



DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
(Huajian Xin, Z.Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z.F. Wu, Fuli Luo, Chong Ruan)
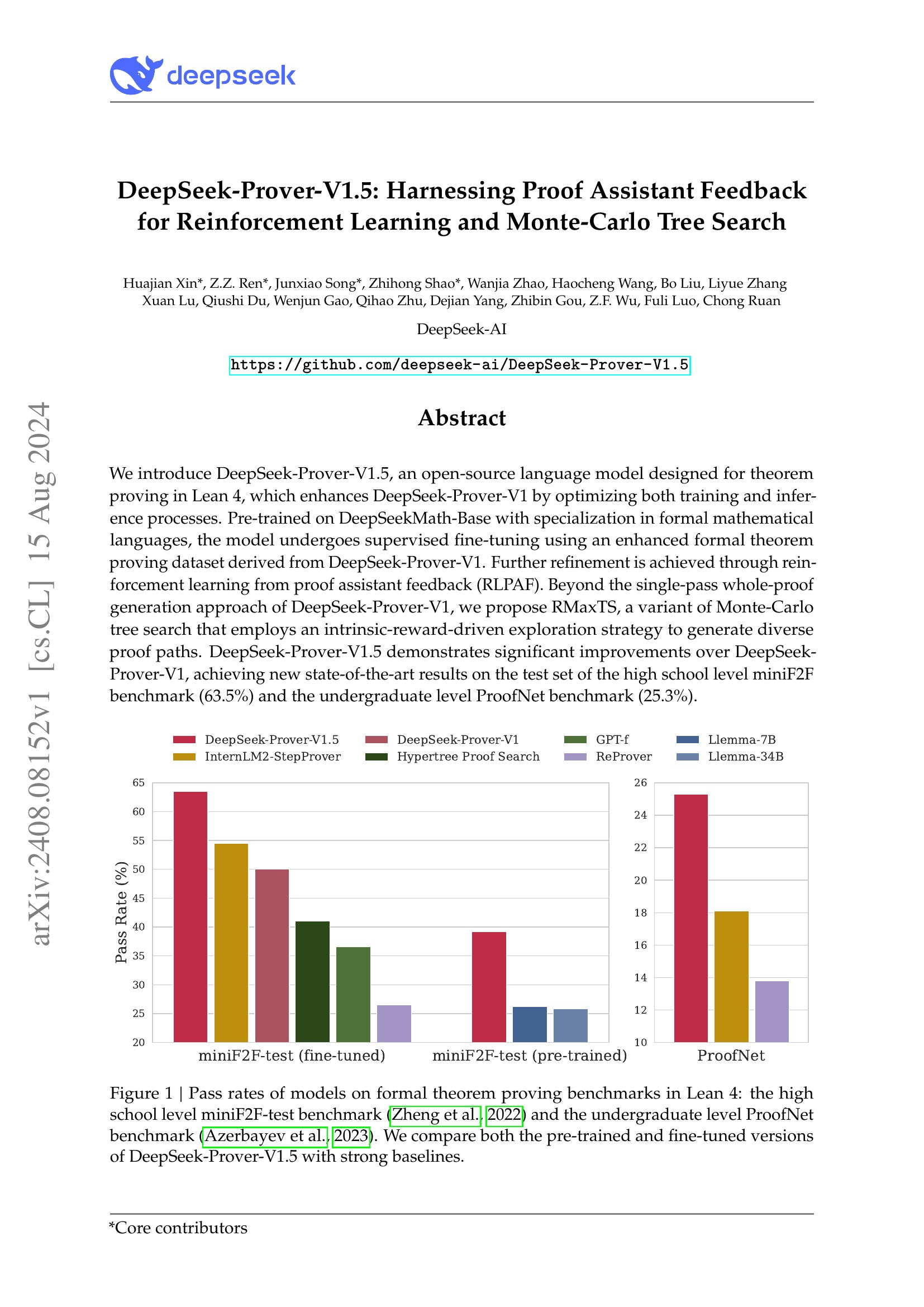
We introduce DeepSeek-Prover-V1.5, an open-source language model designed for theorem proving in Lean 4, which enhances DeepSeek-Prover-V1 by optimizing both training and inference processes. Pre-trained on DeepSeekMath-Base with specialization in formal mathematical languages, the model undergoes supervised fine-tuning using an enhanced formal theorem proving dataset derived from DeepSeek-Prover-V1. Further refinement is achieved through reinforcement learning from proof assistant feedback (RLPAF). Beyond the single-pass whole-proof generation approach of DeepSeek-Prover-V1, we propose RMaxTS, a variant of Monte-Carlo tree search that employs an intrinsic-reward-driven exploration strategy to generate diverse proof paths. DeepSeek-Prover-V1.5 demonstrates significant improvements over DeepSeek-Prover-V1, achieving new state-of-the-art results on the test set of the high school level miniF2F benchmark (63.5%) and the undergraduate level ProofNet benchmark (25.3%).
DeepSeek Prover의 후속 모델. (https://arxiv.org/abs/2405.14333) Proof Assistant 데이터들에 대해 Further Pretraining 한 다음 Lean 4에 대해 SFT. 여기에서 Lean-STaR 식으로 Lean 코드 전에 자연어 Chain of Thought를 달아주는 작업을 진행하고 (https://arxiv.org/abs/2407.10040) Tactic의 상태를 예측하도록 하는 부분도 추가했습니다.
그 다음으로 GRPO와 Proof Assistant의 Verification을 사용한 RL을 수행했네요. 그리고 그 위에 Intrinsic Reward를 사용한 MCTS. 굉장한 프로젝트네요. DeepSeek이 늘 그랬듯.
#math #search
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
(Ruihang Li, Yixuan Wei, Miaosen Zhang, Nenghai Yu, Han Hu, Houwen Peng)

