of their reasoning traces. To ensure high-quality visualization, we introduce token discrepancy loss into autoregressive MLLMs. This innovation significantly improves both visual coherence and fidelity. We validate this approach through several dynamic spatial reasoning tasks. Experimental results reveal that MVoT demonstrates competitive performance across tasks. Moreover, it exhibits robust and reliable improvements in the most challenging scenarios where CoT fails. Ultimately, MVoT establishes new possibilities for complex reasoning tasks where visual thinking can effectively complement verbal reasoning.
이미지로 CoT를 하게 했을 때 공간적 추론에 도움이 된다는 연구. 지금은 각 과제에 대한 이미지 타겟을 직접 주는 형태이지만 만약 RL을 통해 추론을 위한 이미지를 생성할 수 있게 된다면 좀 더 재미있어질 것 같네요.
This study shows that generating images for CoT reasoning helps with spatial reasoning tasks. Currently, the model is directly traind to generate target images for each specific task, but it would be more interesting if we could use reinforcement learning to enable the model to generate its own images for reasoning.
#reasoning #multimodal
Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
(Muru Zhang, Mayank Mishra, Zhongzhu Zhou, William Brandon, Jue Wang, Yoon Kim, Jonathan Ragan-Kelley, Shuaiwen Leon Song, Ben Athiwaratkun, Tri Dao)

Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 30% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens.
Skip Connection을 바로 이전이 아니라 그 이전 레이어로 계산해서 연산과 통신을 중첩하는 방법. Parallel Layers 같은 아이디어네요.
This method calculates skip connections using the output from two layers back instead of the immediately previous layer, allowing computation and communication to overlap. It's an idea similar to parallel layers.
#efficiency #parallelism