



2024년 7월 3일

LiteSearch: Efficacious Tree Search for LLM
(Ante Wang, Linfeng Song, Ye Tian, Baolin Peng, Dian Yu, Haitao Mi, Jinsong Su, Dong Yu)
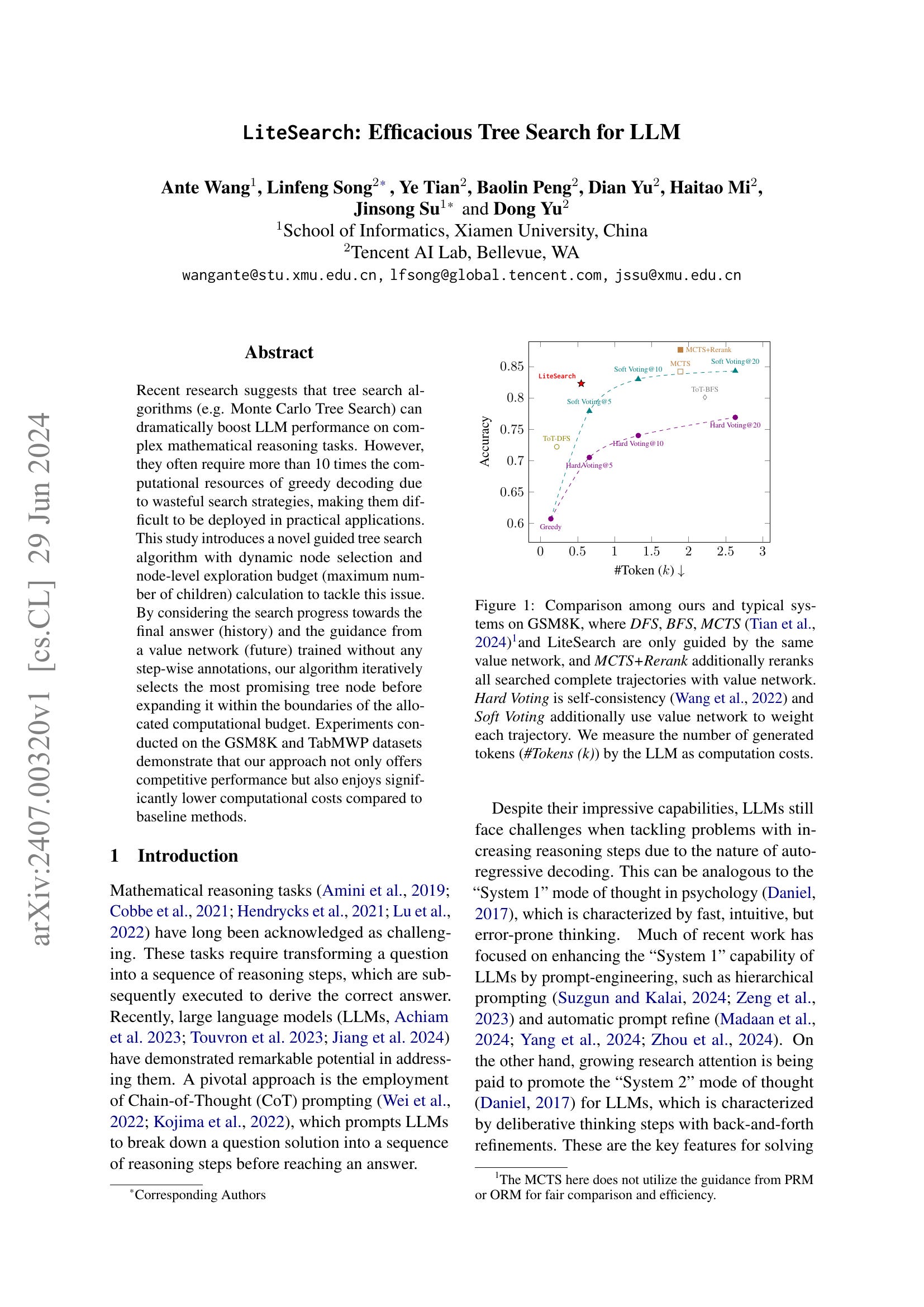
Recent research suggests that tree search algorithms (e.g. Monte Carlo Tree Search) can dramatically boost LLM performance on complex mathematical reasoning tasks. However, they often require more than 10 times the computational resources of greedy decoding due to wasteful search strategies, making them difficult to be deployed in practical applications. This study introduces a novel guided tree search algorithm with dynamic node selection and node-level exploration budget (maximum number of children) calculation to tackle this issue. By considering the search progress towards the final answer (history) and the guidance from a value network (future) trained without any step-wise annotations, our algorithm iteratively selects the most promising tree node before expanding it within the boundaries of the allocated computational budget. Experiments conducted on the GSM8K and TabMWP datasets demonstrate that our approach not only offers competitive performance but also enjoys significantly lower computational costs compared to baseline methods.
트리 서치의 효율화. Value 함수를 사용해 유망한 노드를 선택하고 그 노드를 적당한 수로 확장해 탐색해나가는 방법.
#search
Tree Search for Language Model Agents
(Jing Yu Koh, Stephen McAleer, Daniel Fried, Ruslan Salakhutdinov)

Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation. However, a key limitation remains: LMs, primarily optimized for natural language understanding and generation, struggle with multi-step reasoning, planning, and using environmental feedback when attempting to solve realistic computer tasks. Towards addressing this, we propose an inference-time search algorithm for LM agents to explicitly perform exploration and multi-step planning in interactive web environments. Our approach is a form of best-first tree search that operates within the actual environment space, and is complementary with most existing state-of-the-art agents. It is the first tree search algorithm for LM agents that shows effectiveness on realistic web tasks. On the challenging VisualWebArena benchmark, applying our search algorithm on top of a GPT-4o agent yields a 39.7% relative increase in success rate compared to the same baseline without search, setting a state-of-the-art success rate of 26.4%. On WebArena, search also yields a 28.0% relative improvement over a baseline agent, setting a competitive success rate of 19.2%. Our experiments highlight the effectiveness of search for web agents, and we demonstrate that performance scales with increased test-time compute. We conduct a thorough analysis of our results to highlight improvements from search, limitations, and promising directions for future work. Our code and models are publicly released at https://jykoh.com/search-agents.
이쪽도 트리 서치. 웹 에이전트에 트리 서치를 결합했네요.
#search #agent
RegMix: Data Mixture as Regression for Language Model Pre-training
(Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, Min Lin)

The data mixture for large language model pre-training significantly impacts performance, yet how to determine an effective mixture remains unclear. We propose RegMix to automatically identify a high-performing data mixture by formulating it as a regression task. RegMix involves training a set of small models with diverse data mixtures and fitting a regression model to predict their performance given their respective mixtures. With the fitted regression model, we simulate the top-ranked mixture and use it to train a large-scale model with orders of magnitude more compute. To empirically validate RegMix, we train 512 models with 1M parameters for 1B tokens of different mixtures to fit the regression model and find the optimal mixture. Using this mixture we train a 1B parameter model for 25B tokens (i.e. 1000x larger and 25x longer) which we find performs best among 64 candidate 1B parameter models with other mixtures. Further, our method demonstrates superior performance compared to human selection and achieves results that match or surpass DoReMi, while utilizing only 10% of the compute budget. Our experiments also show that (1) Data mixtures significantly impact performance with single-task performance variations of up to 14.6%; (2) Web corpora rather than data perceived as high-quality like Wikipedia have the strongest positive correlation with downstream performance; (3) Domains interact in complex ways often contradicting common sense, thus automatic approaches like RegMix are needed; (4) Data mixture effects transcend scaling laws, and our approach captures the complexity by considering all domains together. Our code is available at https://github.com/sail-sg/regmix.
프리트레이닝 코퍼스의 비율을 결정하는 아주 심플한 방법. 여러 가지 비율을 통해 학습한 다음 학습 비율과 타겟 도메인에 대한 스코어에 대한 Regression을 합니다. 이 Regressor로 최고 스코어의 비율을 찾아 학습한다는 아이디어입니다.
데이터 학습량 증가에 따른 변화를 포착하기 어려울 것이라는 점은 한계일 수 있겠네요.
#scaling-law #corpus #pretraining
Advancing Process Verification for Large Language Models via Tree-Based Preference Learning
(Mingqian He, Yongliang Shen, Wenqi Zhang, Zeqi Tan, Weiming Lu)

Large Language Models (LLMs) have demonstrated remarkable potential in handling complex reasoning tasks by generating step-by-step rationales.Some methods have proven effective in boosting accuracy by introducing extra verifiers to assess these paths. However, existing verifiers, typically trained on binary-labeled reasoning paths, fail to fully utilize the relative merits of intermediate steps, thereby limiting the effectiveness of the feedback provided. To overcome this limitation, we propose Tree-based Preference Learning Verifier (Tree-PLV), a novel approach that constructs reasoning trees via a best-first search algorithm and collects step-level paired data for preference training. Compared to traditional binary classification, step-level preferences more finely capture the nuances between reasoning steps, allowing for a more precise evaluation of the complete reasoning path. We empirically evaluate Tree-PLV across a range of arithmetic and commonsense reasoning tasks, where it significantly outperforms existing benchmarks. For instance, Tree-PLV achieved substantial performance gains over the Mistral-7B self-consistency baseline on GSM8K (67.55% to 82.79%), MATH (17.00% to 26.80%), CSQA (68.14% to 72.97%), and StrategyQA (82.86% to 83.25%).Additionally, our study explores the appropriate granularity for applying preference learning, revealing that step-level guidance provides feedback that better aligns with the evaluation of the reasoning process.
트리 서치 결과를 사용해 Reward Model을 학습. 트리 서치와 관련된 결과들은 정말 많이 나오고 있습니다.
#search
Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
(Philippe Laban, Alexander R. Fabbri, Caiming Xiong, Chien-Sheng Wu)

