



Rule Based Rewards for Language Model Safety
(Tong Mu, Alec Helyar, Johannes Heidecke, Joshua Achiam, Andrea Vallone, Ian Kivlichan, Molly Lin, Alex Beutel, John Schulman, Lilian Weng)

Rule Based Rewards, RBR. 이것이 GPT-4 리포트에 언급됐던 RBRM의 실체가 아닌가 싶네요.
기본적으로는 Constitutional AI 같은 RLAIF 기반 Safety Alignment를 하려고 하는데, Constitutional AI의 굉장히 고수준의 Constitution이 (Harmful 하지 않을 것) 지나치게 해석의 여지가 넓다는 이야기를 합니다. 그래서 Yes/No 응답이 가능한 단순한 Proposition들을 사용합니다.
그리고 각 컨텐츠 카테고리와 (Erotic, Hate Speech 등) 상황에 따라 답해야 할 방식들이 존재합니다. (Hard Refusal, Soft Refusal, Comply) 그리고 이 각각의 방식에 대해서 더 나은 응답이 따라야 할 Proposition들이 규칙으로 존재합니다.
이 Proposition들과 Proposition의 그룹에 대한 분류 확률을 결합해 순위 함수를 학습시키고 이 순위 함수를 Safety Reward로 결합하는 방식이네요.
실용적으로 Content Policy와 그것을 어떻게 따라야 하는지를 아주 구체적으로 지정하려고 하는 방법이라고 할 수 있겠네요. 물론 Anthropic 스타일의 인류를 위해 최선을 다하라 같은 원칙이 좀 더 낭만적인 것 같긴 하지만요.
#safety #alignment #rlaif
PyTorch 2.4 Release Blog
(Team PyTorch)

