



2024년 8월 28일

Generative Verifiers: Reward Modeling as Next-Token Prediction
(Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, Rishabh Agarwal)
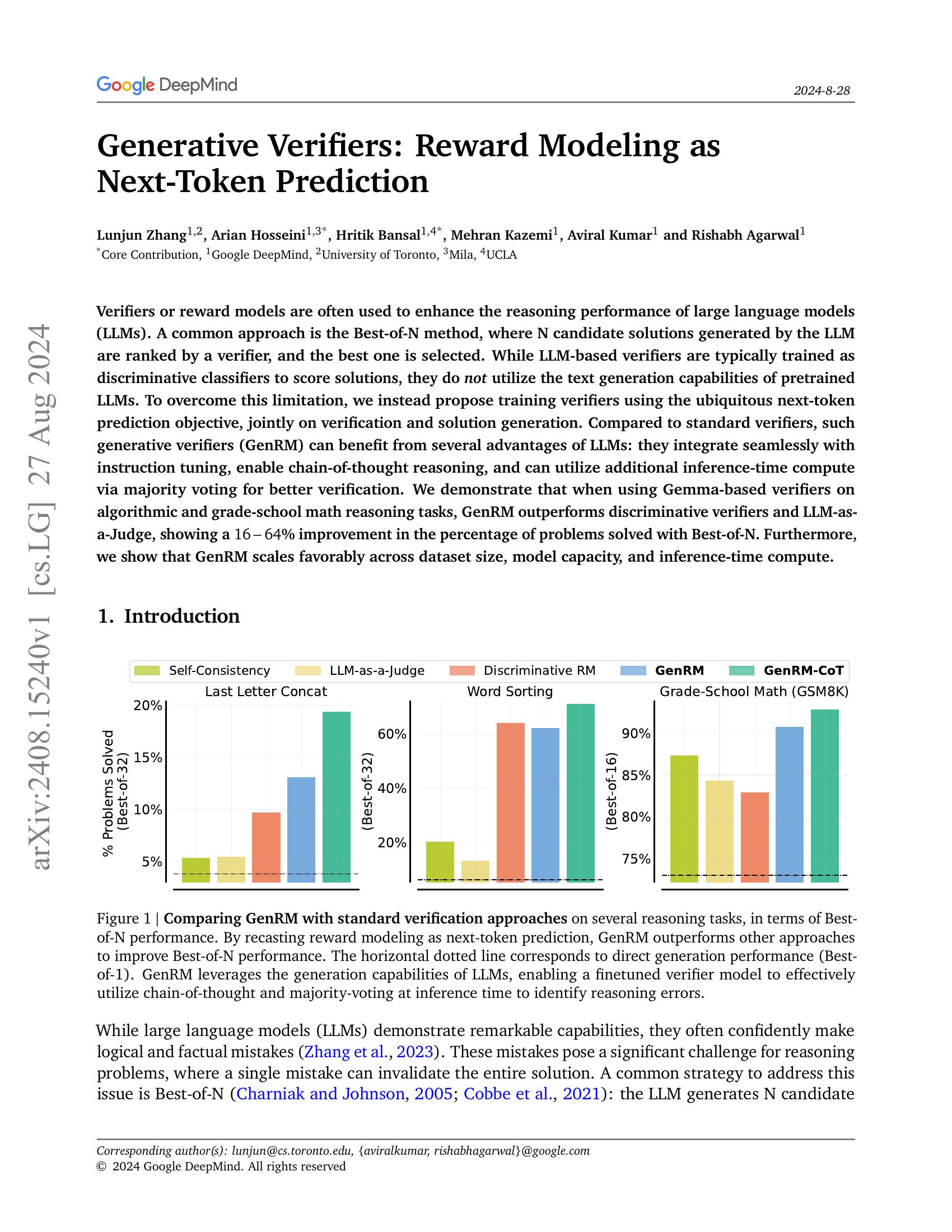
Verifiers or reward models are often used to enhance the reasoning performance of large language models (LLMs). A common approach is the Best-of-N method, where N candidate solutions generated by the LLM are ranked by a verifier, and the best one is selected. While LLM-based verifiers are typically trained as discriminative classifiers to score solutions, they do not utilize the text generation capabilities of pretrained LLMs. To overcome this limitation, we instead propose training verifiers using the ubiquitous next-token prediction objective, jointly on verification and solution generation. Compared to standard verifiers, such generative verifiers (GenRM) can benefit from several advantages of LLMs: they integrate seamlessly with instruction tuning, enable chain-of-thought reasoning, and can utilize additional inference-time compute via majority voting for better verification. We demonstrate that when using Gemma-based verifiers on algorithmic and grade-school math reasoning tasks, GenRM outperforms discriminative verifiers and LLM-as-a-Judge, showing a 16-64% improvement in the percentage of problems solved with Best-of-N. Furthermore, we show that GenRM scales favorably across dataset size, model capacity, and inference-time compute.
Verifier 학습에 Verification에 더해 정답을 생성하도록 학습하면 Verification 성능이 높아진다는 결과. 추가적으로 Verification에 CoT를 하도록 학습할 수도 있습니다. 반대로 Generator도 Verification을 하도록 학습시키면 성능이 향상된다고 하네요.
얼마 전 Critique을 생성하도록 학습시킨 Reward Model이 나왔었죠. (https://arxiv.org/abs/2408.11791) 이쪽은 Verifier이고 Critique이 아니라 정답 생성이지만 비슷한 점은 있는 듯 하네요.
#search
Diffusion Models Are Real-Time Game Engines
(Dani Valevski, Yaniv Leviathan, Moab Arar, Shlomi Fruchter)