LLMs and RAG systems are now capable of handling millions of input tokens or more. However, evaluating the output quality of such systems on long-context tasks remains challenging, as tasks like Needle-in-a-Haystack lack complexity. In this work, we argue that summarization can play a central role in such evaluation. We design a procedure to synthesize Haystacks of documents, ensuring that specific \textit{insights} repeat across documents. The "Summary of a Haystack" (SummHay) task then requires a system to process the Haystack and generate, given a query, a summary that identifies the relevant insights and precisely cites the source documents. Since we have precise knowledge of what insights should appear in a haystack summary and what documents should be cited, we implement a highly reproducible automatic evaluation that can score summaries on two aspects - Coverage and Citation. We generate Haystacks in two domains (conversation, news), and perform a large-scale evaluation of 10 LLMs and corresponding 50 RAG systems. Our findings indicate that SummHay is an open challenge for current systems, as even systems provided with an Oracle signal of document relevance lag our estimate of human performance (56%) by 10+ points on a Joint Score. Without a retriever, long-context LLMs like GPT-4o and Claude 3 Opus score below 20% on SummHay. We show SummHay can also be used to study enterprise RAG systems and position bias in long-context models. We hope future systems can equal and surpass human performance on SummHay.
쿼리와 컨텍스트, Haystack이 주어졌을 때 주어진 정보를 통해 관련된 컨텍스트를 찾아 요약하고 적절하게 인용하는 능력을 점검하는 벤치마크. 사실 이 과제는 벤치마크 이상으로 RAG 측면에서 그 자체로 가치가 높은 과제라고 할 수 있겠네요. Cohere 모델들이 이런 능력을 탑재하고 있죠.
#benchmark #long-context
Look Ahead or Look Around? A Theoretical Comparison Between Autoregressive and Masked Pretraining
(Qi Zhang, Tianqi Du, Haotian Huang, Yifei Wang, Yisen Wang)

In recent years, the rise of generative self-supervised learning (SSL) paradigms has exhibited impressive performance across visual, language, and multi-modal domains. While the varied designs of generative SSL objectives lead to distinct properties in downstream tasks, a theoretical understanding of these differences remains largely unexplored. In this paper, we establish the first theoretical comparisons between two leading generative SSL paradigms: autoregressive SSL and masked SSL. Through establishing theoretical frameworks, we elucidate the strengths and limitations of autoregressive and masked SSL within the primary evaluation tasks of classification and content generation. Our findings demonstrate that in classification tasks, the flexibility of targeted tokens in masked SSL fosters more inter-sample connections compared to the fixed position of target tokens in autoregressive SSL, which yields superior clustering performance. In content generation tasks, the misalignment between the flexible lengths of test samples and the fixed length of unmasked texts in masked SSL (vs. flexible lengths of conditional texts in autoregressive SSL) hinders its generation performance. To leverage each other's strengths and mitigate weaknesses, we propose diversity-enhanced autoregressive and variable-length masked objectives, which substantially improve the classification performance of autoregressive SSL and the generation performance of masked SSL. Code is available at https://github.com/PKU-ML/LookAheadLookAround.
Causal LM과 MLM Objective를 컨텍스트 토큰과 타겟 토큰의 Co-occurrence 행렬의 관점에서 분석. 이 행렬의 연결성이 MLM에서 더 높기 때문에 분류 과제 등에 대해 더 나은 성능을 나타낸다는 분석. 반대로 Causal LM이 생성 능력이 좋은 이유에 대한 분석도 있습니다. (학습과 테스트 시점의 길이 차이나 토큰의 위치에 따른 예측 변화 문제 등.)
이 문제에 대한 대응으로 Causal LM과 MLM Objective를 개선하는데 Causal LM에서는 Multi Token Prediction, MLM에서는 Prefix LM이나 Masked Diffusion 같은 형태의 마스크 비율을 다양화 하는 방식을 사용했습니다.
분류 과제 등에 대한 적용을 염두에 둔 것이긴 하지만 여러 토큰 예측 과제가 등장했다는 것이 흥미롭네요. (https://arxiv.org/abs/2403.06963, https://arxiv.org/abs/2404.19737) 추론 속도 가속에도 사용할 수 있으니 (https://arxiv.org/abs/2401.10774) 실험해보면 재미있는 접근일 것 같습니다.
#pretraining #self-supervision