파이토치 2.4가 나왔군요. 관심이 가는 것은 FSDP2와 Pipeline Parallel의 추가네요. Pipeline Parallel에서 FlexibleInterleaved1F1B라는 스케줄이 있는데 이쪽이 Llama 3 논문에서 언급한 마이크로배치의 숫자를 유연화한 스케줄이 아닌가 싶습니다. 거기에 Zero Bubble Pipeline Parallel도 지원하는군요.
프레임워크 없이 파이토치만으로 4D Parallel을 구현해보는 것도 재미있을 것 같습니다.
#framework
u-μP: The Unit-Scaled Maximal Update Parametrization
(Charlie Blake, Constantin Eichenberg, Josef Dean, Lukas Balles, Luke Y. Prince, Björn Deiseroth, Andres Felipe Cruz-Salinas, Carlo Luschi, Samuel Weinbach, Douglas Orr)
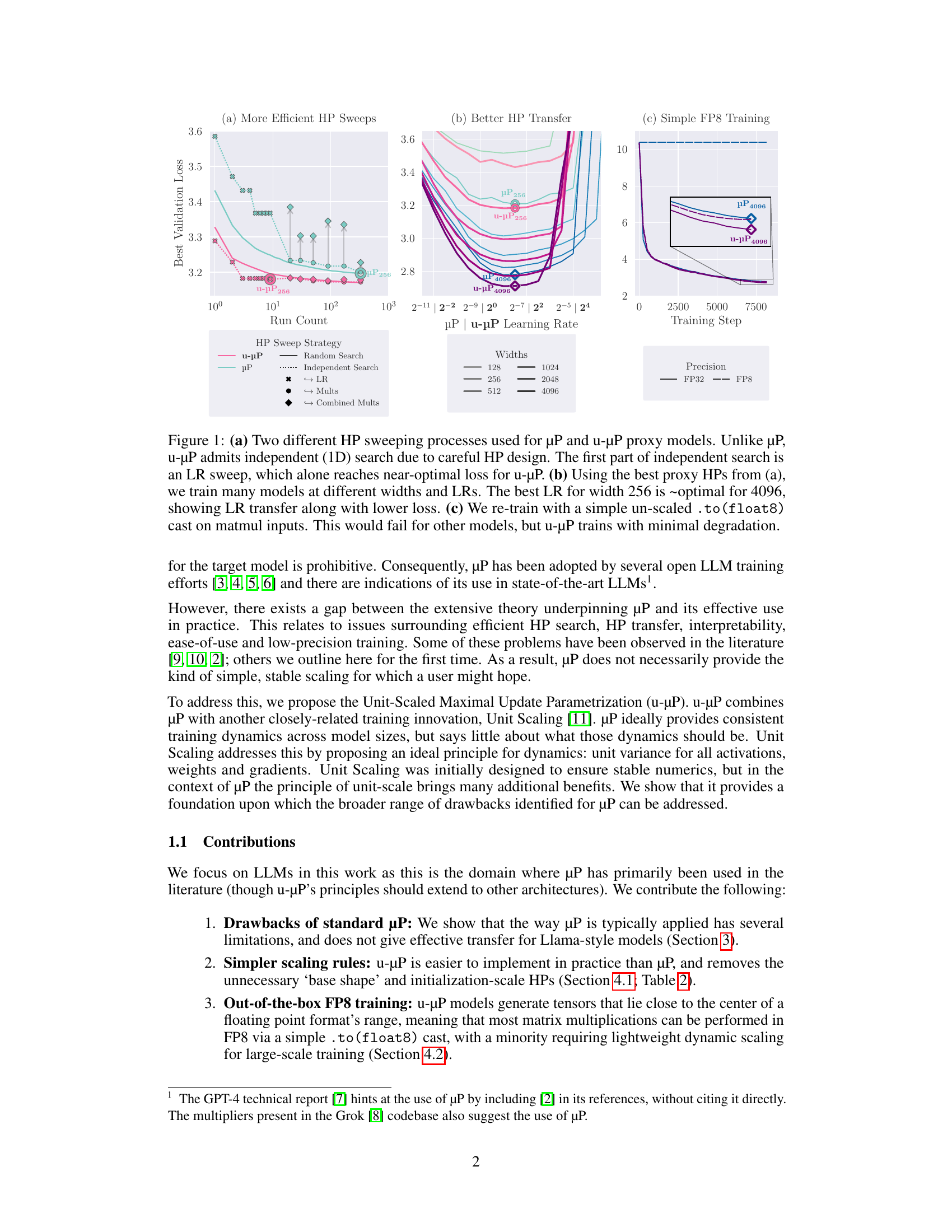
The Maximal Update Parametrization (μP) aims to make the optimal hyperparameters (HPs) of a model independent of its size, allowing them to be swept using a cheap proxy model rather than the full-size target model. We present a new scheme, u-μP, which improves upon μP by combining it with Unit Scaling, a method for designing models that makes them easy to train in low-precision. The two techniques have a natural affinity: μP ensures that the scale of activations is independent of model size, and Unit Scaling ensures that activations, weights and gradients begin training with a scale of one. This synthesis opens the door to a simpler scheme, whose default values are near-optimal. This in turn facilitates a more efficient sweeping strategy, with u-μP models reaching a lower loss than comparable μP models and working out-of-the-box in FP8.
Graphcore의 μP 개선. Unit Scaling이라는 (https://arxiv.org/abs/2303.11257) Low Precision을 위한 테크닉을 결합하면서 탐색할 하이퍼파라미터를 줄이고 하이퍼파라미터가 더 잘 Transfer 되도록 개선했다고 합니다. 그런데 Graphcore지만 실험은 A100/H100으로 했네요.
#hyperparameter
LEAN-GitHub: Compiling GitHub LEAN repositories for a versatile LEAN prover
(Zijian Wu, Jiayu Wang, Dahua Lin, Kai Chen)

