



2024년 8월 8일

FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention
(Team PyTorch)
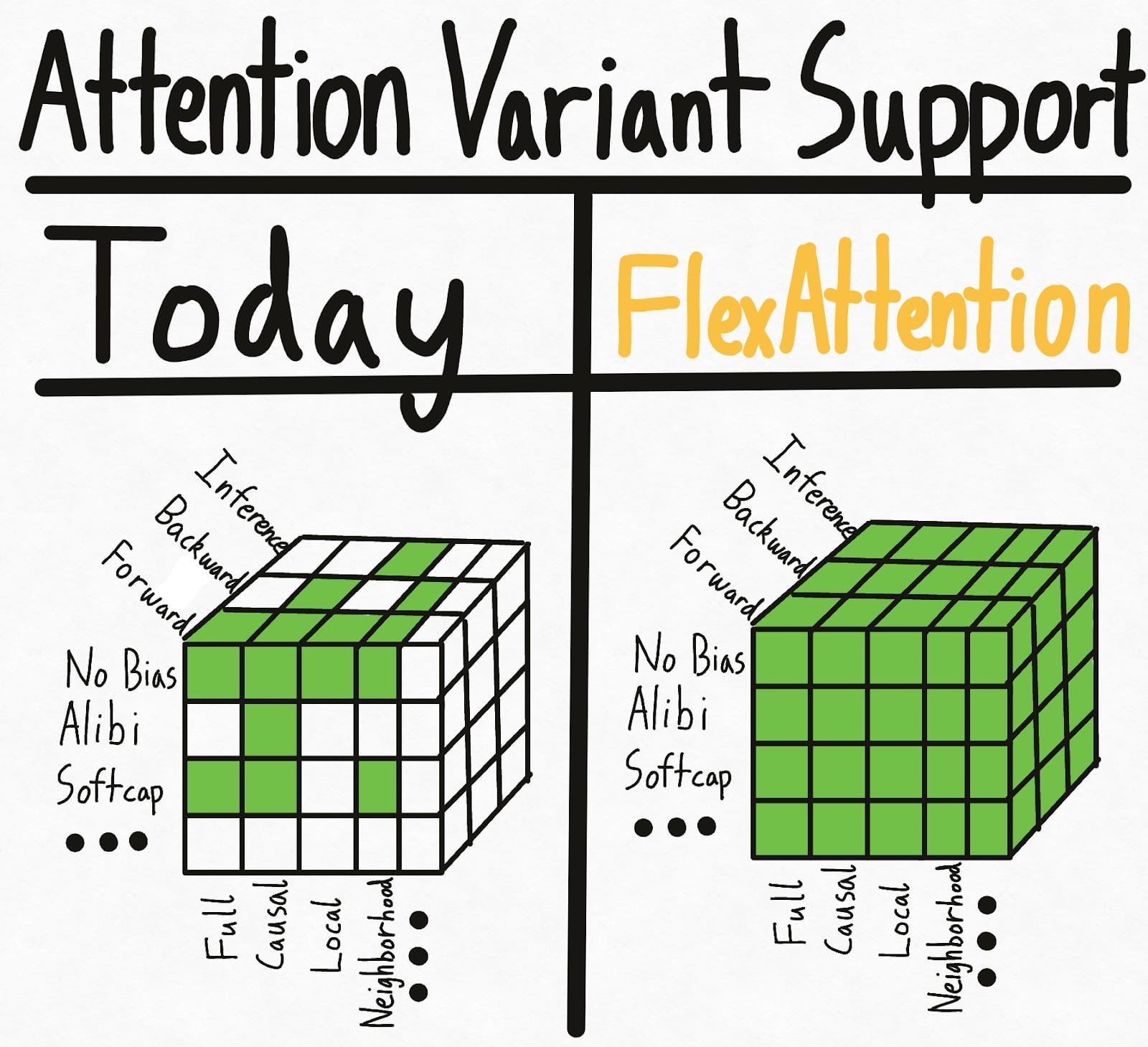
이야기가 나오던 FlexAttention이 등장했네요. Attention Score를 변형하거나 Masking 할 수 있는 방법을 제공하는 것으로 수많은 Attention의 변형을 지원할 수 있고, 이를 torch.compile로 결합해 효율적인 Attention 구현으로 만들어낼 수 있다는 것입니다.
이전에 까다로웠던 Attention 패턴들, Prefix LM이나 Document Masking 등을 모두 간단하게 지원할 수 있네요. Flash Attention에서 지원이 되어야 한다는 제약이 사라졌으니 이제 훨씬 다양한 시도들을 해볼 수 있게 되지 않을까 싶습니다.
#efficiency
Optimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation
(Weiqi Feng, Yangrui Chen, Shaoyu Wang, Yanghua Peng, Haibin Lin, Minlan Yu)

