

2024년 6월 18일

Autoregressive Image Generation without Vector Quantization
(Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, Kaiming He)

Conventional wisdom holds that autoregressive models for image generation are typically accompanied by vector-quantized tokens. We observe that while a discrete-valued space can facilitate representing a categorical distribution, it is not a necessity for autoregressive modeling. In this work, we propose to model the per-token probability distribution using a diffusion procedure, which allows us to apply autoregressive models in a continuous-valued space. Rather than using categorical cross-entropy loss, we define a Diffusion Loss function to model the per-token probability. This approach eliminates the need for discrete-valued tokenizers. We evaluate its effectiveness across a wide range of cases, including standard autoregressive models and generalized masked autoregressive (MAR) variants. By removing vector quantization, our image generator achieves strong results while enjoying the speed advantage of sequence modeling. We hope this work will motivate the use of autoregressive generation in other continuous-valued domains and applications.
Autoregressive 모델에서 Latent를 생성한 다음 이 Latent에 Conditional한 Diffusion Process를 사용해서 생성하는 모델. DARL과 비슷한 점이 있군요. (https://arxiv.org/abs/2403.05196) 추가적으로 Masked Image Modeling을 Mask 토큰을 예측하는 것을 반복하는 Autoregressive 모델로 보고 사용했습니다. VQ 대신 VAE와 연결할 수 있는 가능성 등에서 상당히 흥미롭네요.
#autoregressive-model #diffusion
DataComp-LM: In search of the next generation of training sets for language models
(Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muenninghoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldani, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G. Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, Vaishaal Shankar)

We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Common Crawl 기반 데이터셋. Resiliparse를 사용한 Text Extraction, RefinedWeb 스타일의 휴리스틱 기반 필터링, 블룸 필터를 사용한 Deduplication, fastText + Instruction 데이터셋과 ELI5 서브레딧을 사용한 퀄리티 필터링 등. 결과적으로 3.8T 토큰 데이터셋이 남습니다.
여전히 Global Deduplication 같은 문제가 남아있긴 합니다만 Common Crawl을 어떻게 다뤄야 하는가에 대한 정보가 훨씬 많이 공개되긴 했네요.
#dataset #corpus
Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%
(Lei Zhu, Fangyun Wei, Yanye Lu, Dong Chen)
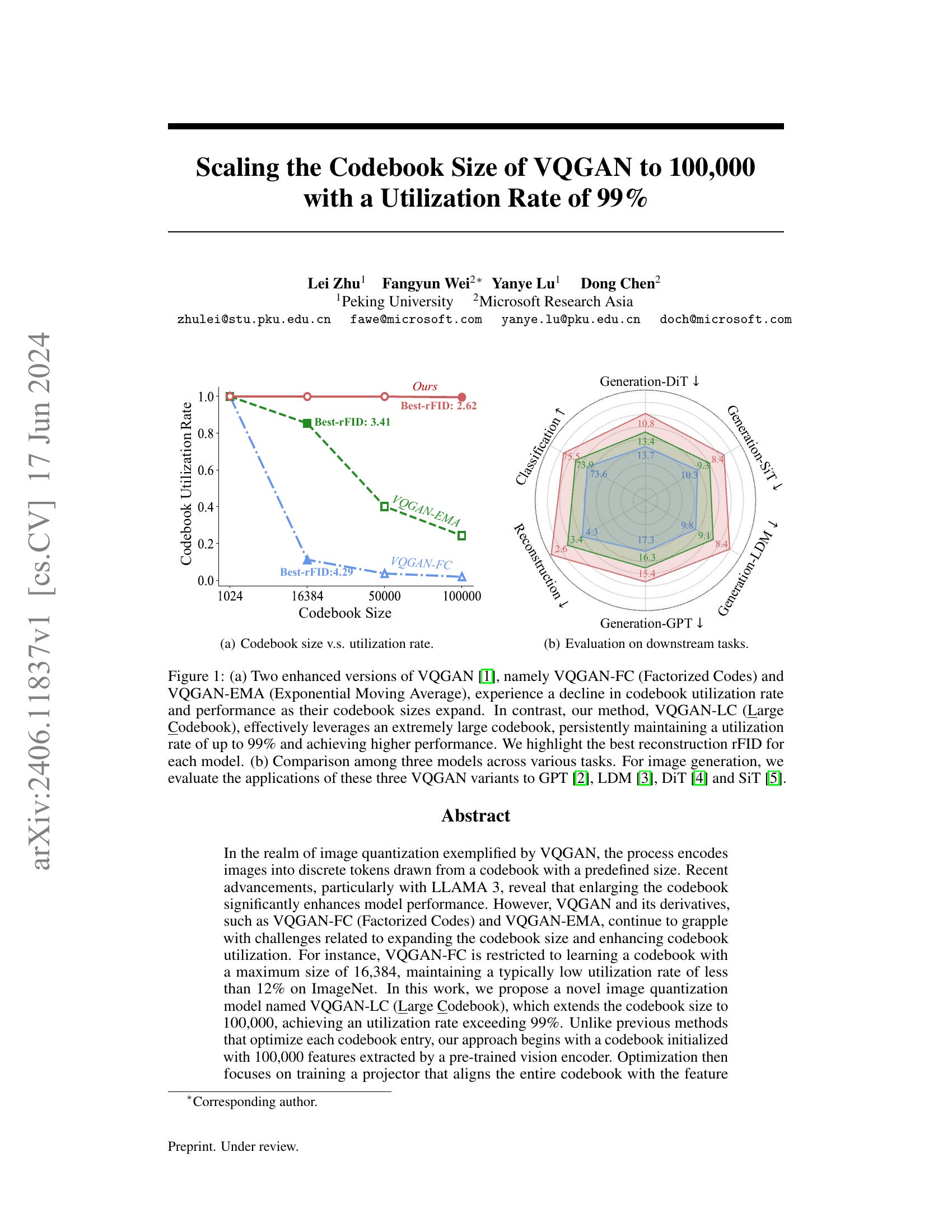
In the realm of image quantization exemplified by VQGAN, the process encodes images into discrete tokens drawn from a codebook with a predefined size. Recent advancements, particularly with LLAMA 3, reveal that enlarging the codebook significantly enhances model performance. However, VQGAN and its derivatives, such as VQGAN-FC (Factorized Codes) and VQGAN-EMA, continue to grapple with challenges related to expanding the codebook size and enhancing codebook utilization. For instance, VQGAN-FC is restricted to learning a codebook with a maximum size of 16,384, maintaining a typically low utilization rate of less than 12% on ImageNet. In this work, we propose a novel image quantization model named VQGAN-LC (Large Codebook), which extends the codebook size to 100,000, achieving an utilization rate exceeding 99%. Unlike previous methods that optimize each codebook entry, our approach begins with a codebook initialized with 100,000 features extracted by a pre-trained vision encoder. Optimization then focuses on training a projector that aligns the entire codebook with the feature distributions of the encoder in VQGAN-LC. We demonstrate the superior performance of our model over its counterparts across a variety of tasks, including image reconstruction, image classification, auto-regressive image generation using GPT, and image creation with diffusion- and flow-based generative models. Code and models are available at https://github.com/zh460045050/VQGAN-LC.
프리트레이닝 이미지 인코더에서 추출한 Feature에 대해 클러스터링을 사용해 코드북을 만들고, 이 코드북을 고정해놓은 다음 코드북에 대한 Projection으로 Quantization을 사용해 VQVAE를 학습한 방법. FSQ 같은 방법과 비교해볼 수 있으면 재미있을 것 같네요.
#vq
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
(Anas Awadalla, Le Xue, Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, Caiming Xiong, Ran Xu, Yejin Choi, Ludwig Schmidt)

Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.
Common Crawl과 Common Crawl에서 발굴한 PDF 기반 Interleaved 데이터셋. PDF를 커버했다는 것은 좋은 부분이네요. Common Crawl은 OBELICS를 사용했고 PDF는 PDF 내의 텍스트를 추출했군요. 다만 Reading order 같은 부분들이 (휴리스틱 기반이라) 얼마나 잘 커버되었을지는 궁금하긴 합니다.
#dataset #corpus #vision-language
Unveiling Encoder-Free Vision-Language Models
(Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, Xinlong Wang)

Existing vision-language models (VLMs) mostly rely on vision encoders to extract visual features followed by large language models (LLMs) for visual-language tasks. However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs. Training pure VLMs that accept the seamless vision and language inputs, i.e., without vision encoders, remains challenging and rarely explored. Empirical observations reveal that direct training without encoders results in slow convergence and large performance gaps. In this work, we bridge the gap between encoder-based and encoder-free models, and present a simple yet effective training recipe towards pure VLMs. Specifically, we unveil the key aspects of training encoder-free VLMs efficiently via thorough experiments: (1) Bridging vision-language representation inside one unified decoder; (2) Enhancing visual recognition capability via extra supervision. With these strategies, we launch EVE, an encoder-free vision-language model that can be trained and forwarded efficiently. Notably, solely utilizing 35M publicly accessible data, EVE can impressively rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks. It significantly outperforms the counterpart Fuyu-8B with mysterious training procedures and undisclosed training data. We believe that EVE provides a transparent and efficient route for developing a pure decoder-only architecture across modalities. Our code and models are publicly available at: https://github.com/baaivision/EVE.
비전 인코더 없는 Vision-Language 모델. 다만 패치 임베딩의 앞뒤로 이런저런 모듈이 많이 붙긴 했네요. 비전 인코더를 사용해서 패치 토큰에 대한 출력에 추가적인 Loss를 사용하기도 했습니다.
#vision-language
STAR: Scale-wise Text-to-image generation via Auto-Regressive representations
(Xiaoxiao Ma, Mohan Zhou, Tao Liang, Yalong Bai, Tiejun Zhao, Huaian Chen, Yi Jin)

