

2025-09-26

RLBFF: Binary Flexible Feedback to bridge between Human Feedback & Verifiable Rewards
(Zhilin Wang, Jiaqi Zeng, Olivier Delalleau, Ellie Evans, Daniel Egert, Hoo-Chang Shin, Felipe Soares, Yi Dong, Oleksii Kuchaiev)

Reinforcement Learning with Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR) are the main RL paradigms used in LLM post-training, each offering distinct advantages. However, RLHF struggles with interpretability and reward hacking because it relies on human judgments that usually lack explicit criteria, whereas RLVR is limited in scope by its focus on correctness-based verifiers. We propose Reinforcement Learning with Binary Flexible Feedback (RLBFF), which combines the versatility of human-driven preferences with the precision of rule-based verification, enabling reward models to capture nuanced aspects of response quality beyond mere correctness. RLBFF extracts principles that can be answered in a binary fashion (e.g. accuracy of information: yes, or code readability: no) from natural language feedback. Such principles can then be used to ground Reward Model training as an entailment task (response satisfies or does not satisfy an arbitrary principle). We show that Reward Models trained in this manner can outperform Bradley-Terry models when matched for data and achieve top performance on RM-Bench (86.2%) and JudgeBench (81.4%, #1 on leaderboard as of September 24, 2025). Additionally, users can specify principles of interest at inference time to customize the focus of our reward models, in contrast to Bradley-Terry models. Finally, we present a fully open source recipe (including data) to align Qwen3-32B using RLBFF and our Reward Model, to match or exceed the performance of o3-mini and DeepSeek R1 on general alignment benchmarks of MT-Bench, WildBench, and Arena Hard v2 (at <5% of the inference cost).
Principle 기반 Scalar 혹은 Reasoning Generative RM을 구축.
Building principle-based scalar or reasoning generative RM.
#reward-model #rl #reasoning
Building principle-based scalar or reasoning generative RMs.
Expanding Reasoning Potential in Foundation Model by Learning Diverse Chains of Thought Patterns