High-quality data is crucial for the pre-training performance of large language models. Unfortunately, existing quality filtering methods rely on a known high-quality dataset as reference, which can introduce potential bias and compromise diversity. In this paper, we propose ScalingFilter, a novel approach that evaluates text quality based on the perplexity difference between two language models trained on the same data, thereby eliminating the influence of the reference dataset in the filtering process. An theoretical analysis shows that ScalingFilter is equivalent to an inverse utilization of scaling laws. Through training models with 1.3B parameters on the same data source processed by various quality filters, we find ScalingFilter can improve zero-shot performance of pre-trained models in downstream tasks. To assess the bias introduced by quality filtering, we introduce semantic diversity, a metric of utilizing text embedding models for semantic representations. Extensive experiments reveal that semantic diversity is a reliable indicator of dataset diversity, and ScalingFilter achieves an optimal balance between downstream performance and semantic diversity.
DeepSeek LLM의 데이터 퀄리티가 향상될수록 Scaling Law에서 모델 크기에 대한 Exponent가 높아진다는 아이디어를 데이터 퀄리티 측정에 연결. 작은 모델과 큰 모델을 같은 데이터에 대해 학습시킨 다음 이 두 모델의 Perplexity의 비율이 퀄리티의 척도가 된다는 아이디어입니다.
이를 통해 데이터셋을 필터링하는데 사용합니다. 어떤 데이터에 대해 LM을 학습하는가가 필터링 성능에 영향을 미친다는 것을 고려하면 데이터셋의 유사도라는 측면도 있을 듯 한데 모델 크기에 따른 비율 차이를 고려한다는 것을 생각하면 Learnability와의 관계도 있을 듯 하네요. (https://arxiv.org/abs/2206.07137) 생각해볼만한 방법인 듯 합니다.
#scaling-law #corpus
BAM! Just Like That: Simple and Efficient Parameter Upcycling for Mixture of Experts
(Qizhen Zhang, Nikolas Gritsch, Dwaraknath Gnaneshwar, Simon Guo, David Cairuz, Bharat Venkitesh, Jakob Foerster, Phil Blunsom, Sebastian Ruder, Ahmet Ustun, Acyr Locatelli)

The Mixture of Experts (MoE) framework has become a popular architecture for large language models due to its superior performance over dense models. However, training MoEs from scratch in a large-scale regime is prohibitively expensive. Existing methods mitigate this by pre-training multiple dense expert models independently and using them to initialize an MoE. This is done by using experts' feed-forward network (FFN) to initialize the MoE's experts while merging other parameters. However, this method limits the reuse of dense model parameters to only the FFN layers, thereby constraining the advantages when "upcycling" these models into MoEs. We propose BAM (Branch-Attend-Mix), a simple yet effective method that addresses this shortcoming. BAM makes full use of specialized dense models by not only using their FFN to initialize the MoE layers but also leveraging experts' attention parameters fully by initializing them into a soft-variant of Mixture of Attention (MoA) layers. We explore two methods for upcycling attention parameters: 1) initializing separate attention experts from dense models including all attention parameters for the best model performance; and 2) sharing key and value parameters across all experts to facilitate for better inference efficiency. To further improve efficiency, we adopt a parallel attention transformer architecture to MoEs, which allows the attention experts and FFN experts to be computed concurrently. Our experiments on seed models ranging from 590 million to 2 billion parameters demonstrate that BAM surpasses baselines in both perplexity and downstream task performance, within the same computational and data constraints.
Branch-Train-Mix스러운 (https://arxiv.org/abs/2403.07816) 각 도메인에 대해 모델을 학습한 다음 Sparse Upcycling으로 결합하는 방법. 여기서는 FFN 뿐만 아니라 Attention을 결합하는 것이 핵심이네요. 다만 Sparse MoE로 결합하는 것으로는 안 되고 Soft하게 모두 결합해야 한다고 합니다. Mixture of Attention 자체에 대한 연구가 더 필요하지 않을까 하는 생각이 드네요.
#moe
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
(Jiri Hron, Laura Culp, Gamaleldin Elsayed, Rosanne Liu, Ben Adlam, Maxwell Bileschi, Bernd Bohnet, JD Co-Reyes, Noah Fiedel, C. Daniel Freeman, Izzeddin Gur, Kathleen Kenealy, Jaehoon Lee, Peter J. Liu, Gaurav Mishra, Igor Mordatch, Azade Nova, Roman Novak, Aaron Parisi, Jeffrey Pennington, Alex Rizkowsky, Isabelle Simpson, Hanie Sedghi, Jascha Sohl-dickstein, Kevin Swersky, Sharad Vikram, Tris Warkentin, Lechao Xiao, Kelvin Xu, Jasper Snoek, Simon Kornblith)

While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on ≤5≤5% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Knowledge Graph에 대해 학습시켜 LLM의 Hallucination에 대한 Scaling 특성을 연구. 더 큰 모델을 데이터에 대해 (Multi Epoch로) 더 오래 학습시킬수록 Hallucination Rate는 감소합니다. 그렇지만 데이터가 커지면 Hallucination Rate는 증가하네요.
Hallucination 탐지의 경우에는 큰 모델이 Hallucination Rate가 낮은 동시에 Hallucination 탐지도 더 어려워지네요.
#hallucination