We present STAR, a text-to-image model that employs scale-wise auto-regressive paradigm. Unlike VAR, which is limited to class-conditioned synthesis within a fixed set of predetermined categories, our STAR enables text-driven open-set generation through three key designs: To boost diversity and generalizability with unseen combinations of objects and concepts, we introduce a pre-trained text encoder to extract representations for textual constraints, which we then use as guidance. To improve the interactions between generated images and fine-grained textual guidance, making results more controllable, additional cross-attention layers are incorporated at each scale. Given the natural structure correlation across different scales, we leverage 2D Rotary Positional Encoding (RoPE) and tweak it into a normalized version. This ensures consistent interpretation of relative positions across token maps at different scales and stabilizes the training process. Extensive experiments demonstrate that STAR surpasses existing benchmarks in terms of fidelity,image text consistency, and aesthetic quality. Our findings emphasize the potential of auto-regressive methods in the field of high-quality image synthesis, offering promising new directions for the T2I field currently dominated by diffusion methods.
VAR (https://arxiv.org/abs/2404.02905) 스타일의 Multiscale Autoregressive 생성을 Text to Image에 적용한 사례가 벌써 나왔군요.
#text-to-image #autoregressive-model
Nemotron-4 340B Technical Report
(Nvidia: Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H. Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, Sirshak Das, Ayush Dattagupta, Olivier Delalleau, Leon Derczynski, Yi Dong, Daniel Egert, Ellie Evans, Aleksander Ficek, Denys Fridman, Shaona Ghosh, Boris Ginsburg, Igor Gitman, Tomasz Grzegorzek, Robert Hero, Jining Huang, Vibhu Jawa, Joseph Jennings, Aastha Jhunjhunwala, John Kamalu, Sadaf Khan, Oleksii Kuchaiev, Patrick LeGresley, Hui Li, Jiwei Liu, Zihan Liu, Eileen Long, Ameya Sunil Mahabaleshwarkar, Somshubra Majumdar, James Maki, Miguel Martinez, Maer Rodrigues de Melo, Ivan Moshkov, Deepak Narayanan, Sean Narenthiran, Jesus Navarro, Phong Nguyen, Osvald Nitski, Vahid Noroozi, Guruprasad Nutheti, Christopher Parisien, Jupinder Parmar, Mostofa Patwary, Krzysztof Pawelec, Wei Ping, Shrimai Prabhumoye, Rajarshi Roy, Trisha Saar, Vasanth Rao Naik Sabavat, Sanjeev Satheesh, Jane Polak Scowcroft, Jason Sewall, Pavel Shamis, Gerald Shen, Mohammad Shoeybi, Dave Sizer, Misha Smelyanskiy, Felipe Soares, Makesh Narsimhan Sreedhar, Dan Su, Sandeep Subramanian, Shengyang Sun, Shubham Toshniwal, Hao Wang, Zhilin Wang, Jiaxuan You, Jiaqi Zeng, Jimmy Zhang, Jing Zhang, Vivienne Zhang, Yian Zhang, Chen Zhu)