Recently, large language models have presented promising results in aiding formal mathematical reasoning. However, their performance is restricted due to the scarcity of formal theorem-proving data, which requires additional effort to be extracted from raw formal language corpora. Meanwhile, a significant amount of human-written formal language corpora remains underutilized. To address this issue, we propose LEAN-GitHub, a dataset consisting of large-scale formal data extracted from almost all Lean 4 repositories on GitHub. After fine-tuning InternLM-math-plus on this dataset, our model achieved accuracies of 48.8% with a single pass and 54.5% with 64 passes on the Lean 4 miniF2F test, surpassing state-of-the-art method at 52%. And it also achieves state-of-the-art on two other Lean 4 benchmarks (ProofNet and Putnam) targeting different fields/levels of math. These results demonstrate that our proposed dataset is beneficial for formal reasoning on a wide range of math topics. We open-source our model at
https://GitHub
. com/InternLM/InternLM-Math and our data at
https://huggingface.co/
datasets/InternLM/Lean-GitHub
Lean 4 코드를 정리해 만든 데이터셋이군요. 놀라울 정도로 이 문제에 대한 관심이 집중되고 있네요.
#corpus #math
INF’s Open-Source Large Language Models
(INF-Team)

This technical report is a companion document to our white paper “Towards Trustworthy Large Language Models in Industry Domains” [1], and complements the full stack technology of large language models. We release a large language model to the open source community, named INF-34B, under an INF license that is friendly to research and commercial use. INF-34B has 34 billion parameters with a context window length of 32K and is trained on about 3.5T well-processed tokens from our curated English and Chinese bilingual corpus. In the report we present training details and report the results of model evaluation on widely used benchmarks. Compared with open-source models of comparable size, INF-34B not only provides competitive performance in the OpenCompass evaluation, but also has impressive potential in both the finance and healthcare domains. In addition to its outstanding comprehensive capacities, the quantized INF-34B runs on low-resource graphics cards with negligible accuracy loss, which helps it be suitable for low-resource applications.
INF-34B라는 3.5T 학습 모델의 리포트입니다. 데이터셋 구축 과정에 대해서 상당히 상세하네요. DeepSeekMath/DeepSeek Coder V2 스타일의 코드, 수학 데이터 수집은 이제 거의 표준이군요. 추가로 위키 유사 데이터도 수집했습니다.
Instruction 데이터를 적극적으로 사용해서 벤치마크 스코어는 과대평가가 있을 듯 합니다. 다만 이 문제에 대해서 어차피 SFT 단계에서 사용할 것이라면 프리트레이닝에 쓰는 쪽이 낫지 않은가 하는 이야기를 하네요. 저도 이쪽이 다루기는 편할 것 같습니다.
FP8 학습도 했는데 불안정성 때문에 BF16과 전환이 가능하도록 했네요.
#llm
CMR Scaling Law: Predicting Critical Mixture Ratios for Continual Pre-training of Language Models
(Jiawei Gu, Zacc Yang, Chuanghao Ding, Rui Zhao, Fei Tan)

Large Language Models (LLMs) excel in diverse tasks but often underperform in specialized fields due to limited domain-specific or proprietary corpus. Continual pre-training (CPT) enhances LLM capabilities by imbuing new domain-specific or proprietary knowledge while replaying general corpus to prevent catastrophic forgetting. The data mixture ratio of general corpus and domain-specific corpus, however, has been chosen heuristically, leading to sub-optimal training efficiency in practice. In this context, we attempt to re-visit the scaling behavior of LLMs under the hood of CPT, and discover a power-law relationship between loss, mixture ratio, and training tokens scale. We formalize the trade-off between general and domain-specific capabilities, leading to a well-defined Critical Mixture Ratio (CMR) of general and domain data. By striking the balance, CMR maintains the model's general ability and achieves the desired domain transfer, ensuring the highest utilization of available resources. Therefore, if we value the balance between efficiency and effectiveness, CMR can be consider as the optimal mixture ratio.Through extensive experiments, we ascertain the predictability of CMR, and propose CMR scaling law and have substantiated its generalization. These findings offer practical guidelines for optimizing LLM training in specialized domains, ensuring both general and domain-specific performance while efficiently managing training resources.
Continual Pretraining 상황에서 주어진 학습량과 모델 크기에 대해서 원 도메인에 대한 Loss의 감소를 최소화하면서 새로운 도메인에 대한 성능 향상을 최대화하는 원 도메인 데이터와 새로운 도메인 데이터의 비율을 추정할 수 있는가 하는 문제.
#continual-learning #pretraining #scaling-law