We present GameNGen, the first game engine powered entirely by a neural model that enables real-time interaction with a complex environment over long trajectories at high quality. GameNGen can interactively simulate the classic game DOOM at over 20 frames per second on a single TPU. Next frame prediction achieves a PSNR of 29.4, comparable to lossy JPEG compression. Human raters are only slightly better than random chance at distinguishing short clips of the game from clips of the simulation. GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the training sessions are recorded, and (2) a diffusion model is trained to produce the next frame, conditioned on the sequence of past frames and actions. Conditioning augmentations enable stable auto-regressive generation over long trajectories.
https://gamengen.github.io/
이제 Diffusion에서 DOOM이 돌아가는군요. 게임을 하는 에이전트로 수집한 데이터로 Diffusion을 학습시키는 구조입니다.
#diffusion #rl
BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
(Guosheng Dong, Da Pan, Yiding Sun, Shusen Zhang, Zheng Liang, Xin Wu, Yanjun Shen, Fan Yang, Haoze Sun, Tianpeng Li, Mingan Lin, Jianhua Xu, Yufan Zhang, Xiaonan Nie, Lei Su, Bingning Wang, Wentao Zhang, Jiaxin Mao, Zenan Zhou, Weipeng Chen)

The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.
Baichuan 쪽에서 자신들의 프리트레이닝 데이터셋 구축 파이프라인에 대한 디테일을 공개했군요. 재미있는 점들은,
Global Deduplication. FineWeb에서는 Global Deduplication이 별로였다고 하지만 Global Deduplication을 하는 사례는 계속 나오네요. Llama 3도 Global Deduplication을 했었죠.
사람이 직접 어노테이션한 퀄리티 필터. 이것도 가끔 등장하는군요. (https://arxiv.org/abs/2403.17297) 사람이 판단하기에 좋은 데이터가 정말로 좋은 데이터인지는 다른 문제이긴 하지만요. (https://arxiv.org/abs/2406.11794)
서적이나 논문 데이터를 적지 않은 분량 수집 및 사용. 대략 750B 정도를 학습에 썼네요.
#corpus #pretraining
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
(Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao)

Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment. We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources. The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks. Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently. Our top-performing model, distilled from Llama3-8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best instruction-tuned linear RNN model.
Transformer에서 Mamba로 Distillation. 얼마 전 나온 논문과 비슷한데 (https://arxiv.org/abs/2408.10189) 이쪽은 아예 Mamba의 Weight를 Attention Weight에서 가져왔군요.
#distillation #state-space-model
Instruct-SkillMix: A Powerful Pipeline for LLM Instruction Tuning
(Simran Kaur, Simon Park, Anirudh Goyal, Sanjeev Arora)

We introduce Instruct-SkillMix, an automated approach for creating diverse, high quality SFT data. The Instruct-SkillMix pipeline involves two stages, each leveraging an existing powerful LLM: (1) Skill extraction: uses the LLM to extract core "skills" for instruction-following, either from existing datasets, or by directly prompting the model; (2) Data generation: uses the powerful LLM to generate (instruction, response) data that exhibit a randomly chosen pair of these skills. Here, the use of random skill combinations promotes diversity and difficulty. Vanilla SFT (i.e., no PPO, DPO, or RL methods) on data generated from Instruct-SkillMix leads to strong gains on instruction following benchmarks such as AlpacaEval 2.0, MT-Bench, and WildBench. With just $4$K examples, LLaMA-3-8B-Base achieves 42.76% length-controlled win rate on AlpacaEval 2.0. To our knowledge, this achieves state-of-the-art performance among all models that have only undergone SFT (no RL methods) and competes with proprietary models such as Claude 3 Opus and LLaMA-3.1-405B-Instruct. Ablation studies also suggest plausible reasons for why creating open instruction-tuning datasets via naive crowd-sourcing has proved difficult. Introducing low quality answers ("shirkers") in 20%20% of Instruct-SkillMix examples causes performance to plummet, sometimes catastrophically. The Instruct-SkillMix pipeline is flexible and is adaptable to other settings.
Skill 기반으로 평가하는 방법을 개발한 배경 위에서 (https://arxiv.org/abs/2310.17567) Skill을 섞어서 Instruction을 생성하는 방법을 고안했군요. Llama 3가 시사한 것처럼 프롬프트를 증폭하는 방법은 Alignment에서 필수적인 부분이 되긴 했네요.
#alignment #instruction-tuning