(Xuemiao Zhang, Can Ren, Chengying Tu, Rongxiang Weng, Shuo Wang, Hongfei Yan, Jingang Wang, Xunliang Cai)
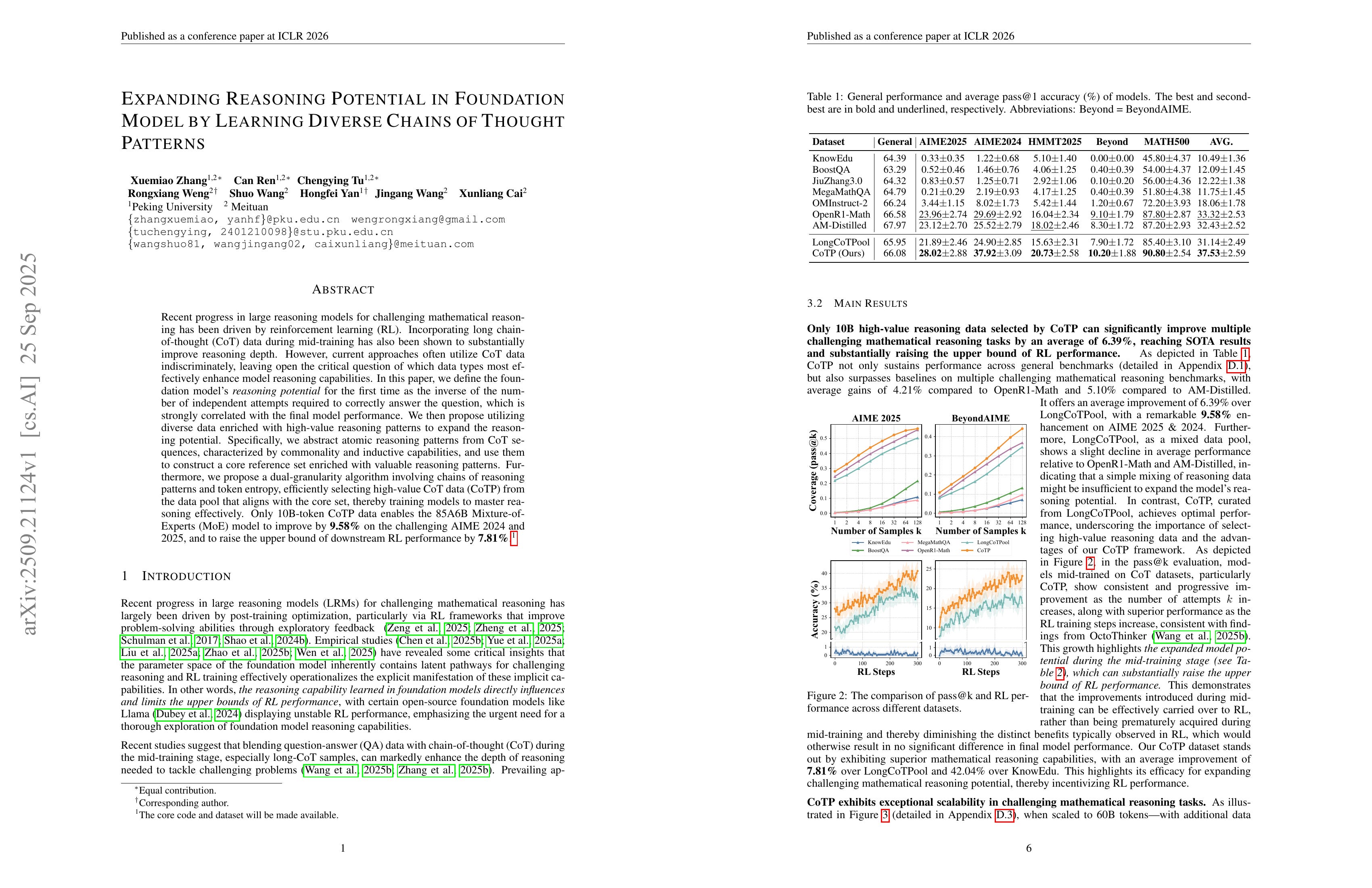
Recent progress in large reasoning models for challenging mathematical reasoning has been driven by reinforcement learning (RL). Incorporating long chain-of-thought (CoT) data during mid-training has also been shown to substantially improve reasoning depth. However, current approaches often utilize CoT data indiscriminately, leaving open the critical question of which data types most effectively enhance model reasoning capabilities. In this paper, we define the foundation model’s reasoning potential for the first time as the inverse of the number of independent attempts required to correctly answer the question, which is strongly correlated with the final model performance. We then propose utilizing diverse data enriched with high-value reasoning patterns to expand the reasoning potential. Specifically, we abstract atomic reasoning patterns from CoT sequences, characterized by commonality and inductive capabilities, and use them to construct a core reference set enriched with valuable reasoning patterns. Furthermore, we propose a dual-granularity algorithm involving chains of reasoning patterns and token entropy, efficiently selecting high-value CoT data (CoTP) from the data pool that aligns with the core set, thereby training models to master reasoning effectively. Only 10B-token CoTP data enables the 85A6B Mixture-of-Experts (MoE) model to improve by 9.58% on the challenging AIME 2024 and 2025, and to raise the upper bound of downstream RL performance by 7.81%.
코어셋과 비슷한 샘플을 찾는 것으로 미드트레이닝에 사용할 데이터를 선택. 유사도는 추론 패턴과 엔트로피에 대한 DTW로 측정 (!). 이전의 Instruction 데이터 선택과 비슷한 문제일 수 있지만 문제를 이후 RL에 도움이 되는 데이터를 선정하는 것으로 간주한다면 좀 더 흥미로운 문제가 될지도.
Selecting data for mid-training by finding similar samples to a chosen core set, measured by DTW (!) on reasoning patterns and entropy. This could be similar to previous instruction data selection problems, but if formulated as selecting samples that are beneficial for later RL training, it could be more interesting.
