



2024년 8월 30일

Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems
(Tian Ye, Zicheng Xu, Yuanzhi Li, Zeyuan Allen-Zhu)

Language models have demonstrated remarkable performance in solving reasoning tasks; however, even the strongest models still occasionally make reasoning mistakes. Recently, there has been active research aimed at improving reasoning accuracy, particularly by using pretrained language models to "self-correct" their mistakes via multi-round prompting. In this paper, we follow this line of work but focus on understanding the usefulness of incorporating "error-correction" data directly into the pretraining stage. This data consists of erroneous solution steps immediately followed by their corrections. Using a synthetic math dataset, we show promising results: this type of pretrain data can help language models achieve higher reasoning accuracy directly (i.e., through simple auto-regression, without multi-round prompting) compared to pretraining on the same amount of error-free data. We also delve into many details, such as (1) how this approach differs from beam search, (2) how such data can be prepared, (3) whether masking is needed on the erroneous tokens, (4) the amount of error required, (5) whether such data can be deferred to the fine-tuning stage, and many others.
GSM 스타일의 합성 데이터로 LLM의 추론 과정을 분석했습니다. 1. 모델은 보통 실수를 했다면 그 사실을 인식할 수 있다는 것 2. 프리트레이닝에 이렇게 실수하고 재시도하는 데이터를 주입하면 성능을 높일 수 있다는 것 3. 재시도하는 데이터는 부정확하더라도 의미가 있을 수 있다는 것 정도가 요점이겠네요.
반복해서 나오는 이야기인 텍스트에는 사고 과정이 포함되어 있지 않다는 문제의 연장선에 있는 듯 합니다. 문장과 문장 사이를 연결하는 사고 과정에는 가능한 다른 문장을 생각해보았다가 별로였다면 버리는 종류의 과정 또한 포함되어 있겠죠. 그것을 채우는 것이 다음 단계의 LLM에는 중요하리라고 봅니다.
혹은 Lean 같은 Verifier를 사용하는 경우에는 직접적으로 실수를 시뮬레이션하는 것도 충분히 가능하겠네요.
#llm #reasoning #synthetic-data
Qwen2-VL: To See the World More Clearly
(Qwen Team)
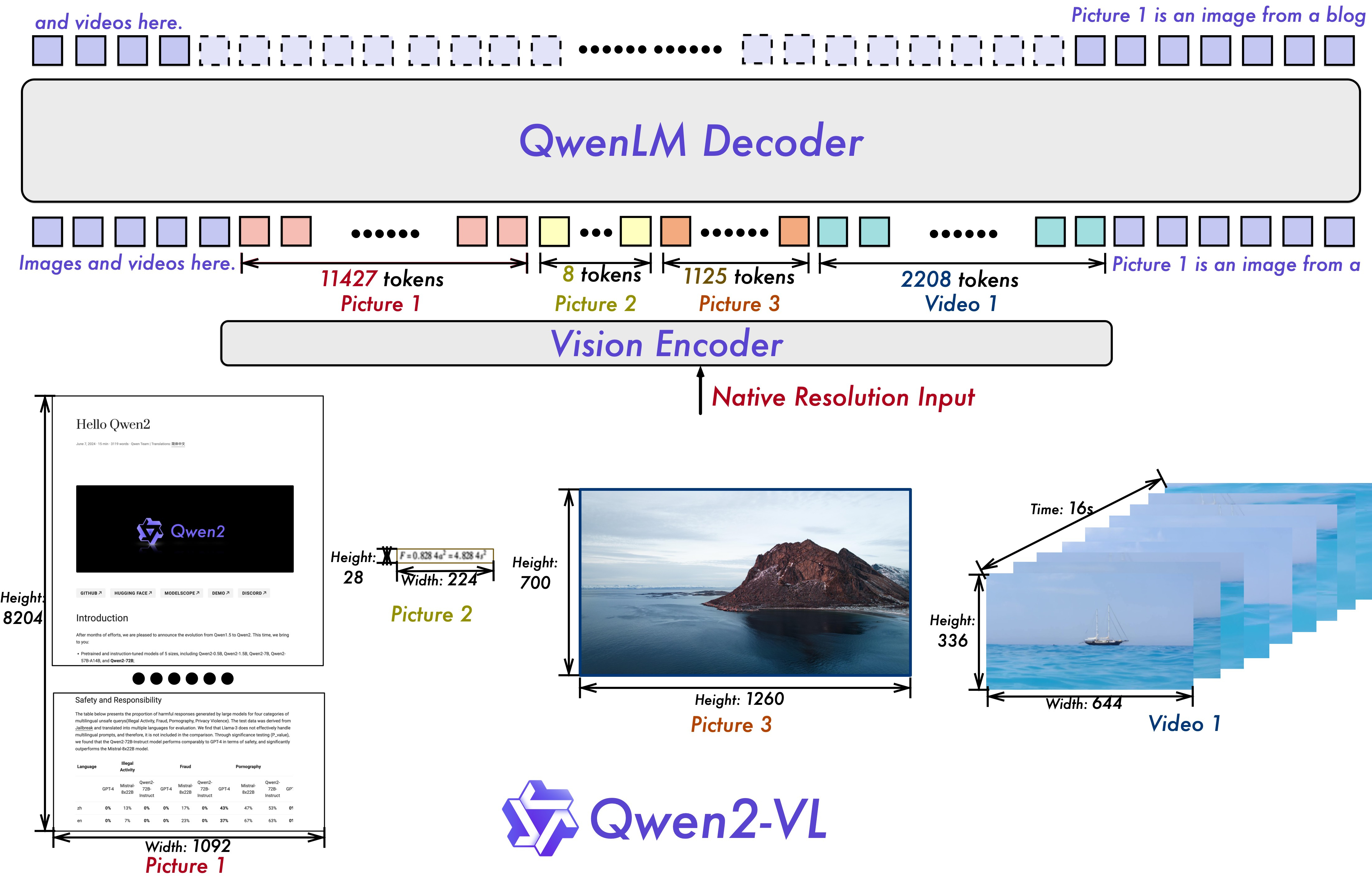
Qwen2-VL이 나왔군요. 비디오 입력을 지원하고 가변 해상도 이미지에 따라 서로 다른 길이의 토큰을 입력으로 쓸 수 있게 했군요. RoPE를 사용하면서 이미지 높이/너비 그리고 시간축으로 쪼개서 적용했다고.
#vision-language #video-language
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
(Hritik Bansal, Arian Hosseini, Rishabh Agarwal, Vinh Q. Tran, Mehran Kazemi)