Multimodal large language models (MLLMs) have extended the success of large language models (LLMs) to multiple data types, such as image, text and audio, achieving significant performance in various domains, including multimodal translation, visual question answering and content generation. Nonetheless, existing systems are inefficient to train MLLMs due to substantial GPU bubbles caused by the heterogeneous modality models and complex data dependencies in 3D parallelism. This paper proposes Optimus, a distributed MLLM training system that reduces end-to-end MLLM training time. Optimus is based on our principled analysis that scheduling the encoder computation within the LLM bubbles can reduce bubbles in MLLM training. To make scheduling encoder computation possible for all GPUs, Optimus searches the separate parallel plans for encoder and LLM, and adopts a bubble scheduling algorithm to enable exploiting LLM bubbles without breaking the original data dependencies in the MLLM model architecture. We further decompose encoder layer computation into a series of kernels, and analyze the common bubble pattern of 3D parallelism to carefully optimize the sub-millisecond bubble scheduling, minimizing the overall training time. Our experiments in a production cluster show that Optimus accelerates MLLM training by 20.5%-21.3% with ViT-22B and GPT-175B model over 3072 GPUs compared to baselines.
인코더를 사용하는 Multimodal LLM에 대한 학습 효율화. 인코더를 사용하는 경우 인코더의 연산 특성은 LLM과는 많이 다르죠. 여기서는 Multimodal LLM 학습에서 발생하는 버블이 대부분 LLM 쪽에서 발생하니 이 버블 속에 인코더를 끼워넣자는 아이디어입니다.
#efficient-training #parallelism
PackMamba: Efficient Processing of Variable-Length Sequences in Mamba training
(Haoran Xu, Ziqian Liu, Rong Fu, Zhongling Su, Zerui Wang, Zheng Cai, Zhilin Pei, Xingcheng Zhang)

With the evolution of large language models, traditional Transformer models become computationally demanding for lengthy sequences due to the quadratic growth in computation with respect to the sequence length. Mamba, emerging as a groundbreaking architecture in the field of generative AI, demonstrates remarkable proficiency in handling elongated sequences with reduced computational and memory complexity. Nevertheless, the existing training framework of Mamba presents inefficiency with variable-length sequence inputs. Either single-sequence training results in low GPU utilization, or batched processing of variable-length sequences to a maximum length incurs considerable memory and computational overhead. To address this problem, we analyze the performance of bottleneck operators in Mamba under diverse tensor shapes and proposed PackMamba, a high-throughput Mamba that efficiently handles variable-length sequences. Diving deep into state-space models (SSMs), we modify the parallel operators to avoid passing information between individual sequences while maintaining high performance. Experimental results on an NVIDIA A100 GPU demonstrate throughput exceeding the baseline single-sequence processing scheme: 3.06x speedup on the 1.4B model and 2.62x on the 2.8B model.
Mamba를 Packing된 시퀀스에 대해 학습하면서 이전 시퀀스의 상태로 이후 시퀀스가 영향을 받는 것을 막으려는 방법. Mamba 같은 경우 Packing에서 이전 시퀀스의 영향을 막는 것이 트랜스포머 보다 더 중요할 수 있다는 결과가 있었죠. (https://arxiv.org/abs/2406.07887)
State Space Model를 사용해야 하는가라는 문제 자체에 대해서는 최근 트랜스포머에서 Attention 캐시를 줄일 수 있는 방법들이 많이 등장하면서 이런 캐시 효율성 차원에서의 State Space Model의 장점은 바랬다는 느낌이 있습니다. 이전에도 그랬지만 State Space Model이 가지는 트랜스포머와는 다른 Inductive Bias의 측면이 더 흥미로울 것일 듯 합니다.
#efficient-training #state-space-model