#rl #reasoning #mid-training
Selecting data for mid-training by finding samples similar to a chosen core set, with similarity measured by DTW (!) on reasoning patterns and entropy. This could be similar to previous instruction data selection problems, but if we frame the problem as selecting data that will be beneficial for subsequent RL training, it could become a more interesting problem.
CE-GPPO: Controlling Entropy via Gradient-Preserving Clipping Policy Optimization in Reinforcement Learning
(Zhenpeng Su, Leiyu Pan, Minxuan Lv, Yuntao Li, Wenping Hu, Fuzheng Zhang, Kun Gai, Guorui Zhou)
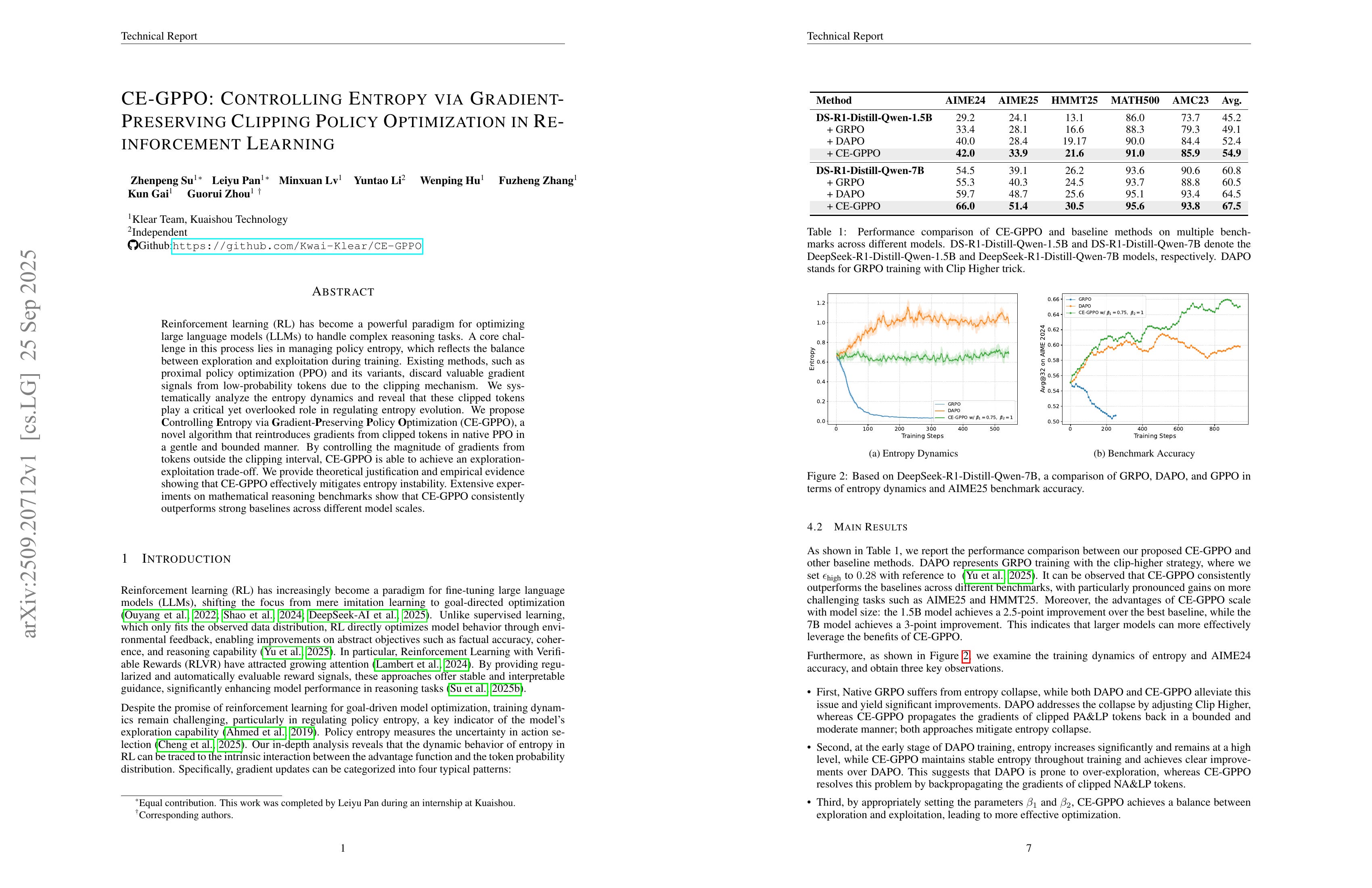
Reinforcement learning (RL) has become a powerful paradigm for optimizing large language models (LLMs) to handle complex reasoning tasks. A core challenge in this process lies in managing policy entropy, which reflects the balance between exploration and exploitation during training. Existing methods, such as proximal policy optimization (PPO) and its variants, discard valuable gradient signals from low-probability tokens due to the clipping mechanism. We systematically analyze the entropy dynamics and reveal that these clipped tokens play a critical yet overlooked role in regulating entropy evolution. We propose Controlling Entropy via Gradient-Preserving Policy Optimization (CE-GPPO), a novel algorithm that reintroduces gradients from clipped tokens in native PPO in a gentle and bounded manner. By controlling the magnitude of gradients from tokens outside the clipping interval, CE-GPPO is able to achieve an exploration-exploitation trade-off. We provide theoretical justification and empirical evidence showing that CE-GPPO effectively mitigates entropy instability. Extensive experiments on mathematical reasoning benchmarks show that CE-GPPO consistently outperforms strong baselines across different model scales.
Loss를 클리핑하는 대신 클리핑 구간 바깥의 그래디언트를 적당히 조절해서 사용하는 것으로 엔트로피의 거동을 개선한다는 아이디어.
Instead of just clipping the loss, incorporate the attenuated gradient from outside of the clipping interval to enhance entropy dynamics.
#rl #reasoning
Verification Limits Code LLM Training
(Srishti Gureja, Elena Tommasone, Jingyi He, Sara Hooker, Matthias Gallé, Marzieh Fadaee)