Training on high-quality synthetic data from strong language models (LMs) is a common strategy to improve the reasoning performance of LMs. In this work, we revisit whether this strategy is compute-optimal under a fixed inference budget (e.g., FLOPs). To do so, we investigate the trade-offs between generating synthetic data using a stronger but more expensive (SE) model versus a weaker but cheaper (WC) model. We evaluate the generated data across three key metrics: coverage, diversity, and false positive rate, and show that the data from WC models may have higher coverage and diversity, but also exhibit higher false positive rates. We then finetune LMs on data from SE and WC models in different settings: knowledge distillation, self-improvement, and a novel weak-to-strong improvement setup where a weaker LM teaches reasoning to a stronger LM. Our findings reveal that models finetuned on WC-generated data consistently outperform those trained on SE-generated data across multiple benchmarks and multiple choices of WC and SE models. These results challenge the prevailing practice of relying on SE models for synthetic data generation, suggesting that WC may be the compute-optimal approach for training advanced LM reasoners.
작은 모델로 더 많이 생성한 데이터가 큰 모델로 조금 생성한 데이터보다 큰 모델에 대한 튜닝에 대해서도 더 유리할 수 있다는 주장. 물론 이는 최종 답을 사용해서 데이터를 필터링 할 수 있었던 덕이 있었겠죠.
큰 모델의 다양성 문제 때문에 큰 모델로 생성한 데이터가 문제가 되는 경우도 있는데 (https://arxiv.org/abs/2310.13798) 이쪽은 포스트트레이닝을 거친 모델이니 좀 다르긴 합니다.
#synthetic-data
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
(Shengpeng Ji, Ziyue Jiang, Xize Cheng, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Ruiqi Li, Ziang Zhang, Xiaoda Yang, Rongjie Huang, Yidi Jiang, Qian Chen, Siqi Zheng, Wen Wang, Zhou Zhao)

Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.
오디오 토크나이저. 오디오 1초를 75 토큰으로 변환합니다. 가장 주요한 것은 Vocabulary 크기를 2^12까지 높인 것일 것 같네요. 2^12 이상에서는 Utilization이 낮아지고 있는데 이를 개선하면 좀 더 나은 모델을 만들 수 있지 않을까 싶기도 합니다.
이미지와 마찬가지로 오디오 또한 입출력을 어떤 형태로 해야 하는가가 문제가 되겠군요. Discrete Token을 사용하면서 발생하는 문제는 이미지보다는 나을 것 같기도 하네요.
#audio #vq
Law of Vision Representation in MLLMs
(Shijia Yang, Bohan Zhai, Quanzeng You, Jianbo Yuan, Hongxia Yang, Chenfeng Xu)

We present the "Law of Vision Representation" in multimodal large language models (MLLMs). It reveals a strong correlation between the combination of cross-modal alignment, correspondence in vision representation, and MLLM performance. We quantify the two factors using the cross-modal Alignment and Correspondence score (AC score). Through extensive experiments involving thirteen different vision representation settings and evaluations across eight benchmarks, we find that the AC score is linearly correlated to model performance. By leveraging this relationship, we are able to identify and train the optimal vision representation only, which does not require finetuning the language model every time, resulting in a 99.7% reduction in computational cost.
Vision Language 모델의 성능은 이미지 인코더의 출력 Feature가 언어와 얼마나 잘 정렬되어 있는가, 그리고 이미지에 대한 Correspondence를 추출하기 용이한 형태인가로 계산 가능하다는 주장. 물론 이 둘을 어떻게 측정할 것인가가 문제이긴 합니다.
언어와 잘 정렬되어 있으면서 Semantic한 디테일까지 잘 포착한다면 충분히 좋은 이미지 인코더가 되긴 하겠죠.
#vision-language
VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
(Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, Mike Zheng Shou)

A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens "skipping layers" rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately \textasciitilde42% time and \textasciitilde30% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.
비디오에 대해서 Mixture of Depths를 적용해봤군요. 비디오는 중복이 많을 테니 더 잘 맞을 것 같기도 합니다. 흥미롭게도 Mixture of Depths는 멀티모달 쪽에서 결과가 먼저 나오네요. (https://arxiv.org/abs/2407.21770) 텍스트에서 결과를 내는 것에는 비용이 많이 들어서겠지만요.
#video-language #moe