



2024년 6월 3일

FineWeb: decanting the web for the finest text data at scale
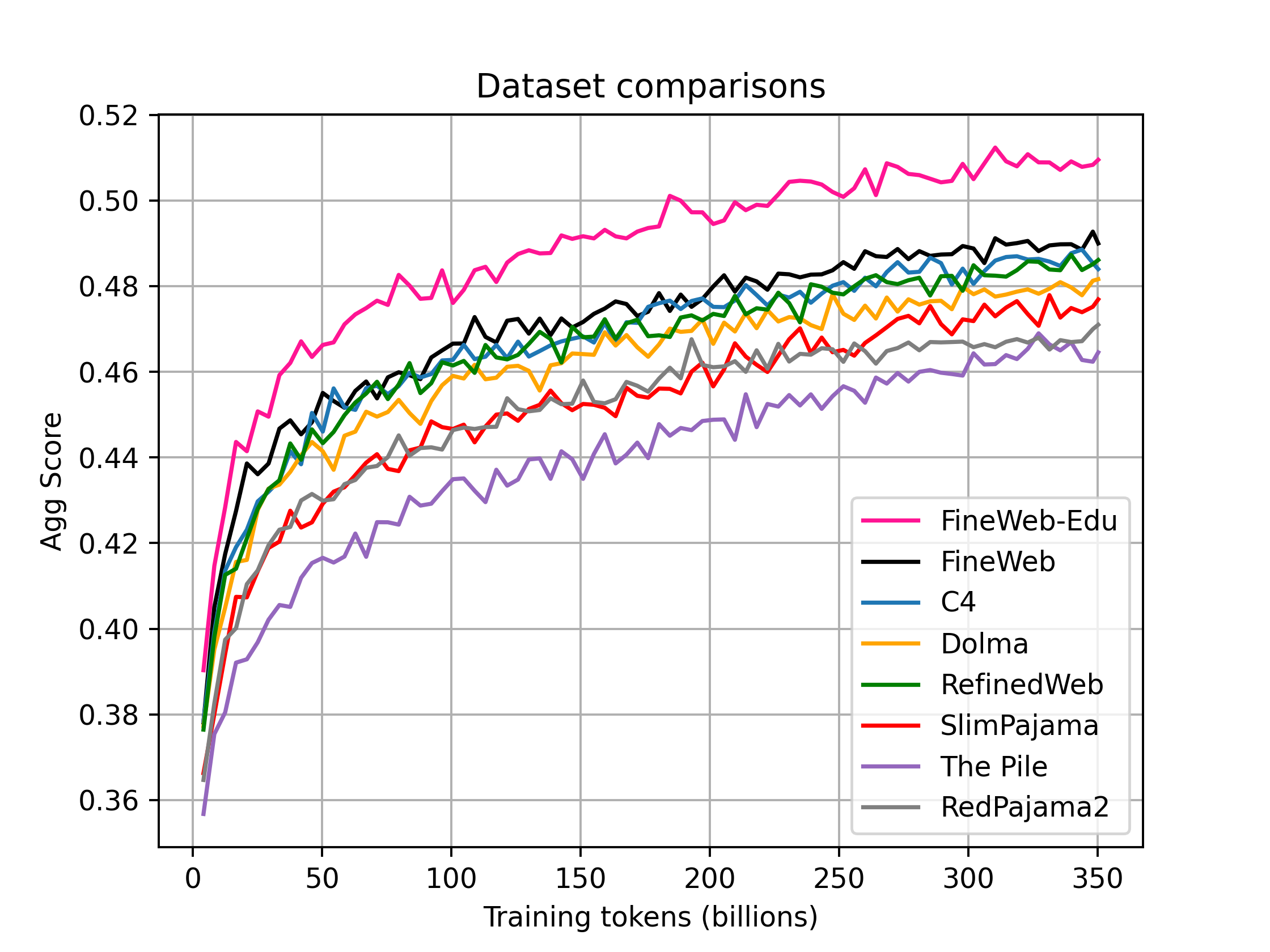
FineWeb 코퍼스의 구축 과정에 대한 테크니컬 리포트가 나왔습니다. 추가로 FineWeb-Edu라는 코퍼스도 소개하고 있는데 Llama 3 기반으로 퀄리티 분류기를 만들어 필터링한 서브셋입니다.
굉장히 흥미로운 결과들이 많습니다. 데이터 구축에 대한 경험을 이미 많이 축적한 사람들이 아니라면 중요하게 참고할 수 있는 자료들이 되겠네요.
중요한 것은 더 해볼 만한 것들이 여전히 남아 있다는 것이라고 봅니다. Text Extraction 과정에서 의미 있는 태그들을 남겨 포매팅을 개선하는 것도 고려해볼 수 있습니다. C4 Filtering은 Javascript가 포함되거나 Curly Bracket ({)이 포함된 라인들을 제거하는데 이 부분을 고려해 수학이나 코딩 관련 문서를 따로 수집하는 것도 생각해볼 수 있죠. (https://arxiv.org/abs/2310.06786, https://arxiv.org/abs/2402.03300) 클러스터링을 사용한 데이터셋의 밸런싱도 선택지입니다. (https://arxiv.org/abs/2405.15613)
웹은 광대하고 웹에 대해 할 수 있는 것은 여전히 많습니다.
그러나 웹에 국한될 필요도 없고 그래서도 안 된다고 봅니다. 예를 들어 PDF 문서들. 웹 데이터를 잘 정제하는 것과 마찬가지로 각종 문서들에서 텍스트를 추출하고 잘 정제하는 파이프라인을 구축하는 것도 필요하겠죠.
좋은 LLM을 만드는 것에 이것만으로는 충분하지 않을 수도 있습니다. 그렇지만 이것이 LLM의 선두 주자들이 갖춘 기본 조건이라는 것은 분명하지 않을까요.
이미지넷 프리트레이닝 - COCO 파인튜닝 같은 동일한 세팅에서 동일한 데이터셋을 사용해 겨루는 것이 미덕이었던 시대가 순식간에 지나가고 지금은 유용한 데이터셋을 발굴해 사용하는 것이 미덕인 시대가 되었습니다.
#dataset
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality
(Tri Dao, Albert Gu)

While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transformers at small to medium scale. We show that these families of models are actually quite closely related, and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices. Our state space duality (SSD) framework allows us to design a new architecture (Mamba-2) whose core layer is an a refinement of Mamba's selective SSM that is 2-8X faster, while continuing to be competitive with Transformers on language modeling.
State Space Model들을 (L◦QK^T)V 형태로 생각했을 때 L 행렬에 부여하는 구조에 따라 Linear Attention, Retentive Network 등등 다양한 모델들이 유도된다는 아이디어. 여기서는 1-Semiseparable이라는 구조를 고려합니다.
이를 통해 얻을 수 있는 것은 State Space Model과 Attention을 하나로 연결해 계산 과정에서 일부는 Attention 형태로 계산하고 부분적으로 Recurrent하게 계산하는 방식으로 연산 효율성을 높일 수 있다는 것이네요. 기존의 Mamba와 비슷하거나 더 나은 성능을 확보하면서 Long Context에 대해 더 빠른 연산이 가능합니다.
#state-space-model