We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Nemotron-4 340B 테크니컬 리포트. 많은 사람들이 열광하긴 하던데 저는 340B, 9T 학습이라는 스펙에 부합하는 성능이 맞을까 하는 생각은 있습니다. Nemotron-4 15B (https://arxiv.org/abs/2402.16819) 또한 15B/8T 학습 모델의 성능이 7B 모델들과 비슷하다는 점에서 LLM을 학습하는 레시피 중 놓치고 있는 부분이 있다고 생각하게된 계기 중 하나였습니다. 340B 모델도 좀 비슷한 느낌이 있네요.
정렬 데이터로는 꾸준히 구축해온 HelpSteer2 데이터셋 (https://arxiv.org/abs/2406.08673) 을 사용했네요. 10K 규모의 Preference 데이터인데 어노테이터를 동원해 직접 구축한 데이터라 흥미로운 디테일들이 있습니다.
여기서 흥미로운 것 중 하나는 하나의 샘플을 최소 3명의 어노테이터가 어노테이션 했다는 점입니다. Disagreement가 높은 경우 두 명의 어노테이터를 더 참여시키는 프로세스입니다. Anthropic에서 Harmlessness 평가 데이터셋을 구축하면서 4명의 어노테이터의 합의를 통해 레이블링을 했다고 하는데 (https://arxiv.org/abs/2310.13798) 어쩌면 이런 형태의 어노테이션이 현재 표준일 수 있겠다는 생각이 드네요.
다만 이렇게 구축한 데이터의 양이 많지 않아서 생성 데이터를 많이 사용했습니다. 주로 Mistral-8x7B Instruct와 Nemotron 자체를 사용해서 프롬프트를 생성하고 Preference를 구축했네요. Mistral 모델에 대한 의존성도 없으면 최선이긴 하겠지만 그래도 Permissive License 내에서 해결하려 했다는 점이 좋은 점이 아닐까 싶습니다.
#llm #alignment
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
(Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y. Wu Yukun Li, Huazuo Gao, Shirong Ma, Wangding Zeng, Xiao Bi, Zihui Gu, Hanwei Xu, Damai Dai Kai Dong, Liyue Zhang, Yishi Piao, Zhibin Gou, Zhenda Xie, Zhewen Hao, Bingxuan Wang Junxiao Song, Deli Chen, Xin Xie, Kang Guan, Yuxiang You, Aixin Liu, Qiushi Du, Wenjun Gao Xuan Lu, Qinyu Chen, Yaohui Wang, Chengqi Deng, Jiashi Li, Chenggang Zhao Chong Ruan, Fuli Luo, Wenfeng Liang)

We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek- Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder- V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
DeepSeek의 코드 모델 V2가 나왔군요. DeepSeek V2의 중간 체크포인트를 기반으로 6T를 추가 학습시켜 10.2T 학습 모델을 구축했습니다. 벤치마크 스코어로는 최고 수준의 코드 모델이라고 할 수 있을 듯 하네요.
일단 GitHub을 털어 1T 토큰을 확보하고 DeepSeekMath (https://arxiv.org/abs/2402.03300) 의 접근을 코드에 적용해 164B의 코드 관련 토큰을 확요했고. 추가로 120B였던 수학 관련 데이터를 221B로 확고했습니다.
RL 과정에서 Reward Modeling도 흥미롭네요. 테스트를 사용한 컴파일러 피드백으로 0-1 피드백을 줄 수 있지만 테스트가 충분하지 않을 수 있으므로 이 피드백도 충분하지는 않다고 판단했습니다. 따라서 컴파일러 피드백의 결과로 Reward Model을 학습시키고 이 Reward Model로 RL을 진행했다고 하네요.
#llm
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
(Hoyeon Chang, Jinho Park, Seonghyeon Ye, Sohee Yang, Youngkyung Seo, Du-Seong Chang, Minjoon Seo)

Despite the recent observation that large language models (LLMs) can store substantial factual knowledge, there is a limited understanding of the mechanisms of how they acquire factual knowledge through pretraining. This work addresses this gap by studying how LLMs acquire factual knowledge during pretraining. The findings reveal several important insights into the dynamics of factual knowledge acquisition during pretraining. First, counterintuitively, we observe that pretraining on more data shows no significant improvement in the model's capability to acquire and maintain factual knowledge. Next, there is a power-law relationship between training steps and forgetting of memorization and generalization of factual knowledge, and LLMs trained with duplicated training data exhibit faster forgetting. Third, training LLMs with larger batch sizes can enhance the models' robustness to forgetting. Overall, our observations suggest that factual knowledge acquisition in LLM pretraining occurs by progressively increasing the probability of factual knowledge presented in the pretraining data at each step. However, this increase is diluted by subsequent forgetting. Based on this interpretation, we demonstrate that we can provide plausible explanations for recently observed behaviors of LLMs, such as the poor performance of LLMs on long-tail knowledge and the benefits of deduplicating the pretraining corpus.
LLM은 어떻게 지식을 습득하는가? 특정한 지식이 포함된 텍스트에 대해 학습될 때마다 지식을 조금씩 학습하고, 이것이 누적되면서 지식이 습득된다는 분석입니다. 특정 지식을 학습한 다음 시간이 흐를수록 습득한 지식의 강도가 약해져가죠.
여러모로 생각해볼 여지를 주는 연구네요. 예를 들어 Long Tail 분포의 지식에 대해 학습시키면 꼬리에 있는 지식들은 학습 시점의 간격이 너무 멀기 때문에 제대로 학습되기 어려울 수 있습니다. 그런 의미에서 분포의 머리 부분에서 지나치게 많이 샘플링 되는 것을 막으려는 시도 (https://arxiv.org/abs/2405.15613) 가 의미가 있을 수 있겠네요.
#pretraining