Large language models for code generation increasingly rely on synthetic data, where both problem solutions and verification tests are generated by models. While this enables scalable data creation, it introduces a previously unexplored bottleneck: the verification ceiling, in which the quality and diversity of training data are fundamentally constrained by the capabilities of synthetic verifiers. In this work, we systematically study how verification design and strategies influence model performance. We investigate (i) what we verify by analyzing the impact of test complexity and quantity: richer test suites improve code generation capabilities (on average +3 pass@1), while quantity alone yields diminishing returns, (ii) how we verify by exploring relaxed pass thresholds: rigid 100% pass criteria can be overly restrictive. By allowing for relaxed thresholds or incorporating LLM-based soft verification, we can recover valuable training data, leading to a 2-4 point improvement in pass@1 performance. However, this benefit is contingent upon the strength and diversity of the test cases used, and (iii) why verification remains necessary through controlled comparisons of formally correct versus incorrect solutions and human evaluation: retaining diverse correct solutions per problem yields consistent generalization gains. Our results show that Verification as currently practiced is too rigid, filtering out valuable diversity. But it cannot be discarded, only recalibrated. By combining calibrated verification with diverse, challenging problem-solution pairs, we outline a path to break the verification ceiling and unlock stronger code generation models.
샘플을 유닛 테스트를 사용해 선택하거나 보상을 부여한다면 유닛 테스트 자체가 샘플의 퀄리티를 충분히 반영할 정도로 정교해야 할 것. 이 연구는 합성한 유닛 테스트로 필터링해서 SFT를 하는 것을 주로 다루기는 함. 다만 이 문제는 유닛 테스트를 수작업으로 만든다고 하더라도 비슷하게 존재하리라고 생각. (그리고 그런 경우에도 합성한 유닛 테스트로 보강하는 것을 고려할 수도.)
If we choose or reward samples using unit tests then unit tests themselves should be delicate enough to reflect the quality of samples. This study mainly deals with SFT using filtered samples with synthetic unit tests. Though I think this problem would remain even when we hand-make unit tests. (And we may want to supplement it with synthesized ones.)
#synthetic-data #reward-model